本文提出了 AcceRL,一个专为具身智能 Vision-Language-Action (VLA) 模型设计的分布式异步强化学习框架。该框架首次将可训练的扩散世界模型 (World Model) 集成到异步流水线中,通过“梦境训练”绕过物理仿真瓶颈,并在 LIBERO 基准测试中实现了 SOTA 性能。
TL;DR
传统的强化学习(RL)在处理大规模具身智能模型(VLA)时,常常被慢速的物理仿真器和频繁的同步等待拖垮。本文提出的 AcceRL 彻底打破了这一桎梏。它通过物理隔离训练、推理和采样流,并首次引入可训练的扩散世界模型(Diffusion World Model),让模型能够在合成的虚拟经验中高速学习。实验证明,该框架不仅解决了 GPU 闲置问题,还让样本效率提升了惊人的 200 倍。
痛点深挖:被物理世界锁死的计算力
在机器人控制领域,Vision-Language-Action (VLA) 模型(如 OpenVLA)通常利用模仿学习(Behavior Cloning)初始化,但这种方法极易产生误差累积。引入 RL 进行在线微调是标准解法,但面临三大“长尾”难题:
- 步骤级长尾:GPU 必须等待最慢的仿真步完成才能进行下一次推理。
- 回合级长尾:不同任务结束时间不一,导致同步屏障下的大量 GPU 泡泡(Idle Bubbles)。
- 集群级长尾:传统 PPO 需要所有 Worker 收集完数据才能更新,单点慢则全盘慢。
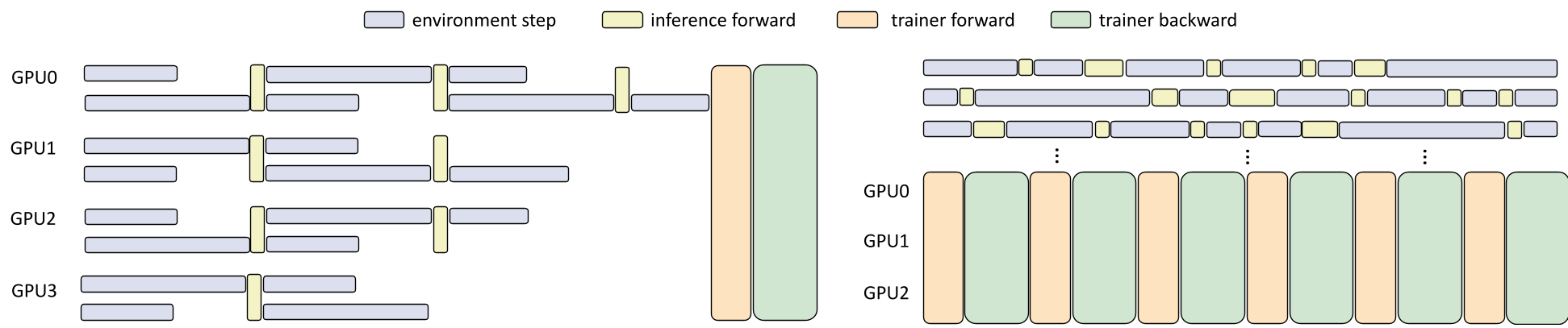
核心方法论:AcceRL 的解耦艺术
1. 双层异步架构 (Macro & Micro Asynchrony)
AcceRL 将系统拆分为三个独立流:
- Inference-as-a-Service:环境交互在 CPU 上跑,推理请求发送到专用的 GPU 推理池。通过动态窗口机制(Dynamic Window Mechanism)实现最优 Batching。
- 非阻塞训练流:训练器从分布式 Buffer 采样,同时利用 ZeRO-2 优化显存,参数更新后通过 NCCL 广播。
2. 学习于“梦境”:集成世界模型
这是 AcceRL 最具前瞻性的设计。它集成了一个基于 DIAMOND 架构的扩散模型(Mobs)和一个奖励模型(Mreward)。
- 想象力采样:Rollout Worker 不再死磕物理引擎,而是先在扩散模型生成的“高保真梦境”中进行短步长(Horizon H)的预测与学习。
- 潜力奖励 (Potential-based Reward):利用状态间的成功概率差作为稠密奖励,引导模型快速收敛。
3. 算法层面的“稳压器”
- Token-level 优化:针对 VLA 的自回归特性,将 CLIP 损失作用于每个 Token,避免了 Chunk-level 导致的数值不稳定。
- GIPO 算法:用高斯置信权重(Gaussian trust weight)取代 PPO 的硬截断(Hard Clipping),在处理异步导致的策略滞后(Policy Lag)时,稳定性远超原生 PPO。
实验与结果:超线性的算力释放
在 LIBERO 基准测试上,AcceRL 的表现令人瞩目。
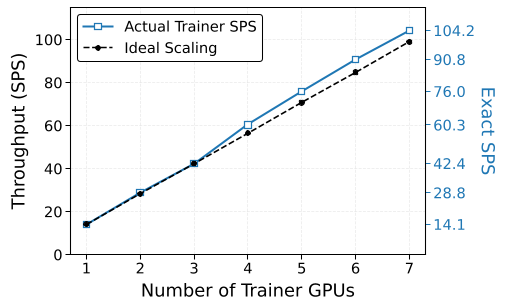
超线性扩展性
由于采用了 ZeRO-2 分散显存压力,随着 GPU 数量增加,单卡能容纳的微批次(Micro-batch)更大,算术强度提升。在 7 块 H200 上,训练吞吐量达到了 104.22 SPS,展现出比理想状态更优的扩展曲线。

样本效率的跃迁
借助世界模型的虚拟经验,AcceRL 在不到 10,000 步的真实环境交互中,就能让模型性能突破 0.8 的 Reward 阈值,这在处理图像作为观测的具身任务中是非常罕见的速度。

深度洞察与总结
AcceRL 的核心贡献在于它不仅仅是一个算法改进,更是一套成熟的工业化生产系统方案。 它巧妙地解决了大模型 RL 中“昂贵算力与廉价模拟器”之间的矛盾。
局限性: 虽然在具身任务上表现出色,但该框架目前尚未完全支持大规模语言模型(LLM)的全量 Post-training 对齐。
展望: 本文提出的“置信度奖励模型 + 扩散世界模型 + 全解耦异步管道”可能会成为未来机器人垂类大模型的主流训练标准。它不仅让机器人学会了“做”,更让机器人学会在大脑中“模拟后果”,这正是通往 AGI 的必经之路。