The paper introduces a non-asymptotic theory of generalization in deep learning by partitioning the output space into a "signal channel" and a "test-invisible reservoir" via the empirical neural tangent kernel. It proves that generalization is possible even in the full feature-learning regime and proposes a practical "population-risk" optimizer update that significantly accelerates grokking and suppresses memorization.
TL;DR
Researchers have developed a non-asymptotic theory of generalization that explains why overparameterized models work in the "feature-learning" regime. By decomposing the model's output space into a Signal Channel and a Test-Invisible Reservoir, they show how noise gets "trapped" while signal propagates. They translate this theory into a one-line change to the Adam optimizer that boosts training speed and accuracy across tasks ranging from PINNs to LLM alignment.
The Problem: Beyond "Lazy" Theory
Standard deep learning theory often falls into two camps:
- Classical Bounds: Measures like VC dimension are "vacuous" because they suggest models with millions of parameters should always overfit.
- Lazy Training (NTK): The Neural Tangent Kernel framework assumes the model doesn't change much during training. However, modern AI thrives precisely because features do change (the feature-learning regime).
The core mystery remains: Why does SGD learn the "clean" signal quickly while only slowly memorizing the noise?
Methodology: The Signal-Noise Separation
The authors view the training process in Output Space. They define two distinct zones:
- The Signal Channel: Directions aligned with the eigenvectors of the tangent kernel where the empirical error dissipates rapidly into generalizable knowledge.
- The Reservoir: Directions where the kernel's eigenvalues are near-zero. These directions are "test-invisible"—errors stored here affect training loss but have zero impact on test prediction.
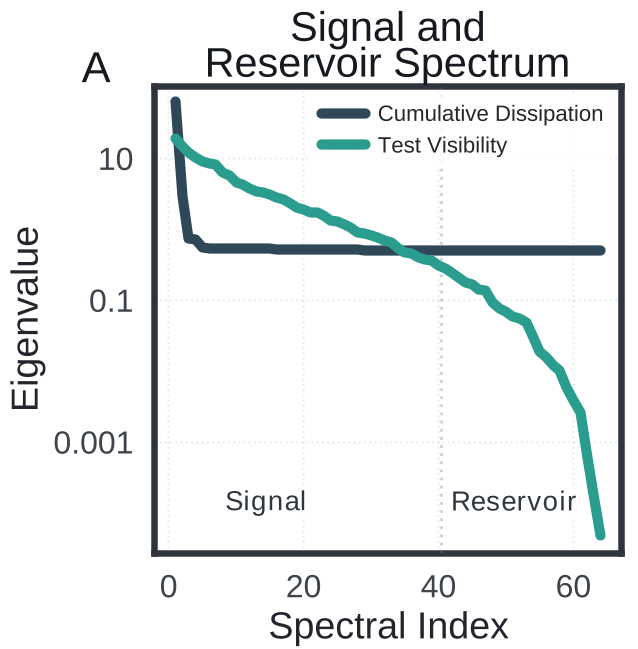
The key insight is Drift vs. Diffusion. Within the signal channel, coherent signals from the population accumulate via fast linear drift, while random noise from specific examples is suppressed into a slow random walk.
The authors derive a Population-Risk Objective that doesn't requires a validation set. It leads to a simple rule: a parameter should only be updated if: where is the mean gradient and is the variance within the batch. This acts as an SNR gate.
Experimental Proof: Solving Grokking and Noise
The theory was put to the test in three "hard" regimes for generalization:
1. Collapsing the Grokking Delay
In algorithmic tasks like modular division, models often "grok" (suddenly generalize) long after they have reached zero training error. The Population-Risk update reached 95% accuracy 4.9x faster than AdamW.

2. PINNs and Noisy Observations
Physics-Informed Neural Networks (PINNs) often struggle with noisy initial conditions. The SNR gate prevents the model from fitting high-frequency noise while allowing the physical laws to emerge. The result? A 2.4x speedup in reaching target accuracy.
3. DPO Fine-tuning
When aligning LLMs (like Qwen 2.5) with noisy human preferences (30% swapped labels), the population-risk optimizer maintained higher reward accuracy and stayed 3x closer to the reference policy, suggesting it ignores the contradictory "noise" in the human feedback.
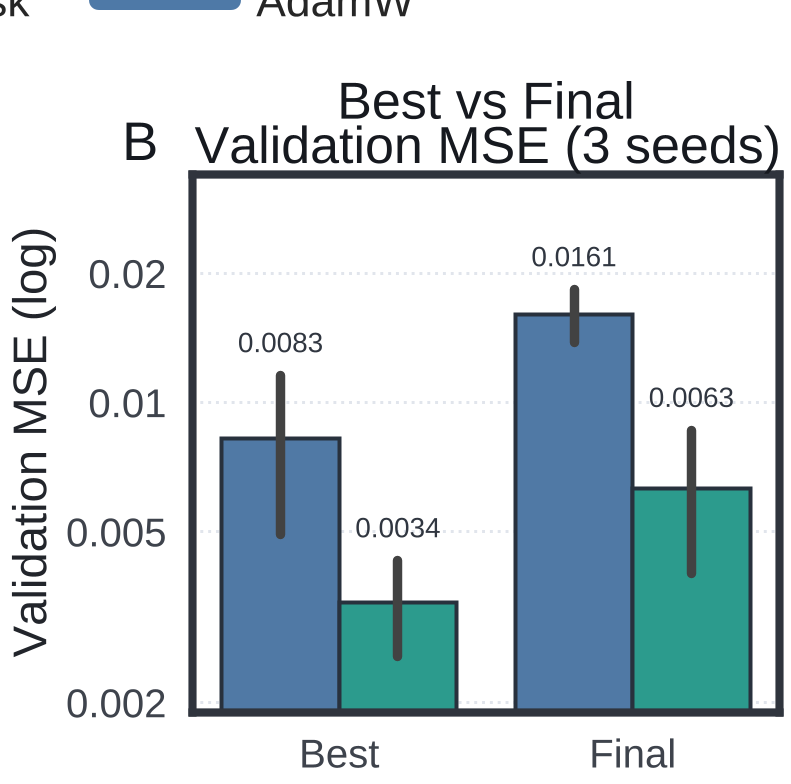
Critical Insight & Conclusion
This work provides a unifying "Physics" of deep learning. It suggests that Benign Overfitting and Double Descent are not anomalies but predictable consequences of how kernels partition the output space.
The Takeaway for practitioners is profound: We don't necessarily need more data or bigger validation sets to combat noise; we need optimizers that are mathematically aware of the signal-to-noise ratio in their own gradients. This "Self-Influence" approach essentially allows the model to perform a leave-one-out cross-validation internally at every single step.
Limitations: While the theory handles feature learning, it assumes a certain degree of smoothness in the network. In highly discontinuous landscapes, the "test-invisibility" of the reservoir might be challenged.