ActiveGlasses is a novel robot learning system that captures natural human manipulation and "Active Vision" using smart glasses for zero-shot transfer to robotic platforms. It utilizes a head-mounted stereo camera and 6-DoF tracking to collect bare-hand demonstrations, then deploys an object-centric 3D point-cloud policy where a secondary robot arm mimics the human's head movement to overcome occlusions and distance.
TL;DR
ActiveGlasses is a lightweight, head-mounted system that allows robots to learn not just how humans move their hands, but how humans move their heads to see better. By capturing bare-hand demonstrations via AR glasses and deploying them using a "perception arm" that mimics human head movement, the system achieves state-of-the-art results in occluded and precision-heavy tasks with zero-shot transfer.
The "Perception-Manipulation" Gap
Traditional robot learning treats vision as a static input. Whether it is a fixed third-person camera or a passive wrist-mounted one, the robot's "eyes" are often slaves to the environment or the end-effector.
Humans, however, use Active Vision. If a bookshelf blocks our view, we lean. If a slot is tiny, we move closer. Prior works often treated these intentional head movements as "sensor noise" because the robot didn't have a neck. ActiveGlasses argues that this head motion is a high-value signal of visual intent.
Methodology: Capturing Intent, Not Just Motion
The authors designed a system that bridges two gaps simultaneously:
- The Manipulation Gap: Humans use bare hands; robots use grippers. Instead of mapping fingers to claws, ActiveGlasses tracks the Object Trajectory.
- The Perception Gap: Robots are given a "Perception Arm"—a secondary 6-DoF arm that carries the camera and replicates the human operator's head trajectory.
System Pipeline
- Data Collection: An operator wears XREAL smart glasses and a ZED Mini stereo camera. They perform tasks naturally. The system records the 3D point cloud and the 6-DoF head pose.
- Policy Design: The researchers used a modified RISE architecture (3D Diffusion Policy). Crucially, they use two separate diffusion heads: one to predict the next object pose and one to predict the relative head movement.
- Object-Centricity: By predicting where the object should go in 3D space, the policy becomes "embodiment-agnostic," allowing it to run on a UR5 or a Flexiv robot without retraining.
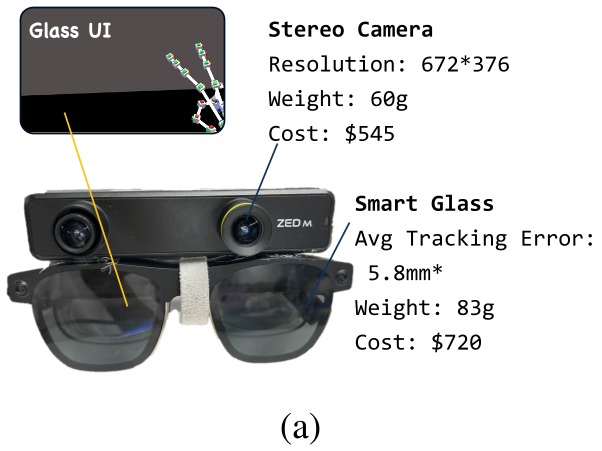 Figure 1: The ActiveGlasses framework. Human data (left) is processed into point clouds, and the policy (right) controls both the manipulation arm and the perception arm.
Figure 1: The ActiveGlasses framework. Human data (left) is processed into point clouds, and the policy (right) controls both the manipulation arm and the perception arm.
Experiments: Why "Absolute" Action Space Wins
One of the paper's most interesting technical insights comes from their ablation studies. They found that predicting Absolute Object Trajectories (instead of relative ones based on the current object pose) significantly reduced the error rate.
When the model was given "current object pose" as a condition, it actually became lazy—it started to overfit to dominant motion patterns and ignored the visual input. By forcing the model to infer everything from the point cloud to an absolute world-frame target, it remained "alert" to changes in the scene.
 Table 1: Success rates across three tasks. ActiveGlasses consistently outperforms static-vision baselines and large-scale VLAs like π0.5.
Table 1: Success rates across three tasks. ActiveGlasses consistently outperforms static-vision baselines and large-scale VLAs like π0.5.
Real-World Impact
The tasks chosen—Book Placement, Bread Insertion, and Occluded Water Pouring—are notoriously difficult for standard robots because the target (a slot or a cup) is often hidden from a static camera's view.
ActiveGlasses proves that:
- Efficiency: Bare-hand collection is faster and less taxing than teleoperation.
- Robustness: Active vision provides the visual feedback necessary to handle 1cm-precision tasks.
- Portability: Because the policy is object-centric, it was deployed zero-shot on both UR5 and Flexiv arms with minimal performance degradation.
Critical Insight & Future Work
The core takeaway is that human head movement is a form of "Visual Attention" expressed physically. By capturing this, we give robots the ability to "understand" what part of the scene is critical for success.
However, the system currently requires a dual-arm setup (one for the eye, one for the hand). The logical next step is integrating this into humanoid robots, where the "perception arm" is simply the robot's neck, finally aligning robot morphology with the human data.
Takeaway: Stop throwing away head-pose data. It’s the key to making robots see like us.