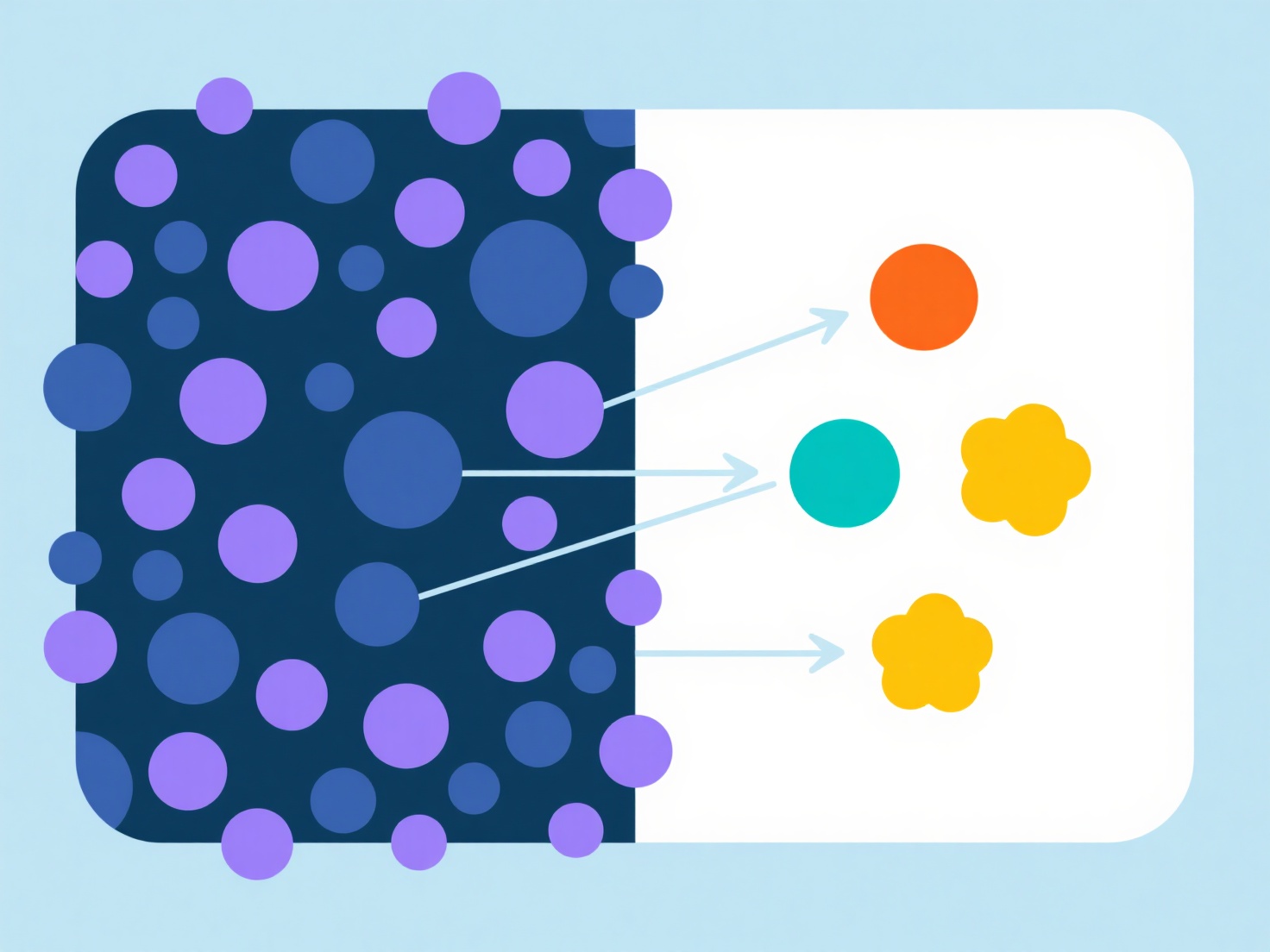
Factor analysis reduces dimensionality by identifying latent constructs, termed factors, that explain covariation among measured variables. This technique feasibly simplifies complex datasets without substantial information loss.
Key principles involve examining variable correlations, extracting factors based on eigenvalue criteria (often >1 or via scree tests), and rotating solutions (e.g., Varimax) for interpretability. Necessary conditions include continuous variables, adequate sample size (typically >100-200 observations), substantial correlations among variables, and absence of severe multicollinearity. The Kaiser-Meyer-Olkin measure should confirm sampling adequacy (>0.6).
To implement it, first prepare your correlation matrix. Extract initial factors (commonly via Principal Component Analysis). Retain factors meeting your criterion. Rotate these factors to clarify their meaning and aid labeling. Finally, interpret the factors by examining high-loading variables. This method is applied in psychology to conceptualize constructs and in market research to group survey items. It streamlines subsequent analyses like regression, enhances conceptual clarity, and identifies redundant measures.