本文提出了 Adaptive Auxiliary Prompt Blending (AAPB),一种无需训练的统一框架,通过在扩散过程中动态融合目标提示词(Target Prompt)与辅助锚点提示词(Auxiliary Anchor),解决了稀有概念生成和图像编辑中的语义漂移问题。在 RareBench 和 FlowEdit 数据集上,该方法显著提升了语义准确度(RareBench +8.4 pts)和结构保真度。
TL;DR
扩散模型在处理长尾分布(Rare Concepts)或图像编辑时经常出现“语义漂移”——你想画一只“折纸猫”,它却给了你一只普通的猫。本文提出的 Adaptive Auxiliary Prompt Blending (AAPB) 通过数学推导出的自适应系数,在每个去噪步实时平衡目标提示词与辅助锚点,实现了无需训练、逻辑严密的生成稳定化,在 RareBench 上取得了 SOTA 表现。
为什么要研究这个:长尾分布的“重力”
扩散模型在训练时,常见概念(如“猫”、“狗”)的数据量远超稀有组合(如“戴面具的章鱼”)。这种不平衡会导致模型学习到的分数函数(Score Function)在稀有区域约束不足。在采样过程中,图像特征会像受到重力一样,不自觉地向高密度、常见的模态漂移。
前人的做法(如 R2F)通常是“生拉硬拽”:在某些特定的时间步强制切换到常见概念的提示词。但这种方法有两个致命伤:
- 启发式依赖:需要人工设定什么时候切换,对不同模型不通用。
- 不连续性:提示词的切换在语义空间是跳跃的,容易产生组合伪影。
核心机制:基于 Tweedie 恒等式的闭式解
AAPB 的核心直觉是:既然我们知道模型会漂移,能不能通过数学公式精确计算出每一时刻该补偿多少?
1. 统一框架
作者将稀有概念生成和图像编辑统一在一个框架下:
- 稀有生成:目标 (稀有) + 锚点 (同类常见概念)。
- 图像编辑:目标 (编辑后) + 锚点 (原图提示词)。
2. 闭式 adaptive 系数
通过最小化目标分数函数与融合分数函数之间的距离,并利用 Tweedie's Formula(将图像域的去噪损失转化为分数空间的 损失),作者导出了最优系数:
这个公式的物理含义是:在每个时间步,根据当前噪声状态 ,自动投影目标提示词的残差到锚点方向上,动态决定稳定信号的强度。
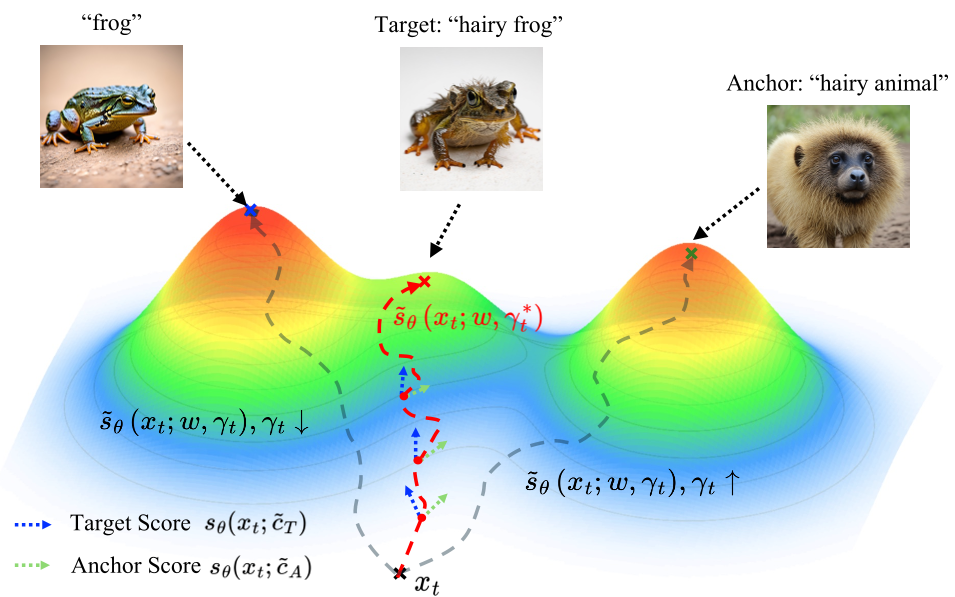 图 1:AAPB 通过自适应修正 ,让去噪轨迹重新对齐目标提示词。
图 1:AAPB 通过自适应修正 ,让去噪轨迹重新对齐目标提示词。
实验战绩:全线飘红的对齐精度
稀有概念生成 (RareBench)
在涵盖属性、形状、纹理等 8 个类别的评估中,AAPB 将平均对齐准确率从 SD3.0 的 61.5% 提升到了 84.1%,超越了之前最强的基线 R2F。
 图 3:在 RareBench 上的定性对比。AAPB 能够生成如“甜甜圈形状的火车”这种高难度稀有概念,而其他模型往往崩坏或生成常规火车。
图 3:在 RareBench 上的定性对比。AAPB 能够生成如“甜甜圈形状的火车”这种高难度稀有概念,而其他模型往往崩坏或生成常规火车。
图像编辑 (FlowEdit Benchmark)
在图像编辑场景下,AAPB 的优势在于“结构保持”。通过将原图提示词作为锚点,它在执行编辑指令(CLIP-T)的同时,显著降低了图像畸变(DreamSim 误差降低至 0.155)。
 图 4:相比 FlowEdit,AAPB 在修改目标(如将棕熊变为北极熊)时,能更完美地保留背景和姿态。
图 4:相比 FlowEdit,AAPB 在修改目标(如将棕熊变为北极熊)时,能更完美地保留背景和姿态。
深度洞察:为什么自适应比固定好?
消融实验揭示了一个有趣的现象:最佳的融合权重是随时间变化的。
- 在图像编辑中, 随时间步逐渐饱和,说明后期对原图结构的依赖度更高(见原文 Fig 9)。
- 在稀有生成中, 保持相对稳定,因为模型全程都需要锚点来防止特征坍缩(见原文 Fig 10)。
这解释了为什么之前固定比例的方法在不同任务间难以迁移——因为它们的“最佳点”根本不在同一条水平线上。
局限性与展望
尽管 AAPB 在语义对齐上表现优异,但它依然受限于底层文本编码器(如 CLIP)的组合性瓶颈。当提示词中包含极其复杂的多个属性绑定时(如:“老虎条纹的松树靠在一只戴假发的章鱼上”),模型偶尔仍会出现属性泄露(Attribute Leakage)。
未来的研究方向可能在于如何将这种分数空间的投影技术与更强大的多模态大模型(如 Llama-3-Vision)结合,从表征层面彻底解决组合性生成的难题。
总结
AAPB 提供了一个优雅、直接且具有坚实数学基础的扩散模型增强方案。它告诉我们:面对模型自带的偏见,硬性的干预不如动态的对齐。 对于想要在生产环境中提升生成模型鲁棒性的开发者来说,这是一种极具性价比的 Plug-and-Play 策略。