本文提出了 ABMamba,这是首个全开源的视频多模态大语言模型(MLLM)。该模型将具有线性计算复杂度的 Mamba 作为语言后端,并引入了对齐分层双向扫描(AHBS)模块,在 VATEX 和 MSR-VTT 任务中实现了 SOTA 性能,且推理吞吐量提升了约 3 倍。
TL;DR
视频理解任务长期受困于 Transformer 架构的“二次方复杂度陷阱”。Keio 大学等机构提出的 ABMamba 首次证明了,通过 Deep State Space Models (Deep SSMs) 和一种创新的 AHBS(对齐分层双向扫描) 模块,我们可以在大幅降低资源开销的同时,获得超越传统 Transformer 模型的视频描述(Video Captioning)性能。
核心战绩:
- 速度提升:3 倍于基线模型的吞吐量(Throughput)。
- 显存极致优化:推理显存增加量减少 77%。
- 全开源:代码、模型权重、数据集完全开放。
1. 痛点:被牺牲的“细节”
在处理视频时,现有的 MLLM 通常面临两难境地:
- 原生 Transformer:模型处理序列长度增加时,计算量呈平方级增长,导致长视频处理极其缓慢甚至 OOM。
- 过度压缩:为了规避上述问题,许多模型(如 Video-XL)对 Token 进行大幅下采样,这虽然快了,但却把视频中转瞬即逝的关键动作“压缩”没了。
作者认为,视频理解的本质是处理多尺度的时间动态。我们要快,但不能通过牺牲分辨率来换取。
2. 核心架构:AHBS 模块的物理直觉
ABMamba 的架构由三部分组成:双视觉编码器(SigLIP + DINOv2)、AHBS 模块、以及 Mamba 语言后端。
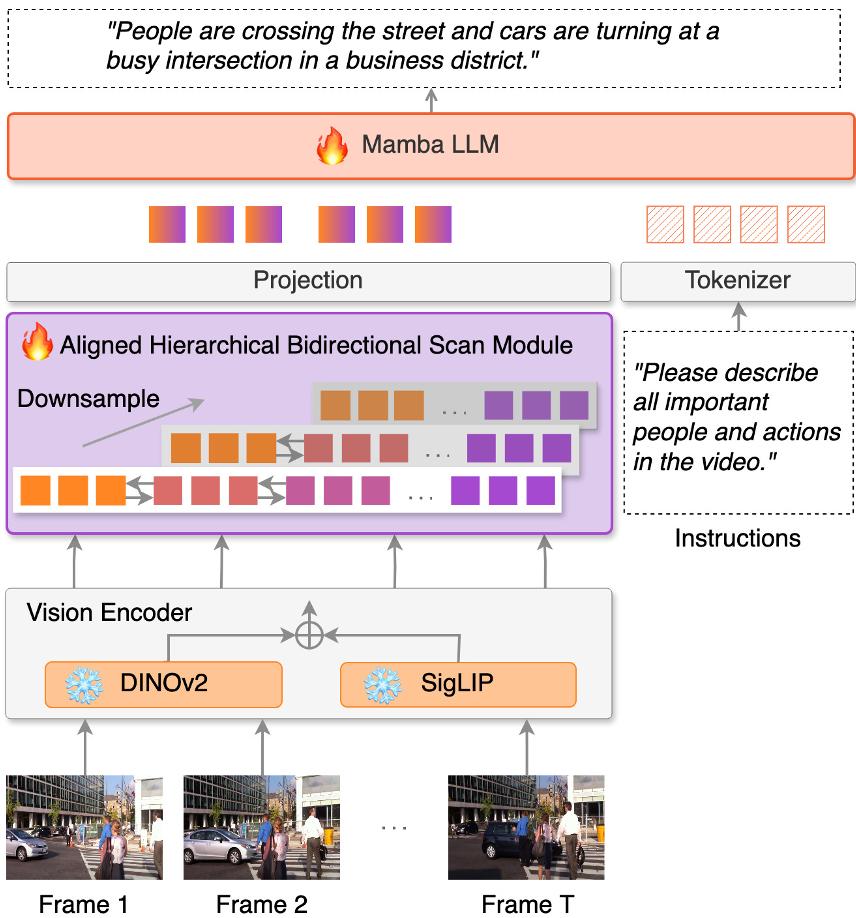
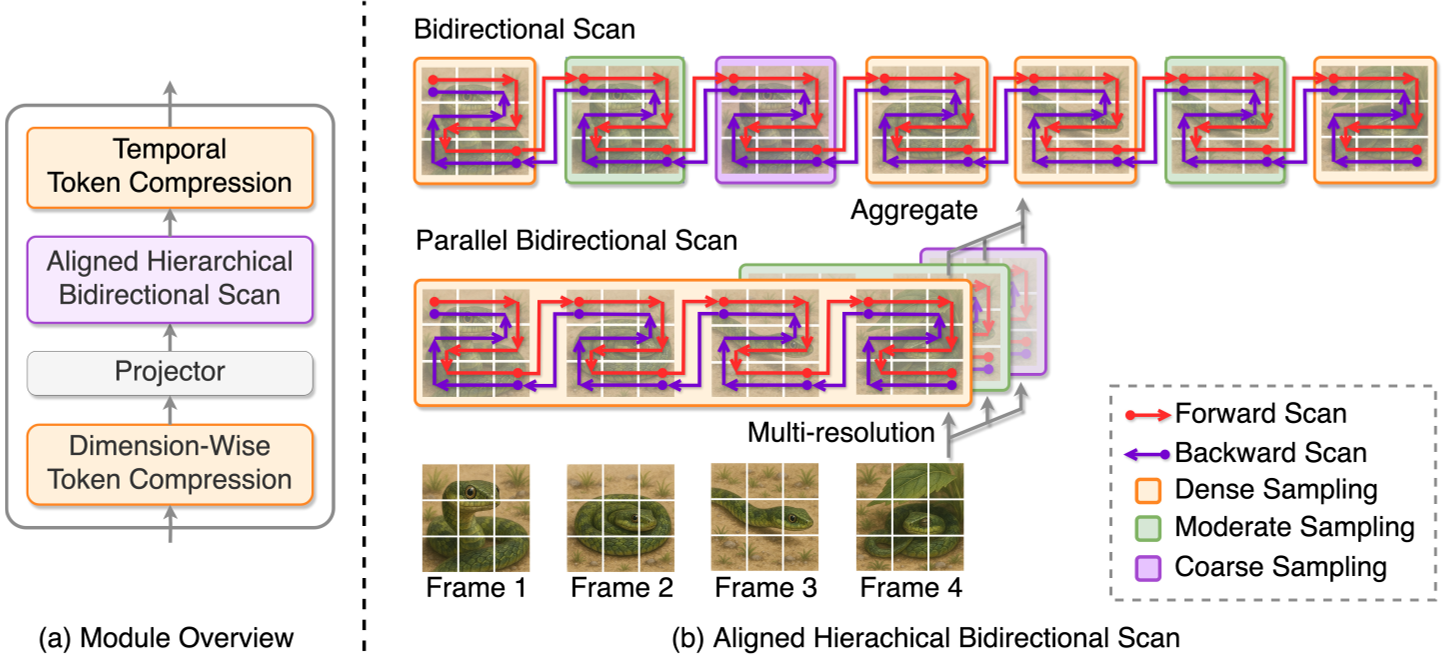
为什么 AHBS 有效?
AHBS(Aligned Hierarchical Bidirectional Scan)模块的设计灵感来自于人类观察视频的方式:我们既会关注整体趋势,也会捕捉瞬间动作。
- 多分辨率扫描 (Hierarchical):模块设置了 条并行路径,每一条路径以不同的步长(Stride)对时间轴进行采样。这保证了模型能同时捕捉到“慢动作”和“全局趋势”。
- 双向传播 (Bidirectional):传统的 SSM 是单向的,但在视觉中,后续帧对于理解前序帧同样重要。AHBS 通过前向和后向双向扫描,打破了因果局限,增强了时空建模能力。
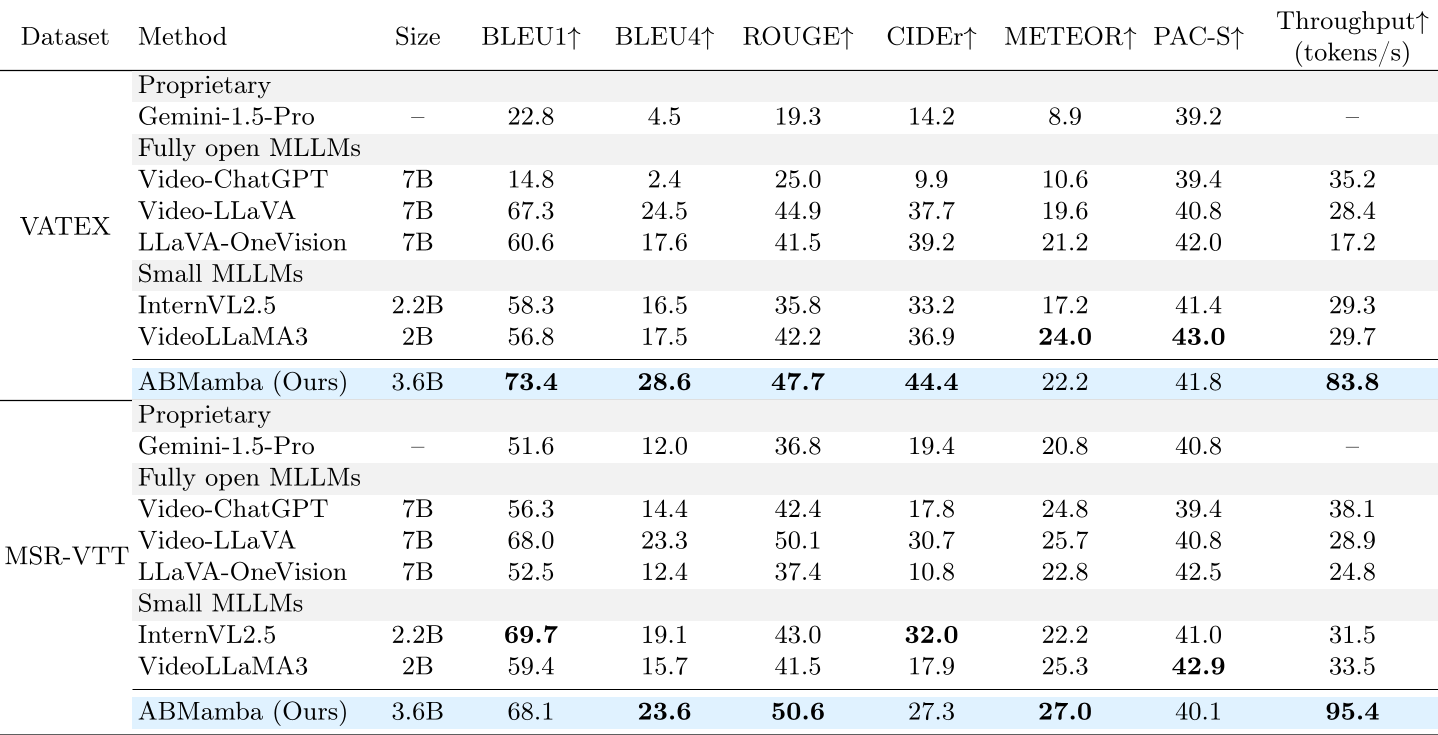
3. 实验结果:效率与精度的双重突破
在标准测试集 VATEX 和 MSR-VTT 上,ABMamba 展示了极强的竞争力,特别是在 BLEU4 这一关键评价指标上显著领先于同级别的 Transformer 模型。
深度发现 (Ablation Study):
- 双向扫描的价值:移除反向扫描后(w/o backward scan),CIDEr 分数大幅下降,证明双向感知在视频语义理解中不可或缺。
- 多尺度分支的价值:实验证明,当并行分支 时效果最佳,验证了多分辨率建模的必要性。
4. 客观分析:它的局限性
尽管 ABMamba 表现优异,但作者也在文中坦诚地进行了 Error Analysis:
- 幻觉问题 (Hallucinations):在 100 个典型失败案例中,约 68% 属于对象幻觉(Object Hallucination)。
- 场景遗漏:在处理包含多个不连贯场景的复杂视频时,ABMamba 有时会倾向于只描述其中一个局部场景。
5. 总结与展望
ABMamba 的出现,为多模态 LLM 提供了一条除 Transformer 之外的康庄大道。它证明了基于 SSM 的线性复杂度模型在处理高帧率、长时程视频任务时,具有天然的能效比优势。
对于开发者而言,ABMamba 的开源不仅是一个模型,更是对 Mamba 执行端到端视频建模的一次有力背书。在未来实时交互机器人、自动驾驶感知等对延迟极度敏感的领域,这种架构将极具潜力。