This paper introduces NUMINA, a training-free "identify-then-guide" framework designed to correct numerical misalignments in text-to-video (T2V) diffusion models. By extracting and refining latent layouts from attention heads, it achieves state-of-the-art counting accuracy across various DiT-based models like Wan2.1 and CogVideoX.
TL;DR
Text-to-Video (T2V) models often "fail at math," struggling to generate the exact number of objects requested in a prompt. NUMINA is a training-free framework that identifies numerical discrepancies in the model's latent space and uses a refined attention-guidance mechanism to ensure that what you see matches what you counted. It boosts counting accuracy by up to 7.4% on SOTA models like Wan2.1 without requiring any retraining.
Problem & Motivation: Why Models Can't Count
Even the most advanced T2V models (like Sora or Wan2.1) prioritize visual fidelity and motion over strict numerical alignment. The authors identify two core killers:
- Semantic Weakness: Unlike nouns or verbs, numerical tokens (e.g., "four") result in diffuse, low-contrast cross-attention maps. The model "knows" there are cats, but doesn't "know" exactly where the fourth one should be.
- Instance Ambiguity: In the heavily downsampled spatiotemporal latent space of Diffusion Transformers (DiT), individual object boundaries become blurred, making it easy for the model to "merge" or "ghost" instances.
Previous "fixes" relied on Seed Search (trial and error) or Prompt Enhancement, both of which are unreliable for high-count scenarios (e.g., asking for 8 objects).
Methodology: The Identify-then-Guide Paradigm
NUMINA operates in two distinct phases that tap into the model's internal "latent intuition" before the video is even fully rendered.
Phase 1: Numerical Misalignment Identification
The framework performs a "pre-token" denoising step to extract a Countable Layout. It doesn't just average all attention; it dynamically selects the most instance-discriminative self-attention heads (using PCA and edge clarity scores) and the most text-concentrated cross-attention heads. By fusing these, it creates a map where objects are represented as distinct, countable clusters.
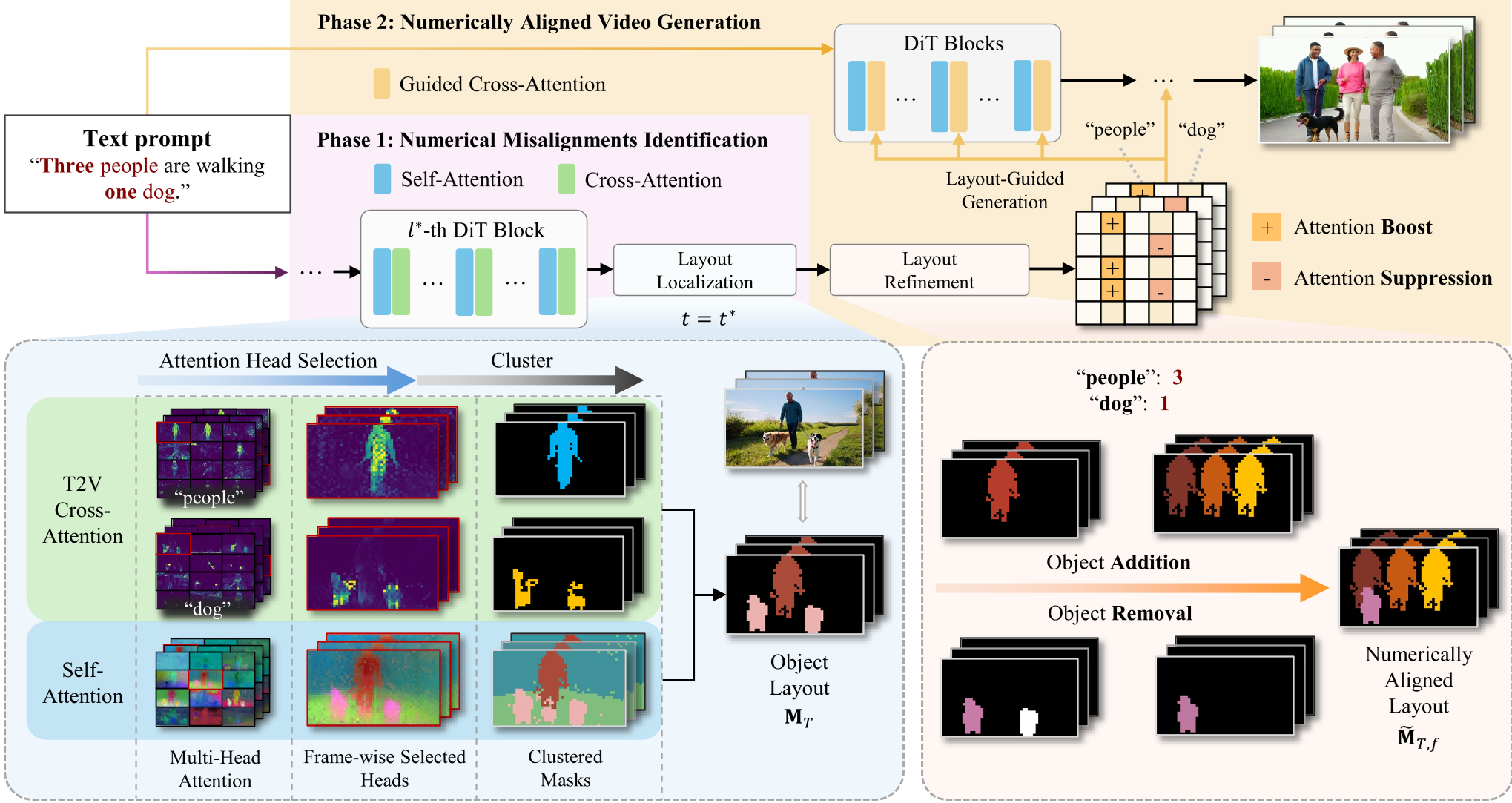 Figure 1: The two-phase pipeline: Identify the count error, then guide the re-synthesis.
Figure 1: The two-phase pipeline: Identify the count error, then guide the re-synthesis.
Phase 2: Refinement and Guided Generation
Once a discrepancy is found (e.g., the prompt asked for 3 cats but the layout only shows 2), NUMINA intervenes:
- Object Removal: Erases the smallest, least significant region to minimize structural disruption.
- Object Addition: Inserts a "template" (either a circle or a copy of an existing instance) into the layout using a heuristic cost function that balances spatial logic and temporal stability.
- Attention Modulation: During the final generation, the model's cross-attention is "boosted" in the new areas and "suppressed" in the removed ones.
Experiments & Results
The authors introduced CountBench, a rigorous benchmark with 210 prompts evaluating counts from 1 to 8 across multiple categories.
Quantifiable Gains
NUMINA consistently outperformed specialized baselines. Notably, it allowed a "small" 1.3B parameter model to achieve a counting accuracy of 49.7%, effectively beating the baseline performance of a much larger 5B model (47.8%).
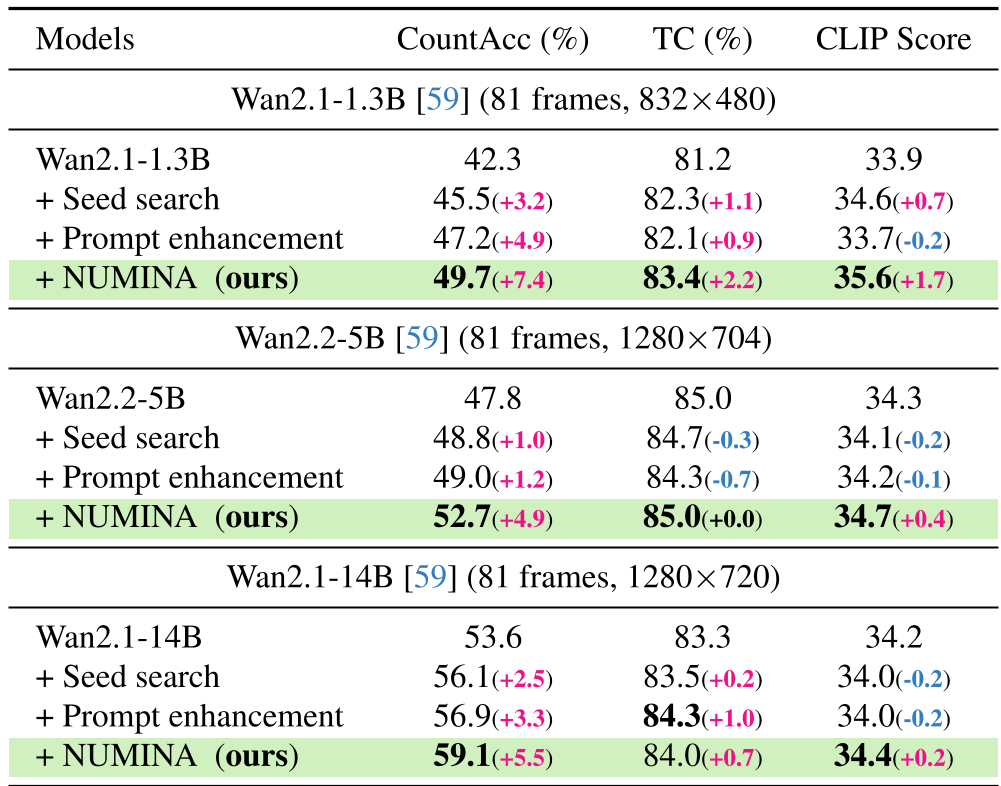 Table 1: Performance comparison across different model scales. NUMINA provides the highest gain in CountAcc and CLIP scores.
Table 1: Performance comparison across different model scales. NUMINA provides the highest gain in CountAcc and CLIP scores.
Visual Evidence
Qualitative results show that while commercial models often lose track of one or two objects in complex scenes (like "three cyclists and three goats"), NUMINA maintains a perfect tally while keeping the motion fluid and the style consistent.
 Figure 2: Comparisons against advanced commercial models show NUMINA's superior ability to respect specific numerals.
Figure 2: Comparisons against advanced commercial models show NUMINA's superior ability to respect specific numerals.
Critical Analysis & Conclusion
NUMINA's greatest strength is its training-free nature. It proves that the "intelligence" to count is already latent within these models; it just needs a more structured way to express itself. By extracting a discrete layout and using it as a guidance signal, NUMINA bridges the gap between fuzzy neural representations and hard cardinal constraints.
Limitations: The method currently relies on raw attention heads, which can sometimes over-segment an object (e.g., treating a cat's head and body as two separate counts). Future iterations might benefit from integrating "holistic perceptual grouping" to better define what constitutes a single "instance."
In conclusion, NUMINA represents a significant step towards precision-controllable T2V, making these models viable for instructional videos and data-driven visualizations where "close enough" is not an option.