本文提出了 POISE,一个基于 LLM Agent 的闭环自动发现框架,用于自主探索大语言模型的强化学习(LLM-RL)策略优化算法。POISE 通过结构化的演化搜索,从 GRPO 基线出发自动发现了包括解析方差缩放(Analytic-variance scaling)和有效性掩码(Validity masking)在内的先进机制,在数学推理任务上将 AIME25 的 pass@32 从 26.7% 提升至 43.3%。
#从 AI 助手到 AI 科学家:POISE 框架开启 LLM-RL 算法自主演化新纪元
TL;DR
在强化学习(RL)成为大模型后训练(Post-training)核心技术的今天,复旦大学等机构的研究者跳出了“人工调优”的藩篱,推出了 POISE 框架。它不仅是一个自动调参工具,更是一个能写代码、做实验、写反思的“AI 科学家”。POISE 成功在数学推理任务上将 GRPO 算法进行了深度进化,在 AIME 25 榜单上实现了惊人的性能跨越。
背景定位
在学术坐标系中,POISE 属于 自动化科学发现(AI for Science / Automated Research) 的前沿探索。它不仅仅实现了算法的 SOTA 刷榜,更重要的是它在方法论上引入了“认知演变”的概念,让模型能像人类科学家一样从失败的实验中总结“认知(Epistemic)”并指导下一步实验。
痛点与动机:为什么算法发现这么难?
传统的强化学习算法开发是一个极其痛苦的过程。研究员需要反复修改 Loss 函数、通过消融实验验证优势估计(Advantage Estimation)的有效性,每一个微小的设计(如 PPO 中的 Clipping 比例)都可能导致训练动态的剧烈波动。
现有自动化方法(如简单的程序合成)往往缺乏证据驱动的迭代:
- 动态耦合:算法逻辑与实时训练轨迹(Training Dynamics)深度绑定。
- 证据浪费:前一次实验失败的原因往往没有被结构化地记录并用于指导下一次实验。
- 实现鸿沟:从抽象的数学想法到可运行的分散式训练代码存在极大的实现难度。
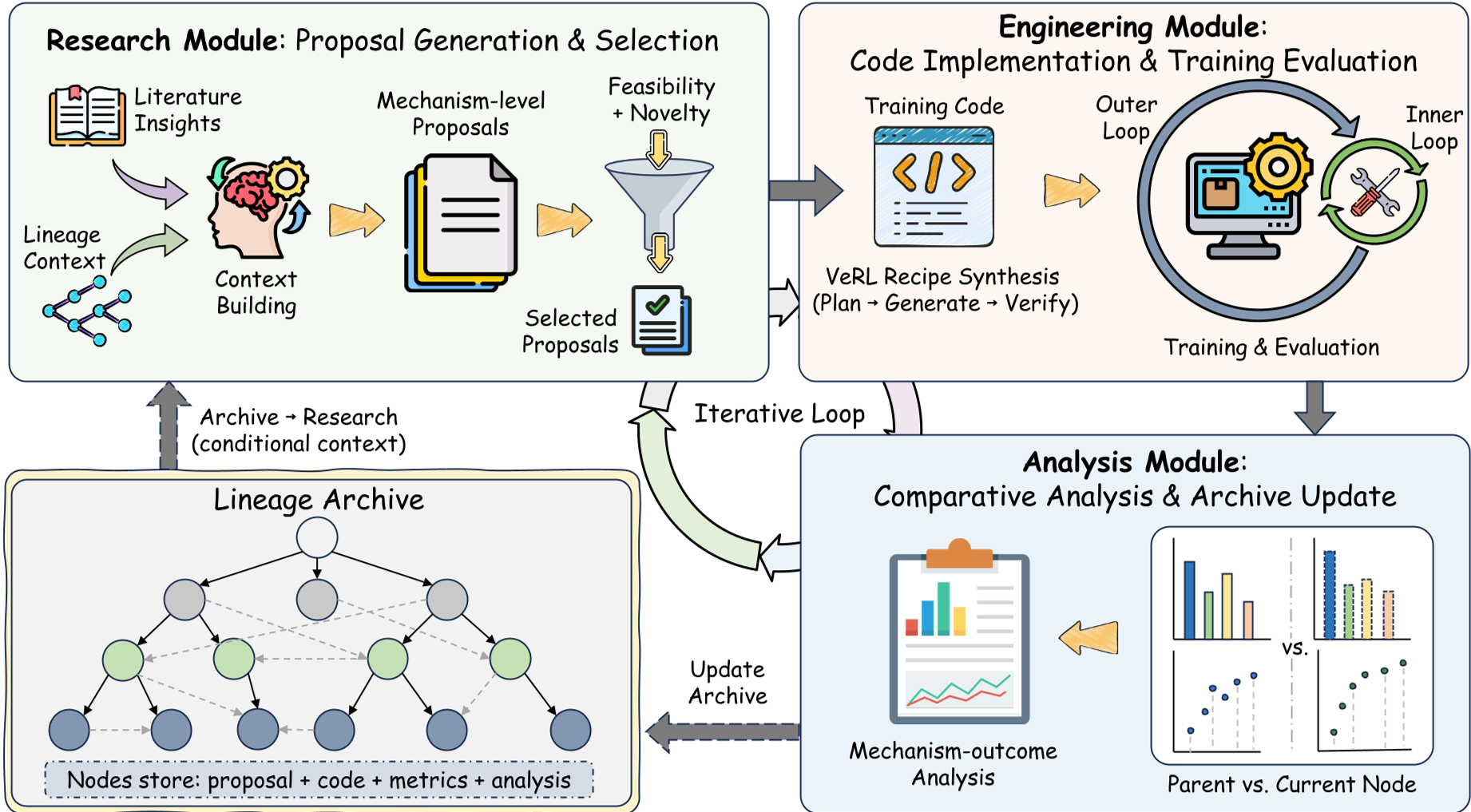
POISE 核心机制:认知演化搜索
POISE 将算法发现建模为一个闭环过程,核心逻辑在于三阶段循环:
1. 提案生成 (Phase I)
POISE 不做无脑的随机搜索,而是利用一个 基于谱系的档案 (Genealogically Linked Archive)。它会利用一个“采集函数”平衡当前的 Pareto 最优算法和具有潜在“进化潜力”的算法。
2. 实现与验证 (Phase II)
LLM 将抽象的数学公式自动转化为基于 VERL 等高性能 RL 框架的代码。系统内置了“边界检查”,确保生成的代码符合训练接口规范。
3. 反思分析 (Phase III)
这是 POISE 最具“科学家精神”的一步。在实验结束后,LLM 会对比实验数据(如 KL 发散、奖励曲线),分析“为什么这个改动生效了”或“为什么会导致收敛失败”,并将这些自然语言反思记录在案。
核心突破:VM-AV-GRPO 算法的诞生
通过 64 轮迭代,POISE 发现了一个名为 VM-AV-GRPO 的强力变体。
- 解析方差缩放 (Analytic-variance scaling):在奖励极其稀疏的场景下(如极难的数学题),传统的批次方差估计会因为样本太少而失效。POISE 提出利用奖励分布的理论解析方差来锚定优势缩放,增强了稀疏成功信号的强度。
- 有效性掩码 (Validity Masking):POISE 在反思中发现,有时模型会因为“格式正确但逻辑错误”而获得错误的奖励信号。它自动设计了一个掩码,将格式验证与逻辑验证分离,确立了严格的梯度等级:
无效格式 << 格式对但逻辑错 < 全对。
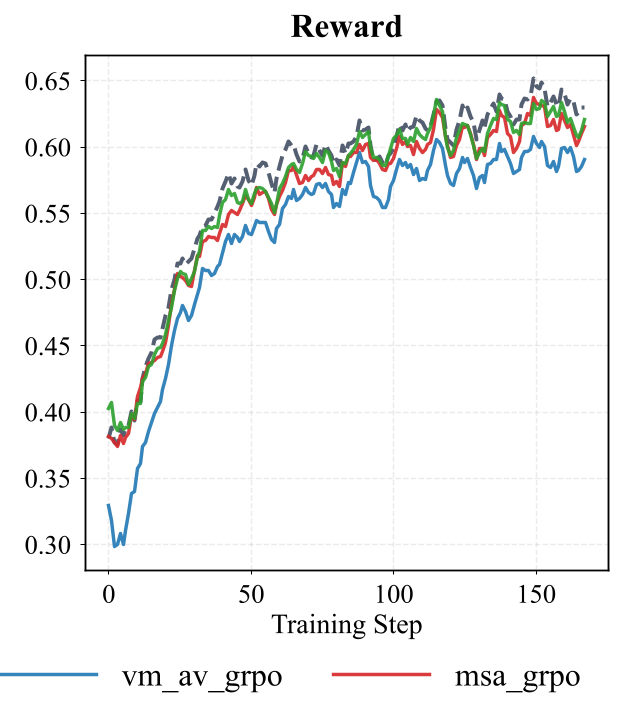 上图显示,进化后的变体在 Entropy(熵)控制和 Reward(奖励)获取上明显比基线 GRPO 更稳定。
上图显示,进化后的变体在 Entropy(熵)控制和 Reward(奖励)获取上明显比基线 GRPO 更稳定。
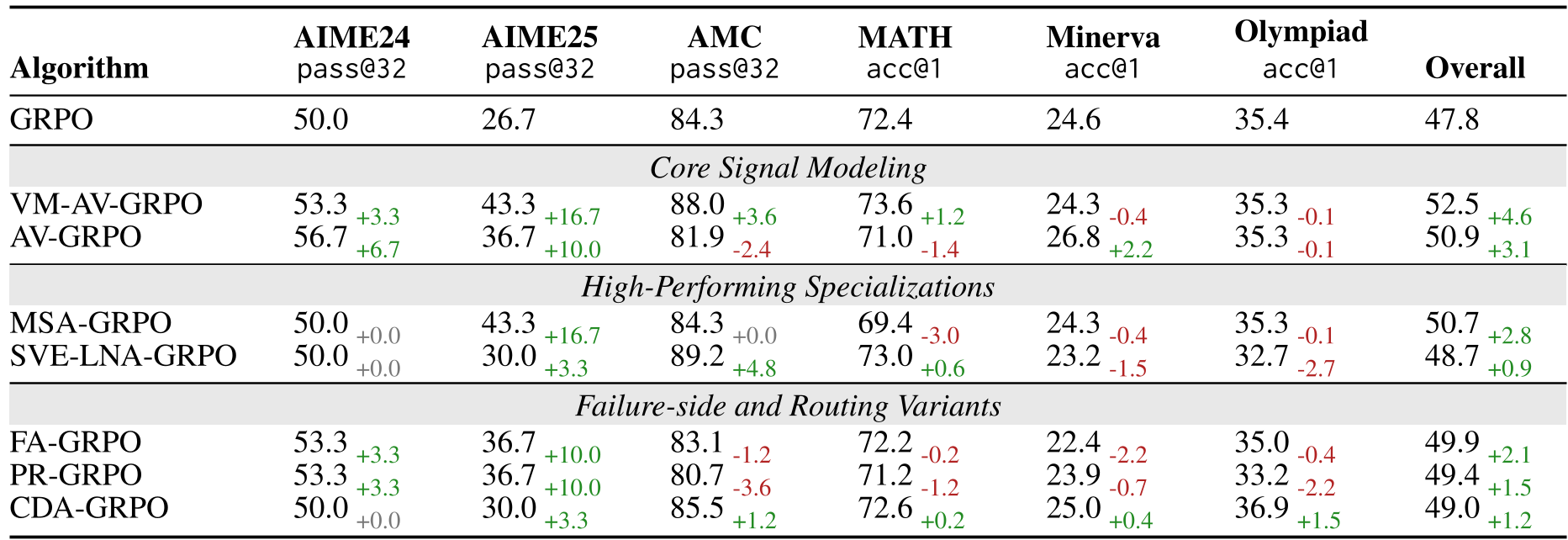
实验战绩与深度洞察
在 AIME25 等最具挑战性的数学竞赛题目中,POISE 发现的机制展现了统治力:
| 算法 | AIME25 (Pass@32) | 加权总分 | | :--- | :--- | :--- | | GRPO (基线) | 26.7% | 47.8 | | VM-AV-GRPO (POISE 发现) | 43.3% | 52.5 |
控制实验:想要更短的推理?
POISE 还展示了极强的“可引导性”。当研究者给 AI 下达“在保持精度的同时缩短回复长度”的指令时,POISE 自动摸索出了“正确性优先的分阶段压缩”策略,实现了推理长度减少 29.1% 且性能不降反升。
深度思考与结论
POISE 的成功带给我们三点启示:
- 从“点”到“线”:算法设计不再是孤立的尝试,而是可以被结构化记录和演进的“知识谱系”。
- 解耦是王道:POISE 总结出的核心原则——将格式信号、逻辑信号、效率信号解耦(Decoupling),是处理复杂 RL 任务的钥匙。
- 负向证据的价值:看到“错误”是如何被修正的,比看到“正确”的结果对算法社区更有意义。
虽然 POISE 目前主要集中在数学推理领域,但其方法论具备极强的迁移潜力。未来,我们或许会看到 AI 为自动驾驶、芯片设计等更广阔的领域自主设计强化学习算法。
局限性分析:当前的演化搜索仍然非常消耗算力(毕竟要跑 64 遍完整的模型训练),且因果解释虽然符合直觉,但尚需更严格的数学论证。但这丝毫不影响它是通往“自主 AI 实验室”的重要一步。