本文提出了 WorldMesh,一种从文本生成可导航多房间 3D 场景的“几何优先”方法。通过将场景解构为 3D 骨架模型(Mesh Scaffold)和基于此锚点的扩散生成,实现了在环境级尺度下保持 3D 一致性的 SOTA 成果。
TL;DR
在 3D 场景生成领域,如何平衡“照片级真实感”与“长程一致性”始终是核心难题。慕尼黑工业大学(TUM)提出的 WorldMesh 给出了新答案:几何优先,外观锚定。它不直接盲目生成像素,而是先给场景搭个“骨架”(Mesh Scaffold),再往骨架上“贴肉”(Conditioned Diffusion),从而实现了真正可导航、多房间、物理一致的大规模 3D 世界合成。
1. 痛点:为什么 LLM 分身乏力,扩散模型画皮难画骨?
目前的 Text-to-3D 方案主要分为两类:
- 自回归视频/图像外扩:如 WorldExplorer,容易产生累积误差,一转弯房间就“塌了”。
- 全景图 lifting:如 DreamScene360,虽然单点视角极佳,但无法处理复杂的遮挡关系和多房间穿梭。
其本质痛点在于:2D 扩散模型缺乏对 3D 显式结构的理解。当你靠近一个物体旋转时,模型不知道物体的背面长什么样,导致物体在视野中发生“诡异蠕动”。
2. WorldMesh 的核心方案:解构与重组
作者将复杂的生成任务拆解为三个步骤,体现了极强的工程直觉:
2.1 自动化骨架构建 (Mesh Scaffold Construction)
不同于前人手动输入 Layout,WorldMesh 让 Claude Opus 扮演架构师。
- 平面图生成:LLM 生成包含墙厚、房高、门窗位置的 JSON。
- 物体填充(Object Instantiation):先生成一张俯视图,利用 SAM-3D-Objects 将识别到的家具实例化为独立的 3D 网格,并放入骨架中。
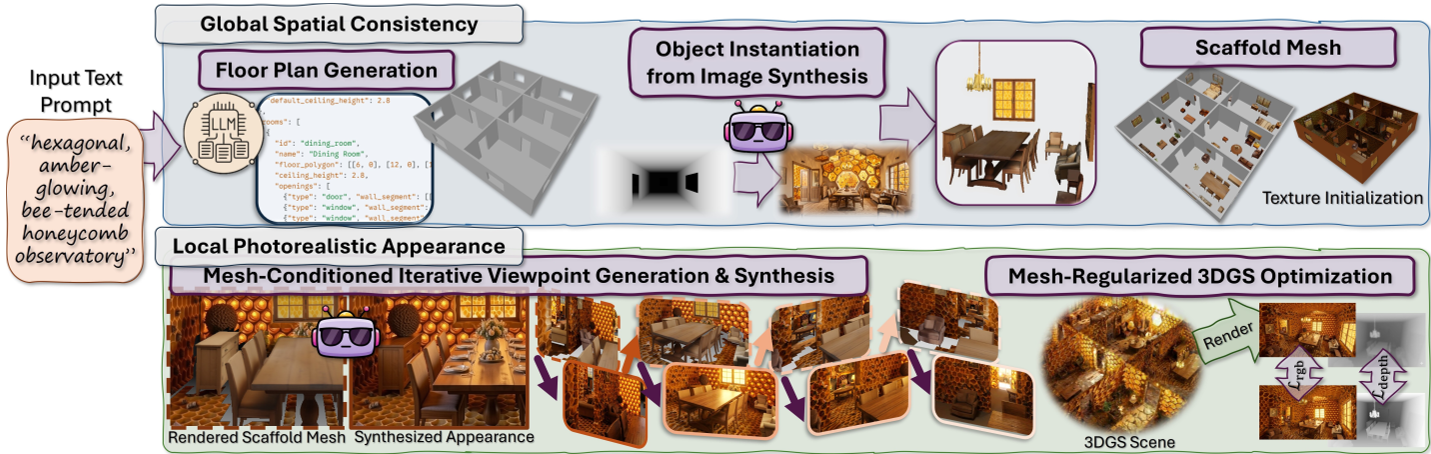
2.2 视图依赖的纹理累积
为了防止光影在不同视角下乱跳,WorldMesh 引入了投影纹理累积(Projective Texture Accumulation)。每生成一个新视角,就将其像素反向投射到 Mesh 表面。后续生成新视图时,模型不仅输入 Depth 信号,还会“参考”之前已经贴上去的纹理残影。
2.3 几何正则化的 Gaussian Splatting
最终的输出不是简单的贴图 Mesh,而是 3DGS。但为了防止 3DGS 在稀疏视角下产生毛刺,作者引入了深度正则化损失: 迫使 Gaussian Splatting 必须紧贴 Mesh 骨架,确保了极高的建筑保真度。
3. 实验表现:不仅是画得漂亮
在对比实验中,WorldMesh 展示了降维打击般的优势。
定性对比
在针对物体近距离旋转的测试中,WorldExplorer 等基线出现了明显的物体形变,而 WorldMesh 因为有显式 Mesh 支撑,物体始终稳如泰山。
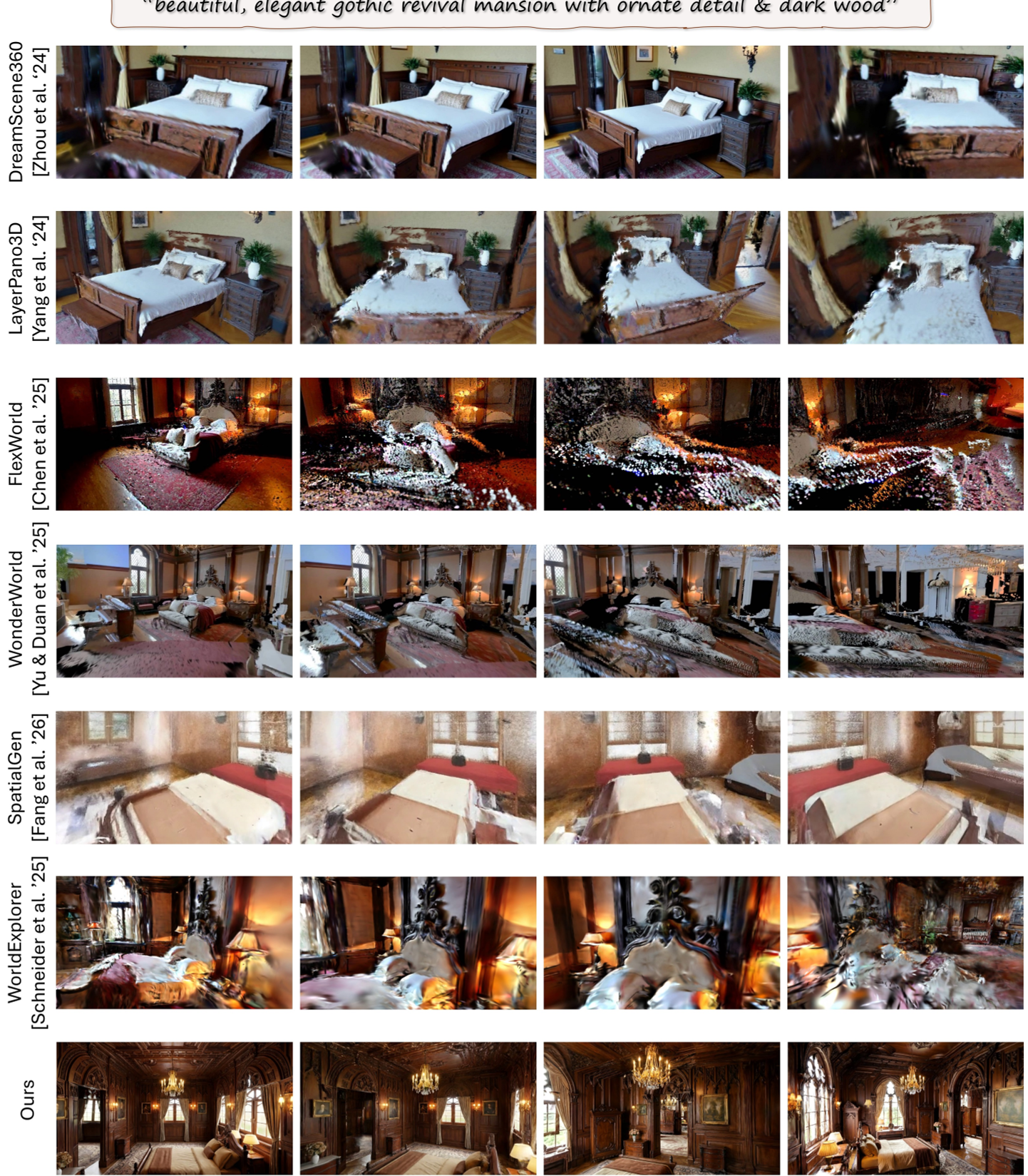
定量战绩
- 用户偏好度:WorldMesh 获得 96.2% 的平均胜率。
- 一致性指标:在 3D Structure 评分上,WorldMesh 高达 4.35(满分 5),而之前的 SOTA 方法如 SpatialGen 仅为 3.00。
4. 深度洞察:为何这篇论文值得读?
WorldMesh 的成功说明了 "Geometry-first"(几何先行) 在复杂场景中的重要性。
- Inductive Bias 的力量:LLM 懂得空间逻辑(墙在哪、门在哪),3D 重建模型懂得几何流形,而扩散模型懂得材质纹理。WorldMesh 成功地将这三种异构能力通过 Mesh 这一通用媒介粘合在了一起。
- 可扩展性:由于它以房间为单位进行处理,且有显式边界控制,理论上它可以生成无限大的连续空间,而不会像单纯的隐式场模型那样遇到显存瓶颈。
局限性:目前仅支持单层建筑(Single-story),且对物体背面的重建依赖于单一模型的补全能力,未来在多层架构和更复杂的遮挡处理上仍有改进空间。
5. 总结 (Conclusion)
WorldMesh 不仅仅是一个 3D 生成算法,它更像是一个自动化 3D 资产工厂流程。它向我们展示了一个极具前景的方向:大模型负责规划,几何模型负责约束,图像模型负责渲染。这种“铁三角”结构,或许正是通往无限生成式虚拟世界的入场券。