The paper presents a temporally grounded case study of Large Language Model (LLM) reasoning during the early stages of the 2026 Middle East conflict. By using a crisis that occurred after the training cutoffs of current frontier models (GPT-4, Claude 3.5, etc.), the authors evaluate "fog of war" reasoning and forecasting capabilities while strictly mitigating data leakage.
TL;DR
Researchers from MBZUAI and the University of Maryland have conducted a pioneering study on how AI navigates geopolitical uncertainty. By feeding SOTA models (like GPT-5.4 and Claude 3.5) real-time data from the 2026 Middle East conflict—events that occurred after the models were trained—the team bypassed the "data leakage" trap. The result? AI is surprisingly good at "Realism," prioritizing structural incentives over political noise, yet remains vulnerable to the unpredictability of multi-actor diplomacy.
The "Data Leakage" Problem
If you ask an AI to "predict" the outcome of the Cuban Missile Crisis, it isn't reasoning; it's remembering. Most LLM benchmarks suffer from this. This study solves it by looking at a "live" conflict. The authors define this as the Fog of War: a realm of uncertainty where information is incomplete, signals are contradictory, and the "ground truth" hasn't happened yet.
Methodology: The Temporal Node Framework
The researchers reconstructed 11 critical moments (T0 to T10) from the Feb-March 2026 escalation. At each node, models received only the news reports available at that exact time.
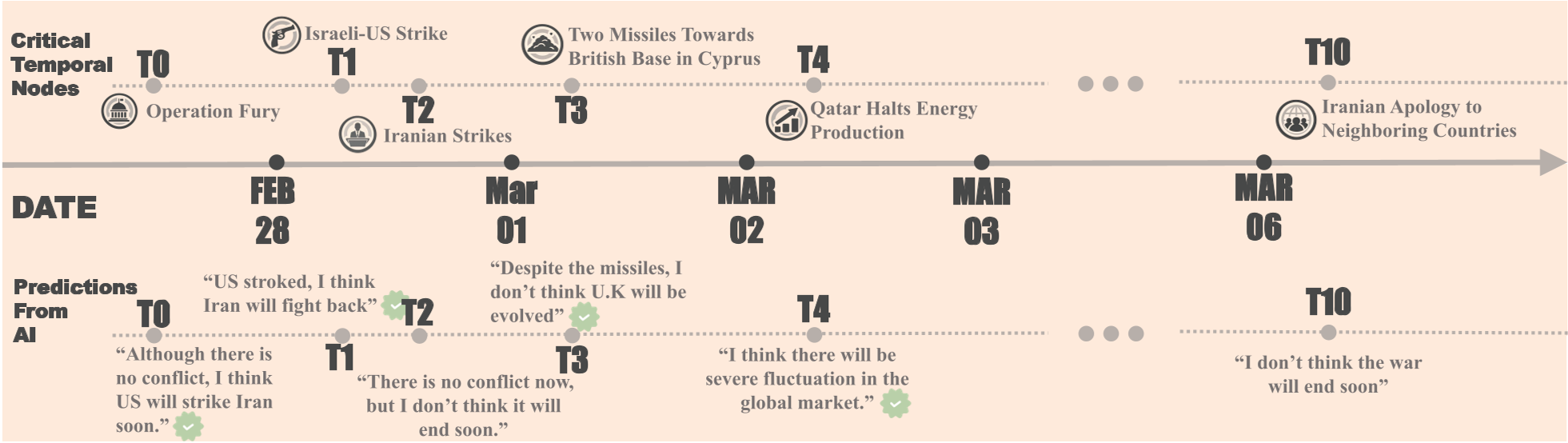 Figure 1: The 11 temporal nodes, tracking the transition from strategic posturing to kinetic warfare.
Figure 1: The 11 temporal nodes, tracking the transition from strategic posturing to kinetic warfare.
Key Insights: Why AI "Thinks" Like a Realist
The study reveals several fascinating traits of machine reasoning in high-stakes environments:
1. The "Credibility Trap" and Strategic Sunk Costs
Models like Claude-4.6 and GPT-5.4 didn't just look at what leaders said; they looked at what they shifted. When evaluating the likelihood of U.S. strikes (Node T0), models recognized that the massive scale of military deployment created a "point of no return." They reasoned that withdrawing without concessions would destroy American credibility—a concept deeply rooted in international relations theory.
2. Resistance to Rhetoric
Models were surprisingly immune to inflammatory language. Even when Iranian officials threatened "regional apocalypse," the models remained grounded, predicting calibrated, military-on-military retaliation rather than the "indiscriminate bombing" suggested by the rhetoric.
3. The "Succession" Logic
When a leadership vacuum occurred in Iran (Node T2), models correctly identified that an untested successor (Mojtaba Khamenei) would likely escalate to prove internal legitimacy to hardliners, rather than pursuing immediate peace.
Where AI Fails: The Ambiguity Gap
The quantitative data shows a clear divide in performance across different reasoning "Themes":
 Figure 2: Performance metrics across the four conflict themes.
Figure 2: Performance metrics across the four conflict themes.
- Theme III (Economic Shockwaves): Accuracy 79%. AI excels at tracing how a blocked Strait of Hormuz impacts global LNG prices. These are structured, causal chains.
- Theme IV (Regime Dynamics): Accuracy 67%. AI struggles with the "messiness" of domestic politics and the strategic ambiguity of internal signaling.
Critical Perspective: Limits of the "Mosaic" Doctrine
One of the paper's most profound takeaways is how AI views the end of conflict. Models warned against the assumption that "leadership decapitation" leads to easy victory. Instead, they highlighted the "Mosaic" Doctrine: when a central command is destroyed, local military units may act autonomously, creating a decentralized violence that is much harder for a diplomat to "switch off."
Conclusion
This paper serves as an archival snapshot of machine intelligence at a specific moment in human history. It proves that while AI can be a powerful tool for structural analysis, it is not a crystal ball. Its greatest strength is its "Realist" bias—its ability to ignore the noise of political signaling and focus on the hard physics of military and economic power.
Future Outlook: As LLMs are increasingly integrated into decision-supporting systems, understanding their domain-specific blind spots (like multi-actor signaling) will be critical to preventing accidental escalation.