本文提出了将主动推理 (Active Inference, AIF) 作为物理 AI 智能体设计的架构基础。该方法通过一个统一的变分自由能 (VFE) 最小化目标,将感知、学习、规划和控制整合在一起,并利用因子图上的响应式消息传递 (Reactive Message Passing) 实现资源受限下的实时推理。
TL;DR
在物理人工智能(Physical AI)领域,生物智能体的灵活性一直是人造系统难以逾越的鸿沟。本文提出了一种基于自由能原理 (Free Energy Principle, FEP) 的全新设计 Paradigm。不同于传统机器人学将感知、控制和规划拆分为碎片化模块,主动推理 (Active Inference, AIF) 通过最小化变分自由能 (VFE),实现在单一概率框架下的全栈智能。配合因子图与响应式消息传递,该架构能在算力波动、电力受限的真实物理世界中,展现出类似生物的鲁棒性。
背景定位:为何现有的机器人不够“聪明”?
即便是在 LLM 算力澎湃的今天,顶尖的类人足球机器人(如 RoboCup 冠军)在面对人类幼儿时依然显得笨拙。这种“能力鸿沟”源于物理 AI 必须面对的四大残酷现实:
- 硬时间延迟:必须在毫秒级内做出决策,无法等待完美推理。
- 数据异步:摄像头、雷达、传感器数据到达频率不一。
- 电力波动:无人机或移动机器人的算力预算随电池电量实时变化。
- 环境流转:场景中的实体与关系(如对手数量)不断变化,静态模型难以适应。
核心直觉:从概率论到自由能
作者认为,物理 AI 的本质应当是一个自我组织 (Self-organizing) 的动力系统。根据 FEP,任何能够维持自身结构稳定的系统,其动态过程都可以被描述为在最小化“惊喜” (Surprisal)。
感知与控制的统一
在 AIF 中:
- 感知 (Perception):是指智能体调整其内部状态 ,使得内部模型生成的预测与感知到的 更加匹配。
- 规划与控制 (Planning & Control):被重构为一种“对未来的推断”。智能体通过选择动作 ,使得未来的感知序列符合其预设的“偏好分布”(例如:球进了、电满了)。
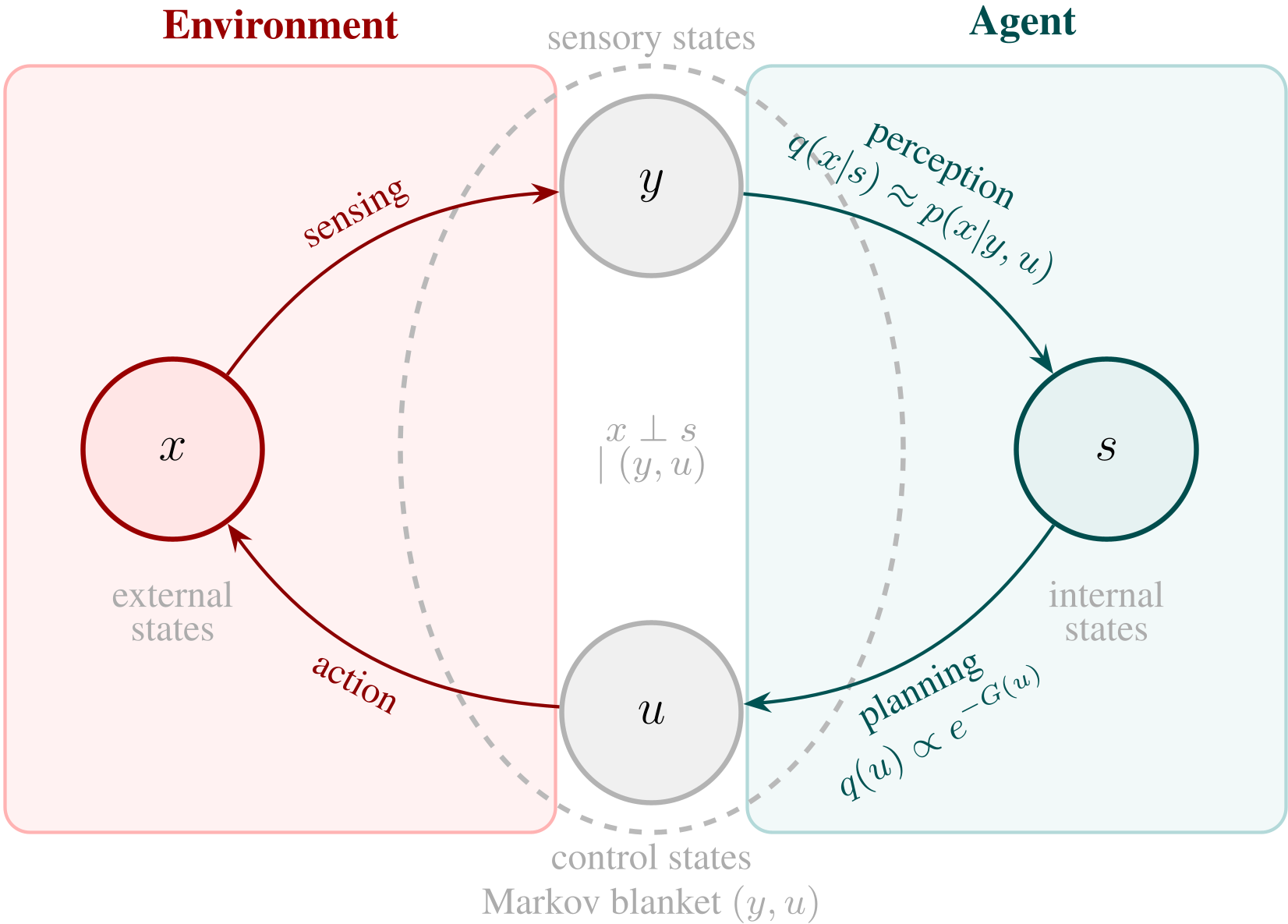 图 1:基于 FEP 的 Markov Blanket 状态划分。内外部状态通过感知与控制状态实现统计隔离与交互。
图 1:基于 FEP 的 Markov Blanket 状态划分。内外部状态通过感知与控制状态实现统计隔离与交互。
方法论:响应式消息传递 (Reactive Message Passing)
这是本文最具工程价值的部分。作者将复杂的变分推断任务映射到 Forney-style Factor Graphs (FFG) 上。
因子图的力量
在因子图中,全局的联合概率分布被拆解为局部函数的乘积。这意味着:
- 局部性 (Locality):每个节点只需与邻居交换消息,无需全局调度。
- 计算同质化 (Computational Homogeneity):无论是底层运动控制还是高层战略,其计算原语都是一样的消息更新公式。
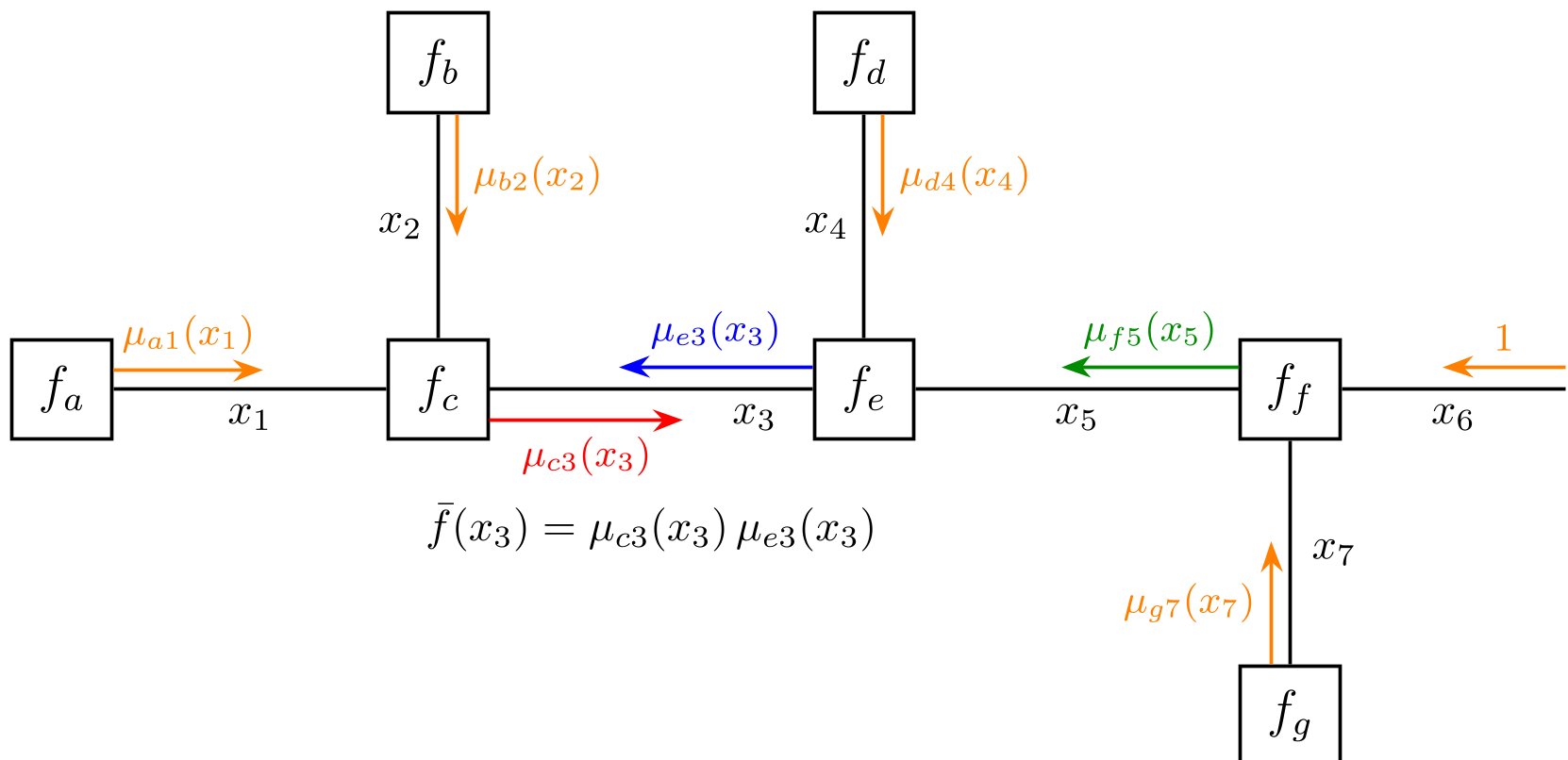 图 2:因子图结构:将复杂的统计模型转化为可并行化的计算网络。
图 2:因子图结构:将复杂的统计模型转化为可并行化的计算网络。
响应式 (Reactive) 的奥秘
通过引入 RxInfer 这种响应式编程范式,推理过程变成了“事件驱动”:
- 只有当传感器数据变化时,相关的图路径才会触发更新。
- 当算力下降时,系统可以减少迭代次数,输出一个略显模糊但“依然可用”的估计值。这种性能平滑退化 (Graceful Degradation) 是传统硬编码系统梦寐以求的。
实验与应用:机器人足球协作
以机器人足球队为例,作者展示了 AIF 是如何处理嵌套代理解 (Nested Agents) 的。每一个球员都是一个 AIF 智能体,而整个球队可以被视为一个更高层级的 AIF 智能体,通过共享的感知状态进行异步通信。
- 探索与利用的博弈:EFE (Expected Free Energy) 的目标函数天然包含“风险”和“模糊性”两项。当机器人对球的位置不确定时,它会自发产生“移动以获得更好视角”的行为(主动探索),而无需额外编写探索奖励。
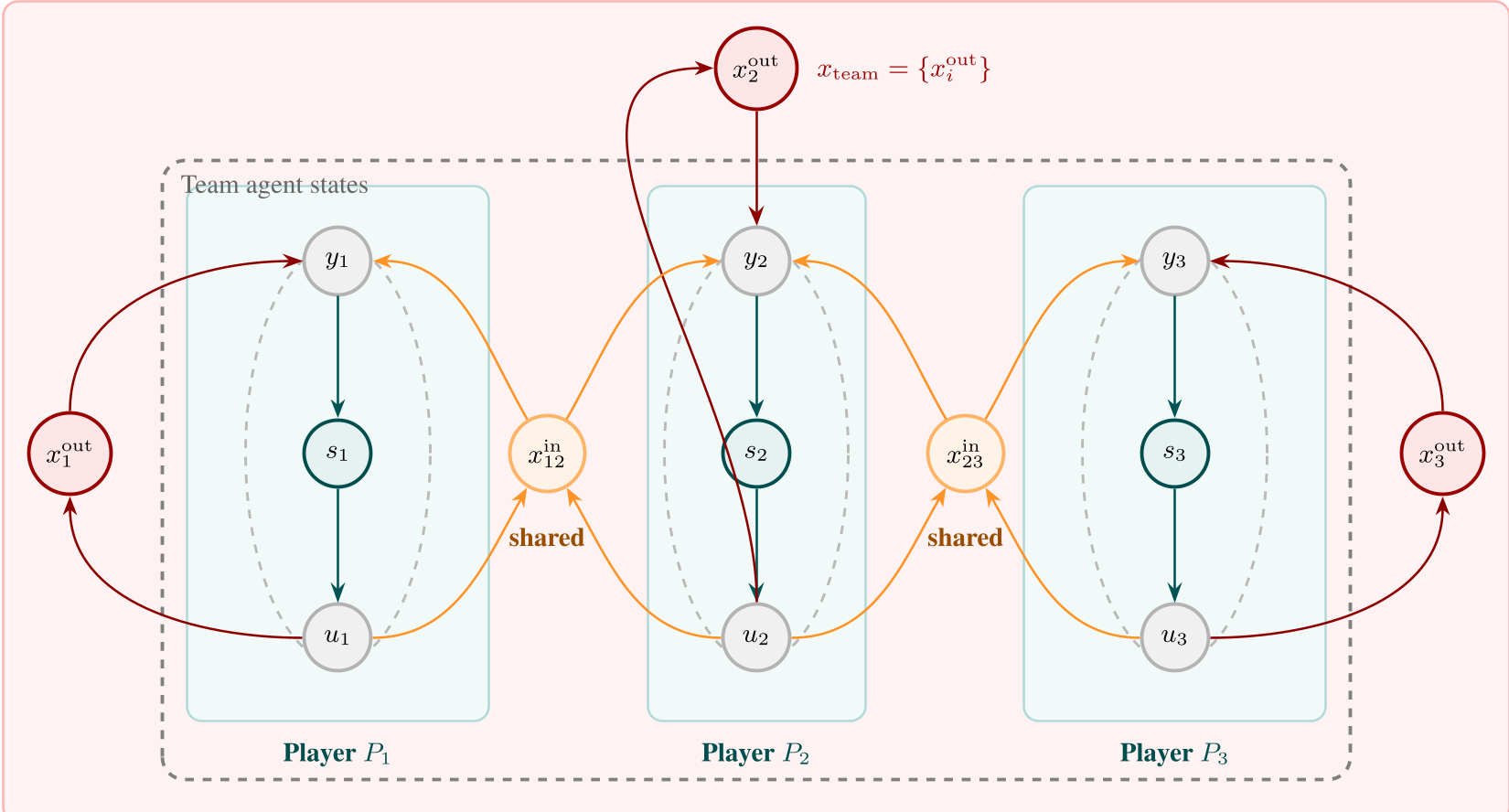 图 3:多智能体嵌套:个体 AIF 智能体如何通过间接耦合形成集体智能。
图 3:多智能体嵌套:个体 AIF 智能体如何通过间接耦合形成集体智能。
深度分析:AIF vs. RL (强化学习)
长期以来,RL 是机器人学习的主流。但本文旗帜鲜明地指出了 RL 的软肋:奖励函数 (Reward Function) 的魔咒。
- 在 RL 中,奖励是外部赋予的,且往往难以处理不确定性。
- 在 AIF 中,偏好被内置于先验分布中,好奇心 (Novelty) 和 目标驱动 (Risk minimization) 在数学上是同源的。
总结与未来展望
尽管该论文并未给出海量的刷榜结果,但其对于物理 AI 架构的思考却极具启发性。它将智能体从传统的“接收输入 -> 处理逻辑 -> 输出控制”模式,转变为“目标驱动的信念更新”过程。
局限性:目前最大的挑战在于大规模工程化的工具链成熟度。虽然 RxInfer.jl 已经起步,但在高性能硬件嵌入式端的实时支持仍处于初级阶段。
启示:未来的物理 AI 设计者或许不应再纠结于如何拼接更多的模块,而应思考如何构建一个更优雅的生成模型,并让变分收敛的法则接管剩下的工作。