本文提出了 AnchorRefine,一种用于视觉-语言-动作(VLA)模型的层次化动作生成框架。该方法通过将动作建模分解为轨迹锚点(Trajectory Anchor)和残差修正(Residual Refinement),在 LIBERO 和 CALVIN 任务中显著提升了模型在精密操作中的成功率。
TL;DR
在机器人操作领域,视觉-语言-动作(VLA)模型虽强,却常在“最后几厘米”的抓取微调上栽跟头。AnchorRefine 提出了一种“粗到精”的层次化策略:它先定一个粗略的运动“锚点”,再通过一个精细的“残差修正”模块补足误差。这种设计直接将 LIBERO-Long 的模拟成功率拉升了 7.8%,并在真机实验中表现出极强的鲁棒性。
背景定位:为什么 VLA 模型总是“手抖”?
当前的机器人策略(如 OpenVLA、RT-2)倾向于在一个大一统的动作空间里预测所有自由度的数值。这种模式存在一个致命的**动作尺度不匹配(Action-scale Mismatch)**问题:
- 宏观运输:手臂大范围挥动,数值变动剧烈。
- 微观修正:接近物体时的几毫米位置微调,数值极小。 在优化时,模型往往会被巨大的运输动作信号“带偏”,忽略了那些决定成败的精密修正信号。这就像是一个人用大锤绣花,力量有余而精度不足。
核心直觉:锚点与残差的协同设计
受到人类“先快速接近,再慢速对齐”的生物特性启发,作者设计了 AnchorRefine。其核心是将动作向量 分解为两个部分: 其中, 是由 Trajectory Anchor Planner 生成的全局基准,而 是由 Residual Refine Module 生成的局部补偿。
1. 轨迹锚点规划器 (Phase 1)
锚点并不需要手工标注,而是通过第一阶段训练自然涌现。它负责吸收数据中最大、最连贯的运动特征,形成一个稳定的“运动骨架”。
2. 残差修正模块 (Phase 2)
在锚点固定后,模型专门学习如何预测“锚点预测不足”的部分。实验证明,残差空间的目标值更集中(低方差、小范数),比原始动作空间更容易收敛。
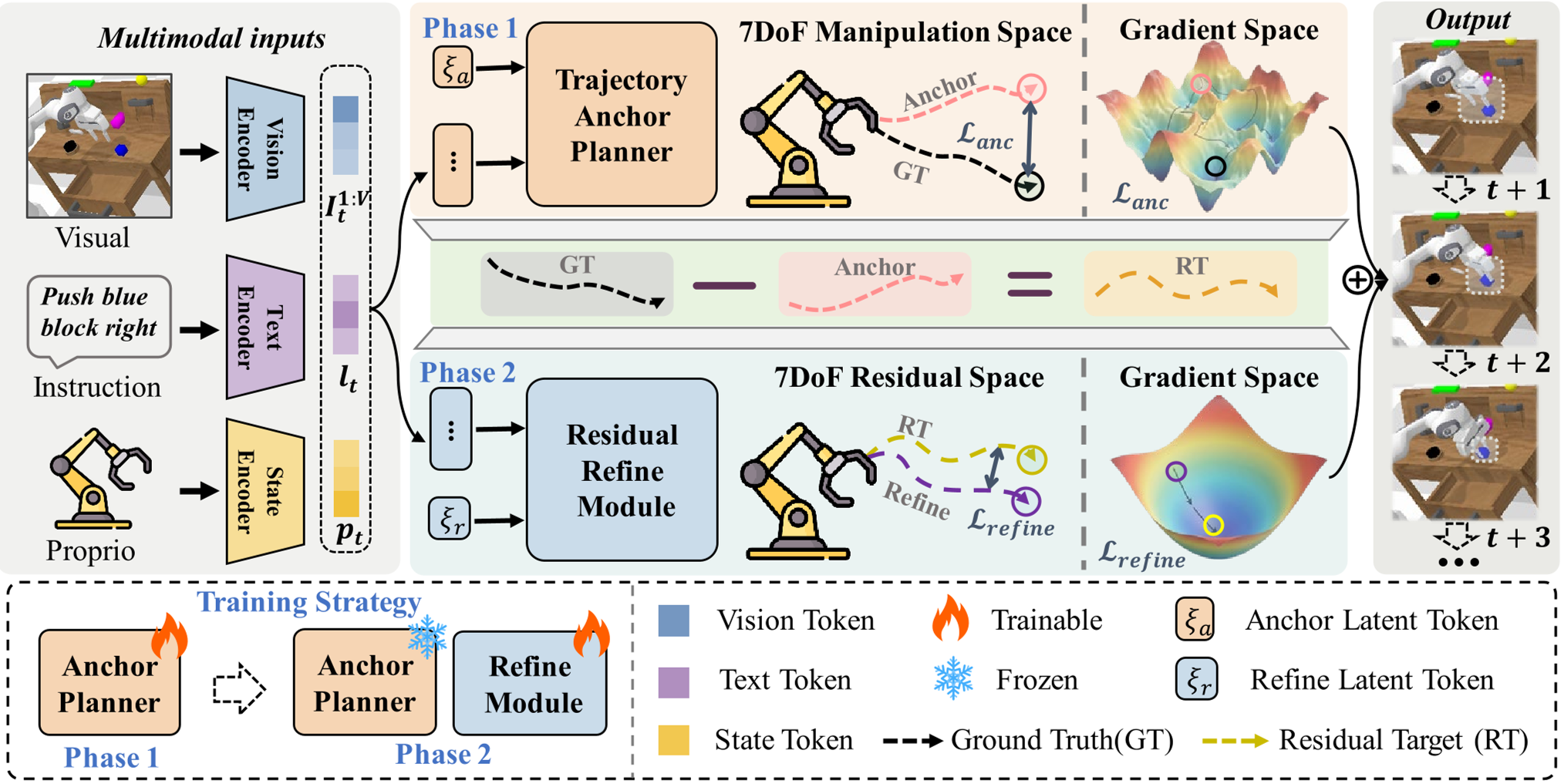 图 1:AnchorRefine 架构图,展示了从多模态 Token 到锚点与残差分支的分解流程。
图 1:AnchorRefine 架构图,展示了从多模态 Token 到锚点与残差分支的分解流程。
决策感知型夹持器修正 (Gripper Refinement)
作者发现 88% 的失败来源于夹持器(Gripper)控制错误。与机械臂平滑的运动不同,夹持器开关是离散且有明确边界的。AnchorRefine 引入了决策感知机制,不再简单地做回归,而是根据锚点的预测信心动态调整修正强度,确保抓取时机“稳、准、狠”。
实验战绩:多场景下的降维打击
AnchorRefine 展现出了极高的通用性,能无缝集成到基于常规回归(如 GR-1)或扩散策略(如 X-VLA)的模型中。
- CALVIN ABC→D 测试:在最难的 5 连环任务中,成功率稳步提升,平均序列长度显著增加。
- 真机验证:在“推笔入筒”、“木块堆叠”等极度依赖接触精度的任务中,成功率比基线模型有质的飞跃。
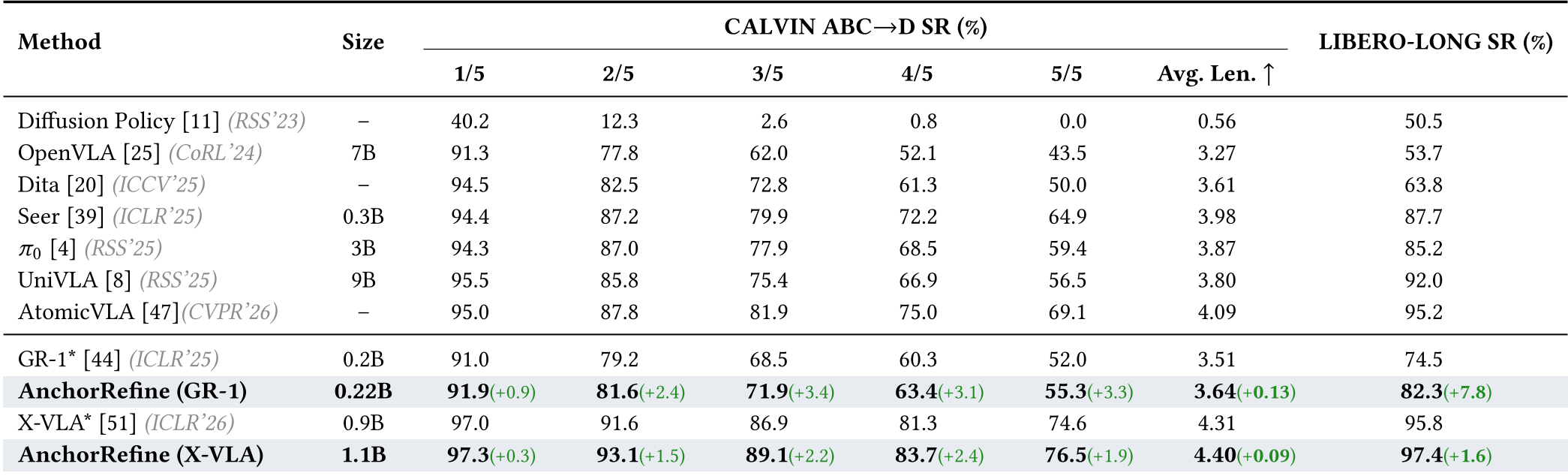 表 1:AnchorRefine 在 LIBERO-LONG 和 CALVIN 分项指标上全面超越 SOTA。
表 1:AnchorRefine 在 LIBERO-LONG 和 CALVIN 分项指标上全面超越 SOTA。
技术洞察与总结
AnchorRefine 的成功不仅仅是因为堆叠了参数量(消融实验证明,单纯增加模型深度并不能达到同等效果),而是源于对操作任务异质性的深刻理解。
核心启示:
- 解耦优于统一:在大模型时代,虽然端到端是趋势,但在动作生成层面,适当的物理层级分解(如锚点+残差)能显著降低神经网络的学习难度。
- 残差空间更鲁棒:在更紧致的目标空间进行优化,是提升 Embodied AI 系统稳定性的金钥匙。
局限性预测:目前的修正机制是非自适应的,未来若能根据环境反馈频率实时动态调整修正权重,该系统的天花板将进一步提升。