本文提出了 3D-Mix,一个用于视觉-语言-动作 (VLA) 模型的插件式模块,通过集成 VGGT(Visual Geometry Grounded Transformer)提供的 3D 几何信息来增强机器人的空间智能。该模块采用语义条件门控融合机制,在 SIMPLER 跨域基准测试中实现了平均 +7.0% 的成功率提升。
TL;DR
视觉-语言-动作 (VLA) 模型虽然在语义理解上表现出色,但在 3D 空间感知上一直是“近视眼”。本文提出了 3D-Mix,这是一个即插即用的模块,通过集成 VGGT 的 3D 几何特征并配合语义条件自适应门控,在不修改模型核心架构的前提下,显著提升了机器人在复杂操控任务中的空间智能。实验显示,该方法在跨域测试中平均提升了 7.0% 的成功率。
痛点深挖:MLLM 的“3D 盲区”
当前主流的 VLA 模型(如 OpenVLA, 等)大多构建在强大的多模态大模型(MLLM)之上。虽然这些模型在 2D 互联网数据上练就了火眼金睛,但在具身智能(Embodied AI)的核心——3D 空间推理上却存在天然缺陷:
- 深度缺失:2D 预训练导致模型难以准确判断物体的深度与绝对位姿。
- 融合混乱:虽然有研究尝试引入 3D 编码器,但融合方式五花八门(从直接拼接到复杂的交叉注意力),缺乏一种公认的最优范式。
作者通过对比 9 种不同的融合方案(详见下图),发现并不是越复杂的结构越好,关键在于如何让模型“按需取用”几何信息。
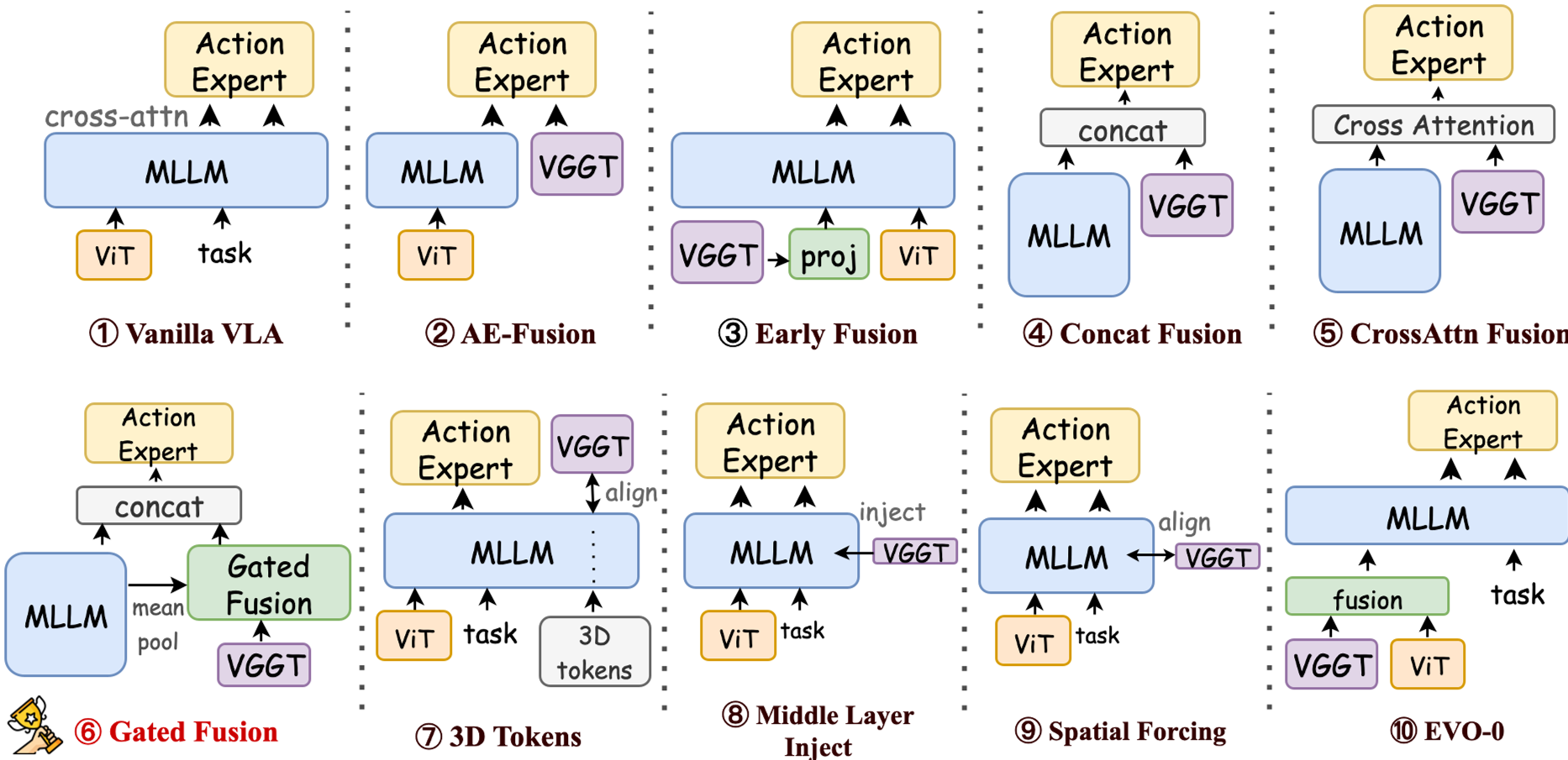 图1:初步实验方案展示。研究涵盖了从输入层(Early Fusion)到中间层注入(Middle Layer Injection)再到输出层(Gated Fusion)的全面系统设计。
图1:初步实验方案展示。研究涵盖了从输入层(Early Fusion)到中间层注入(Middle Layer Injection)再到输出层(Gated Fusion)的全面系统设计。
核心机制详解:3D-Mix 的语义门控 (3D-MI X Module)
1. 语义条件自适应门控 (Semantic-conditioned Gating)
3D-Mix 的核心是门控(Gating)。作者设计了一个可学习的门控向量 ,其计算依赖于两个输入:
- 全局语义摘要 ():从 MLLM 的隐藏状态中平均池化得到。
- 3D 几何特征 ():从预训练且冻结的 VGGT-1B 模型中提取。
计算公式如下:
门控的作用是决定每个空间 Token 的混合权重。例如,当机器人识别到任务属于“抓取细小物体”这类极度依赖精准几何引导的动作时,门控会自适应地增大 3D 几何特征的权重;反之,在理解复杂语义指令而对位姿精度要求不高时,则侧重于 2D 语义。
2. 多架构的插件式兼容层 (GR00T & π-style Support)
3D-Mix 的一大工程优势是其即插即用属性。它能够适应两种主流的 VLA 架构设计:
- GR00T-style (模块化解耦合):3D-Mix 置于 MLLM 之后,DiT 动作专家通过统一的 Cross-Attention 消费融合后的增强特征。
- π-style (层级强耦合):在每一层 DiT 与 MLLM 隐藏状态的对应层之间,均插入一个独立的 3D-Mix 门控模块,实现层级递进的空间推理。
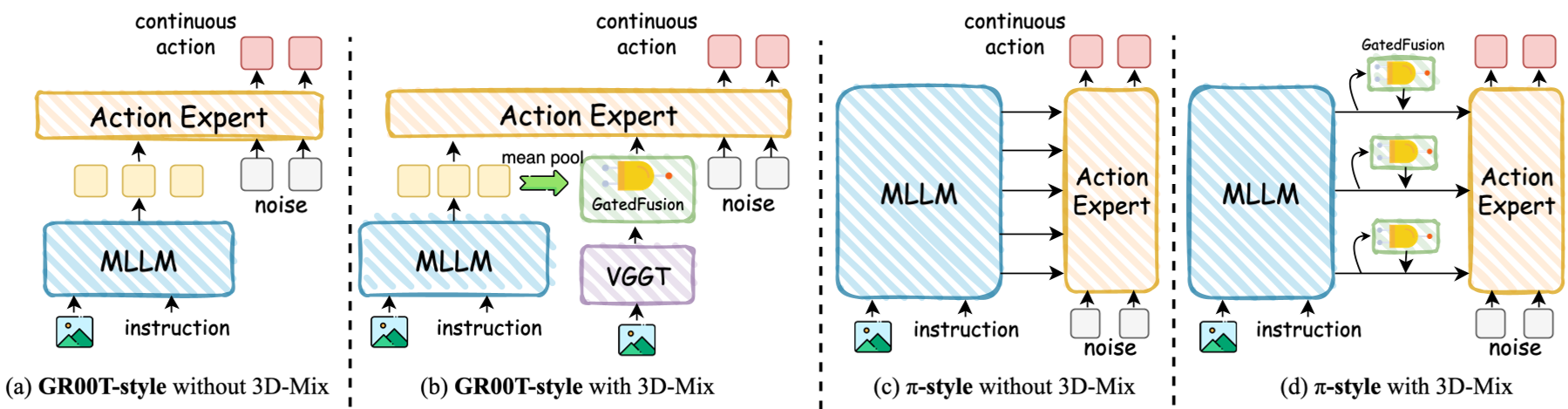 图2:展示了 3D-Mix 如何灵活集成进 GR00T-style 和 π-style VLA 架构中,无需改动已有组件的内部代码。
图2:展示了 3D-Mix 如何灵活集成进 GR00T-style 和 π-style VLA 架构中,无需改动已有组件的内部代码。
实验结果与深度观察
SOTA 对比:全线飘红的性能提升
研究团队在 SIMPLER (跨域泛化) 和 LIBERO (多任务学习) 两个权威基准进行了海量测试(覆盖 2B 至 8B 参数的 9 种 MLLM,如 Qwen, RoboBrain, RynnBrain 等)。 表格显示:
- SIMPLER: 在所有 GR00T 式变体中实现了平均 +7.0% 的性能跳跃。
- RynnBrain-8B: 在原本已达到 52.6% 成功率的高基准上,进一步冲到了 65.11%。
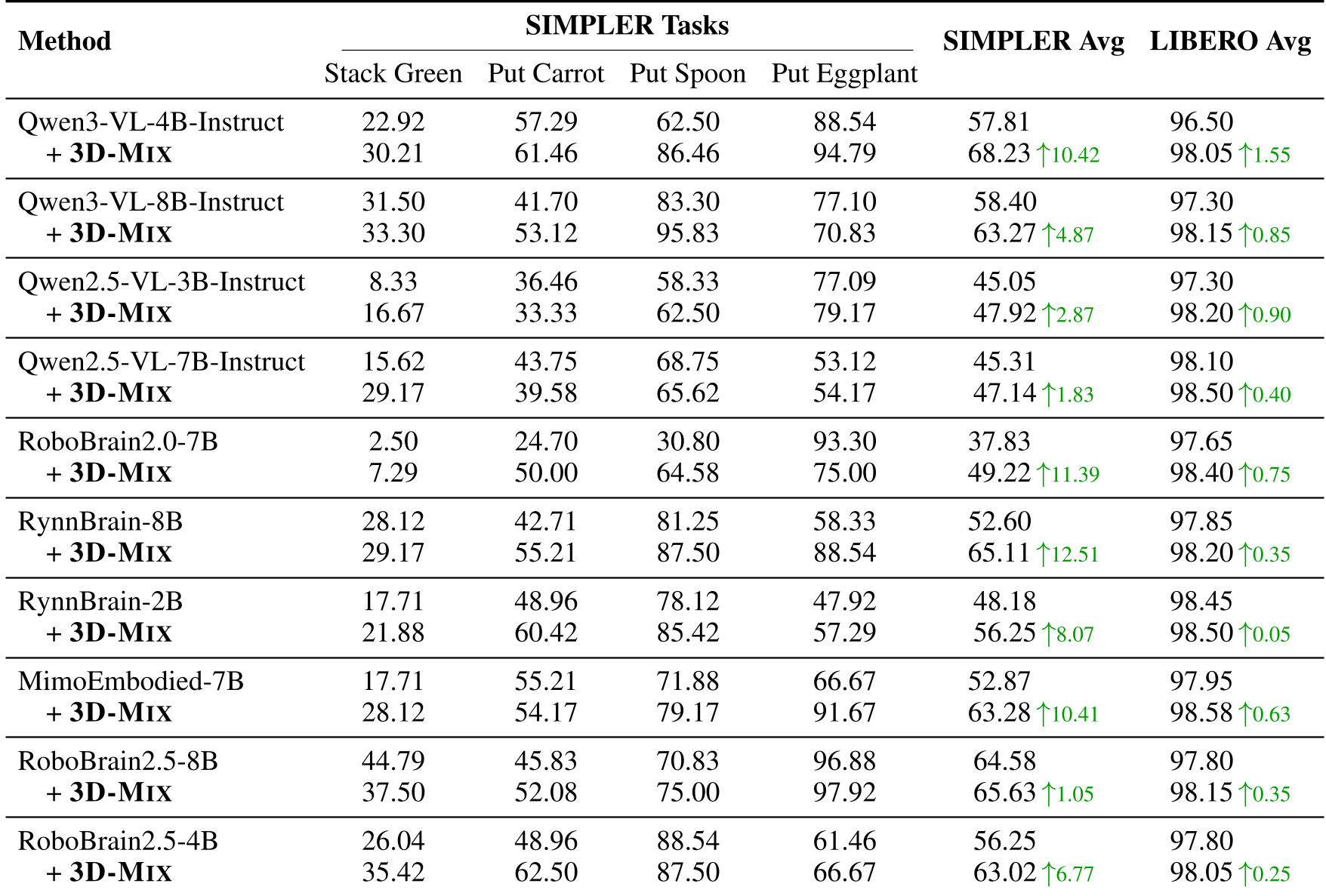 表1:不同模型集成 3D-Mix 后的性能表现。可以观察到,无论模型基础大小,3D 信息的引入都在 OOD 任务中带来了质的提升。
表1:不同模型集成 3D-Mix 后的性能表现。可以观察到,无论模型基础大小,3D 信息的引入都在 OOD 任务中带来了质的提升。
消融分析:空间信息的真伪验证
为了排除“引入 3D-Mix 只是变相增加了模型参数量”的质疑,作者进行了两个有趣的消融实验:
- 真实度验证: 运行时如果用全零向量或高斯噪声代替 VGGT 特征,性能会大幅崩塌。这说明 3D-Mix 确实学会了从 VGGT 中提取有价值的几何引导。
- 冻结 vs. 训练: 保持 VGGT 处于 Frozen (冻结) 状态反而往往比全量微调效果更好,这反映了预训练几何特征的通用性极强,且降低了计算门槛。
总结与启示
3D-Mix 成功将过去这类复杂的“多源信息融合”问题,转化为了一个简洁的“特征注入与门控平衡”问题。
- 行业启发:我们没必要为了 3D 感知去从头训练一套昂贵的端到端 VLA 模型。通过现成的 3D 编码器 + 轻量级插件模块,就能极大地释放现有 VLM 的具身潜能。
- 未来展望:对于资源受限的边缘端机器人设备,作者提出的“稀疏层融合策略(Sparse Layer Fusion)”为在 π-style 架构下节省显存提供了实战指南。
正如论文标题暗示的那样,3D-Mix 向我们展示了在具身大模型时代,**几何感知(Geometry-grounding)**不应是奢侈品,而应是每个 VLA 模型的标配。