本文提出了 2K Retrofit,一个旨在让现有 3D 基础模型(如 Depth Anything, DUSt3R, VGGT)实现高效 2K 分辨率几何预测的通用框架。该方法通过“低分辨率粗预测 + 熵引导稀疏细化”的两阶段策略,在无需重新训练基础模型或修改其架构的前提下,实现了 SOTA 级别的深度和点图估计。
TL;DR
面对自动驾驶和 AR 领域对 2K 高清深度图计算的渴求,2K Retrofit 提出了一种“四两拨千斤”的方案:不需要重新训练动辄数亿参数的基础模型(Foundation Model),只需通过一个轻量级的熵引导稀疏细化层,就能将现有的低分辨率模型无缝升级到 2K 分辨率,且推理速度比传统方法快 3-17 倍。
核心速览:背景与定位
尽管 Depth Anything 和 DUSt3R 等模型已经统治了通用几何预测领域,但它们在面对 2K(1920x1440)分辨率图像时往往显得“心有余而力不足”。直接馈送大图会导致显存爆炸(VRAM > 80GB),而简单的插值上采样则会丢失关键的几何细节(如扶手、线缆、物体边缘)。
2K Retrofit 在学术坐标系中属于即插即用型高效推理框架。它不是要取代现有的 SOTA 模型,而是作为一种“增强套件”,跨越了从学术研究到工业级大规模高清部署之间的巨大鸿沟。
痛点深挖:为什么高清 3D 这么难?
- 算力陷阱:Transformer 模型的计算量随分辨率呈二次方增长,2K 图像的像素量是常用训练分辨率的 10 倍以上。
- 局部 vs 全局的博弈:切片(Patch-wise)处理虽能降显存,但容易导致整体几何结构不一致,甚至在拼接处产生断层。
- 冗余浪费:研究发现,高分辨率下的精度提升主要集中在物体边界(仅占总像素的 10% 左右),对光滑的墙面进行 2K 密集计算是极大的算力浪费。
核心方法论:熵引导的稀疏智慧
2K Retrofit 的直觉非常清晰:把算力花在刀刃上。
1. 熵选择器 (Entropy Selector)
作者发现,模型在不确定的地方误差最大。通过计算预训练模型 Head 输出特征的信息熵,可以精准地定位出那些几何结构复杂、边缘模糊的像素。实验表明,仅聚焦前 10% 的高熵像素,就能覆盖 80% 的误差来源。
2. MinkowskiUNet 稀疏卷积
选出像素后,如何高效处理?如果用普通 CNN 还是会涉及全图计算。2K Retrofit 引入了稀疏卷积(MinkowskiUNet),只对选定的活跃点进行高分辨率特征学习,这大幅降低了 FLOPs。
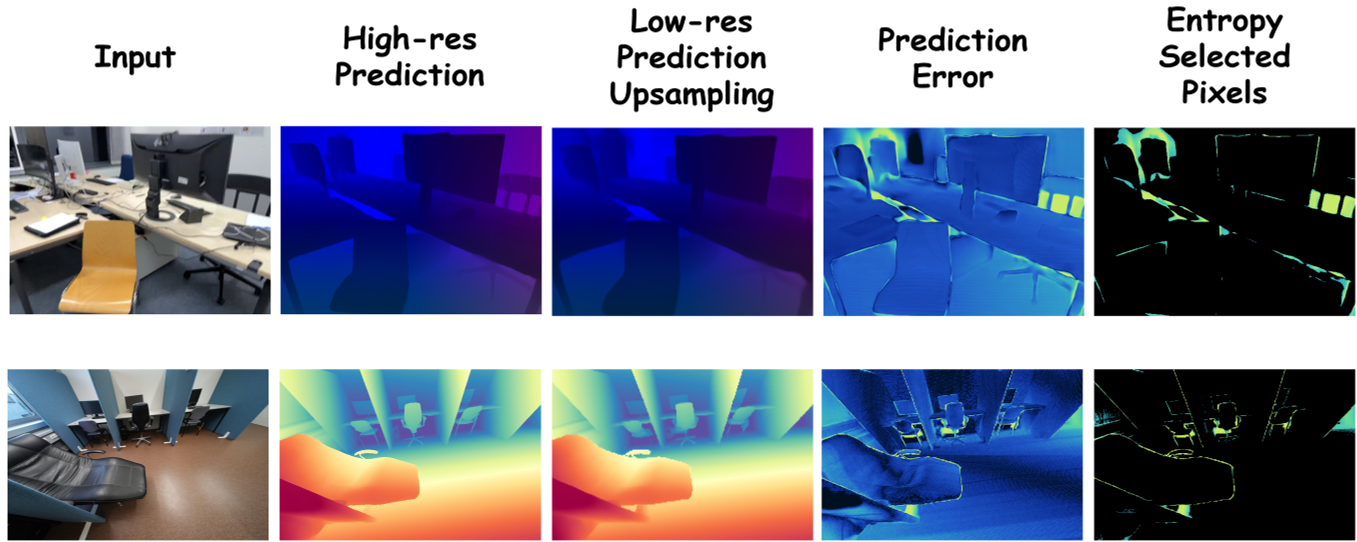 图 2:2K Retrofit 整体架构。左侧为冻结的基础模型提供全局一致性,右侧稀疏分支提供高频细节补强。
图 2:2K Retrofit 整体架构。左侧为冻结的基础模型提供全局一致性,右侧稀疏分支提供高频细节补强。
3. 门控融合 (Gated Fusion)
为了防止细化后的局部细节与全局结构脱节,作者设计了一个多层感知机(MLP)门控。它根据两幅图的不确定性,动态决定每个像素点该“听谁的”。
实验与结果:全方位的性能碾压
在 ScanNet++ 和 ARKitScenes 的实测中,2K Retrofit 表现惊人:
- 精度:在单目深度估计中,比之前的最强基线 PRO 降低了 30% 以上的 AbsRel 指标。
- 速度:在 4090 GPU 上,点图预测达到 5.5 FPS,而原始 2K 密集推理仅有 0.5 FPS,实现了 17 倍的速度跃迁。
- 显存:将 2K 推理所需的 76.5GB 显存压缩到了 32.8GB,这意味着消费级显卡也能跑高清大模型。
 图 3:ETH3D 实测对比。可以看到 2K Retrofit 对细小管道和边缘的还原远胜于基础模型。
图 3:ETH3D 实测对比。可以看到 2K Retrofit 对细小管道和边缘的还原远胜于基础模型。
深度洞察与总结
为什么这个方法有效?
2K Retrofit 抓住了 3D 视觉的一个核心本质:Inductive Bias(归纳偏置)。全局结构由低频语义决定(不需要高分辨率),局部细节由高频几何决定(不需要全局视野)。通过将这两者解耦,它完美避开了“计算复杂度”与“表征精度”的暴力硬刚。
局限性与未来
尽管该方法在结构化场景表现优异,但在全透明、强反射表面(如玻璃)依然会遇到困难,因为这些地方的基础模型初值往往就是错的。未来结合更强的几何先验(如 Normal-from-Depth)或许能补齐最后一块短板。
结论:如果你正在为如何在量产设备上跑通高清 3D 基础模型发愁,2K Retrofit 提供的这套“轻量化补丁”方案,或许就是目前的版本答案。