X-World is a controllable ego-centric multi-camera world model developed by XPeng, designed to simulate realistic future driving observations in video space. By leveraging a DiT-based latent video generator and rectified flow, it maps history video and future actions to synchronized multi-view 360-degree video streams, achieving SOTA performance in view consistency and action fidelity.
TL;DR
As end-to-end autonomous driving shifts toward Vision-Language-Action (VLA) architectures, the bottleneck has moved from model capacity to evaluation infrastructure. XPeng’s GWM Team introduces X-World, an action-conditioned multi-camera world model. Unlike static log-replays, X-World is a reactive simulator that generates photorealistic, geometrically consistent 360° video futures based on ego-actions and scene-level controls (weather, agents, lanes). It supports streaming, long-horizon (24s+) rollouts, making it an ideal engine for Online Reinforcement Learning.
The Motivation: Moving Beyond Static Log-Replays
Evaluating a VLA model is notoriously difficult. If a policy decides to deviate from the original human driver's path (a counterfactual action), traditional simulators like 3DGS (3D Gaussian Splatting) often fail to render the "unseen" perspectives accurately. Real-world testing is expensive and lacks the safety-critical "long-tail" events needed for robust training.
X-World addresses this by treating the world state as a high-dimensional video stream. The core challenge? Ensuring that a car seen in the front-left camera doesn't "disappear" or "glitch" when it moves into the front-fisheye view.
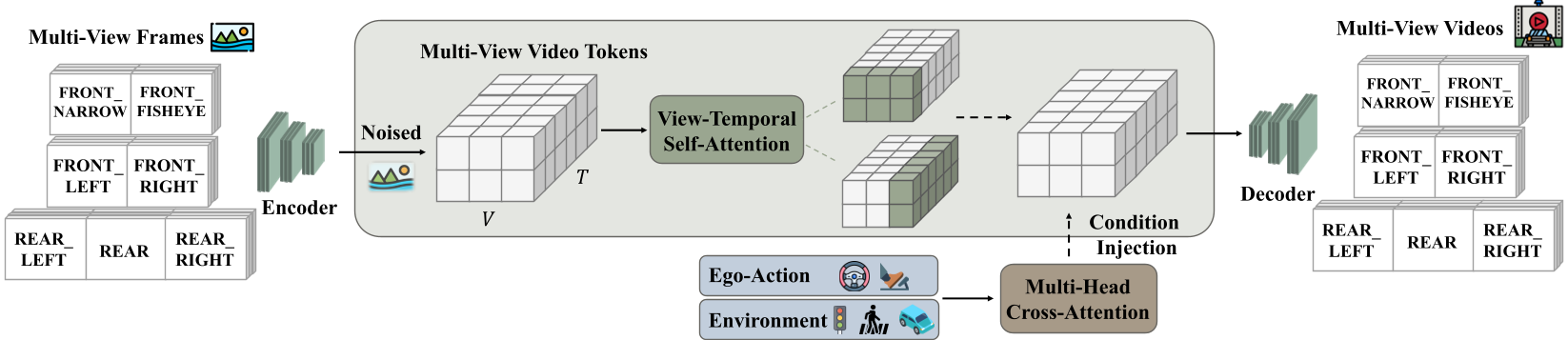
Methodology: Architecture of a World Model
X-World is built on a high-compression 3D Causal VAE (16x spatial, 4x temporal compression) and a Diffusion Transformer (DiT) backbone.
1. View-Temporal Self-Attention
To solve the multi-camera consistency problem, X-World doesn't just generate frames independently. It employs a module that alternates between temporal and cross-view dimensions. This allows latent tokens to "communicate" across synchronized cameras, ensuring that a pedestrian’s identity and position are consistent across the entire 360° rig.
2. Heterogeneous Condition Injection
The model handles a complex blend of inputs through decoupled branches:
- Ego-Actions: Normalized kinematic states (velocity, curvature) injected via adaLN-Zero.
- Dynamic/Static Elements: Bounding boxes and lane topologies encoded with umT5 and Fourier features, injected via Decoupled Cross-Attention to prevent interference between appearance (text) and layout (geometry).
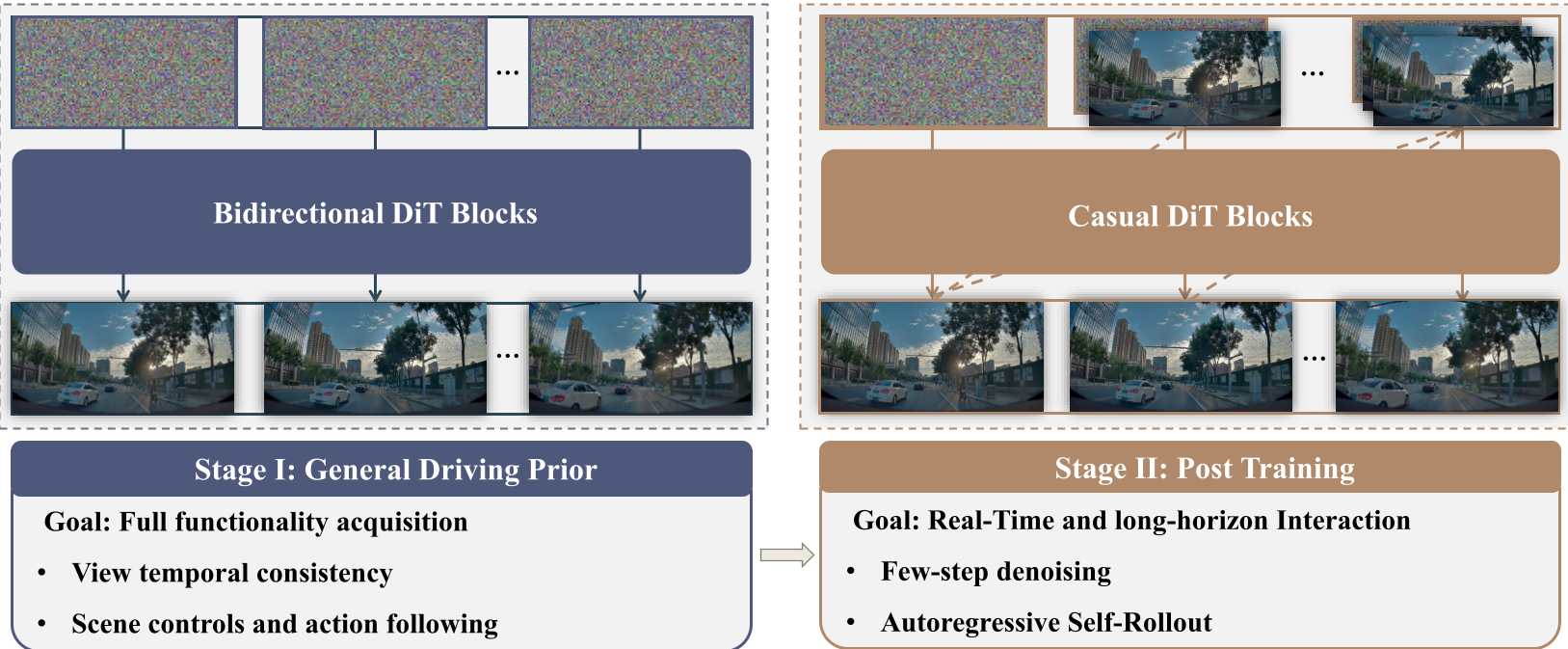
Streaming Simulation: From Bidirectional to Causal
Standard video diffusion models generate entire clips offline (bidirectional). This is useless for RL, where the simulator must respond immediately to an action.
X-World introduces a Stage-II training phase (Self-Forcing). It modifies the model into a chunk-wise causal generator. By using a Rolling KV Cache, the model only looks at a sliding window of the past, enabling it to generate indefinitely long sequences (24s and beyond) without the "drift" or "hallucination" typically seen in autoregressive models.
Experiments: Action Fidelity and Scene Editing
The results demonstrate impressive "What-If" capabilities. In one experiment, the model generates two different futures from the same starting frame: one where the ego-vehicle stays behind a car, and another where it detours around it. Both rollouts remain photorealistic and causally consistent with the physics of the maneuver.

Furthermore, X-World acts as a zero-shot style transfer tool. By changing a text prompt to "rainy night in Germany," the model can transform domestic daytime data into high-value training assets for international markets, preserving the underlying traffic logic while altering the visual texture.
Critical Insights & Future Outlook
X-World represents a shift from "Video Generation as Art" to "Video Generation as Physics-Engine."
- Takeaway: The use of a Rolling KV Cache and DMD Loss is the "secret sauce" for stability. It mitigates exposure bias—the error accumulation that usually kills long-term video generation.
- Limitation: While visually consistent, the transition from "video space" to "hard safety metrics" (like exact centimeter-level collision detection) still requires hybrid approaches with traditional physics engines.
- Outlook: As VLA models (like XPeng's VLA 2.0) become more prevalent, generative world models like X-World will become the standard "digital twin" for training robots in the "ghost-out" and "near-accident" scenarios that are too dangerous for real roads.
