本文提出了 ActiveGlasses,一种利用智能眼镜(XREAL)和立体相机(ZED Mini)捕捉人类徒手操作及主动视觉(Active Vision)轨迹的机器人学习系统。通过 3D 点云策略预测物体 6-DoF 轨迹与头部运动,实现了从人类示教到双臂机器人(操作臂+视觉臂)的 Zero-shot 迁移,在遮挡和高精度任务中表现优异。
TL;DR
ActiveGlasses 是一个创新的机器人学习系统。它通过让操作者佩戴集成了立体相机的智能眼镜,直接以徒手(Bare-hand)方式完成任务示教,同时记录下人类为了观察物体而产生的头部运动(Active Vision)。在部署时,一台机器人负责操作,另一台机器人负责模仿人类“转头”观察。这种“眼随手动”的协同机制,让机器人在处理遮挡和高精度插拔任务时,成功率比主流 baseline 提升了 30% 以上。
1. 痛点深挖:被动视觉的局限性
在机器人领域,视角(Viewpoint)通常是静态的(笼式相机)或者极其死板的(腕部相机)。
- 固定相机:容易被机械臂自身或环境物体遮挡。
- 腕部相机:视角完全被末端执行器“绑架”,无法独立于动作进行观察调整。
- 数据采集效率:现有的遥操作(Teleoperation)或手持设备(如 UMI)虽然效果好,但操作者不仅累,而且动作僵硬,缺乏人类在处理精细活时那种“侧头观察”、“近距离聚焦”的感知智慧。
2. 核心直觉:像人一样观察,像人一样操作
ActiveGlasses 的核心 Insight 在于:人类的动作是由意图驱动的感知引导的。当你要把一本书塞进挤满的书架时,你会不自觉地歪头看那个缝隙。
系统架构
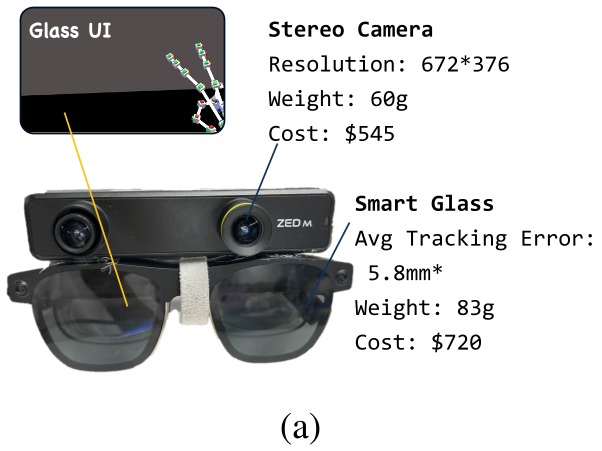
- 硬件层:XREAL Air 2 Ultra 眼镜(捕捉 6-DoF 头部姿态)+ ZED Mini 相机(生成立体视觉)。
- 感知层:使用 FoundationStereo 生成深度图,并通过 Grounded-SAM 去除画面中的人类手臂(Masking),只留下干净的环境点云。
- 策略层:
- 以物体为中心 (Object-Centric):预测的是物体的 6D 轨迹,而不是机械臂的关节角。这使得同一套策略可以部署在 UR5 或 Flexiv 等不同形态的机器人上。
- 同步扩散输出:网络同时输出两个轨迹——一个是物体的操作轨迹(绝对坐标),一个是头部的移动轨迹(相对坐标)。
3. 实验结果:主动感知的威力
研究团队在三个“不转头看不清”的任务中进行了测试:
- 书柜置物:初始位置被墙遮挡。
- 面包插入:烤面包机插槽极窄。
- 远距离遮挡倒水:目标杯子被挡板完全遮盖。

关键发现:
- SOTA 对比:相比于直接套用大模型 π0.5,ActiveGlasses 在复杂阶段(Stage 3)的成功率大幅领先。这是因为 π0.5 在 2D 图像空间中很难解耦头部运动带来的背景剧烈晃动,而 3D 点云表征在世界坐标系下保持了空间一致性。
- 消融实验:如果不启用“主动视觉”(感知臂固定),模型在面包插入任务中完全失效(0/20),证明了动态视角调节在精细操作中不是可选项,而是必选项。
4. 深度洞察:为什么不输入“当前位姿”?
文章中有一个非常有趣的 Ablation Study:通常在模仿学习中,我们会把机械臂当前的 Pose 作为 Condition 输入。但作者发现,如果不输入物体当前的位姿 (w/o current pose),效果反而更好。
原因分析:显式输入当前位姿会给模型提供一条“捷径”,导致它倾向于记住动作的统计均值(Overfitting),从而忽略了实时视觉反馈。通过“禁闭”位姿信号,迫使 Diffusion Policy 每一帧都必须从点云中提取特征,增强了系统应对外界干扰的鲁棒性。
5. 总结与未来展望
ActiveGlasses 证明了轻量化 AR 设备+主动视觉协同是解决机器人“数据饥渴”的一条康庄大道。它让数据采集变得像戴眼镜散步一样简单,同时捕捉到了人类感知中最高级的部分。
局限性:目前系统仍依赖稳定的物体位姿估计(如 FoundationPose),对于完全无纹理或者是高度变形的物体(如衣物)可能面临挑战。未来如果能将这种主动观察逻辑引入多模态大模型(VLA),机器人的通用操作能力有望迎来真正的质变。
作者简介:本文由上海交通大学 Cewu Lu (卢策吾) 团队发布。该实验室在 3D 视觉与机器人交互领域长期处于领先地位。