AniMatrix is an anime video generation model that shifts the optimization target from physical realism to "artistic correctness." Developed by Tencent HY Team, it utilizes a dual-channel conditioning interface and a progressive training pipeline to outperform current SOTA models like Seedance-Pro 1.0 in prompt understanding (+22.4%) and artistic motion (+16.9%).
TL;DR
AniMatrix is a breakthrough in anime video generation that abandons the pursuit of physical realism. By redefining "correctness" as adherence to directorial intent rather than Newton's laws, and using a specialized Production Knowledge System, it achieves industry-leading results in expressive motion and prompt following, serving over 60 professional studios.
The "Physics Bias" Problem
Most modern video generators (like Sora or Kling) are "World Simulators." They are trained on millions of hours of real-world footage to learn that "gravity pulls things down" and "objects shouldn't morph."
In the world of anime, this is a bug, not a feature. Professional animation relies on intentional physics violations:
- Smear Frames: Distorting a limb into a blur to convey speed.
- Squash-and-Stretch: Changing an object's volume during impact.
- Chibi Shifts: Abruptly changing character proportions for comedic effect.
When you fine-tune a physics-biased model on anime, it tries to "fix" these artistic choices, leading to motion that is technically smooth but artistically "flat."
Methodology: The Three Pillars of Artistic Correctness
1. The Production Knowledge System (PKS)
Instead of simple captions like "a girl runs," the authors developed AniCaption, an AI that thinks like a director. It labels videos based on a 4-axis taxonomy:
- Style (S): Rendering tradition (e.g., Miyazaki vs. Shinkai).
- Motion (M): Performance semantics (e.g., "Combat Dash" vs. "Daily Walk").
- Camera (C): Cinematographic choreography (Dolly zooms, pan/tilts).
- VFX (V): Symbolic language (Speed lines, "Vein Pop" anger marks).
2. Dual-Channel Architecture
AniMatrix solves the "instruction dilution" problem by splitting the prompt.
- Path 1 (Cross-Attention): Handles free-form narrative (mood, character descriptions).
- Path 2 (AdaLN Modulation): Enforces global production tags (Shot type, Style) at every layer, ensuring hard constraints are never ignored by the model.
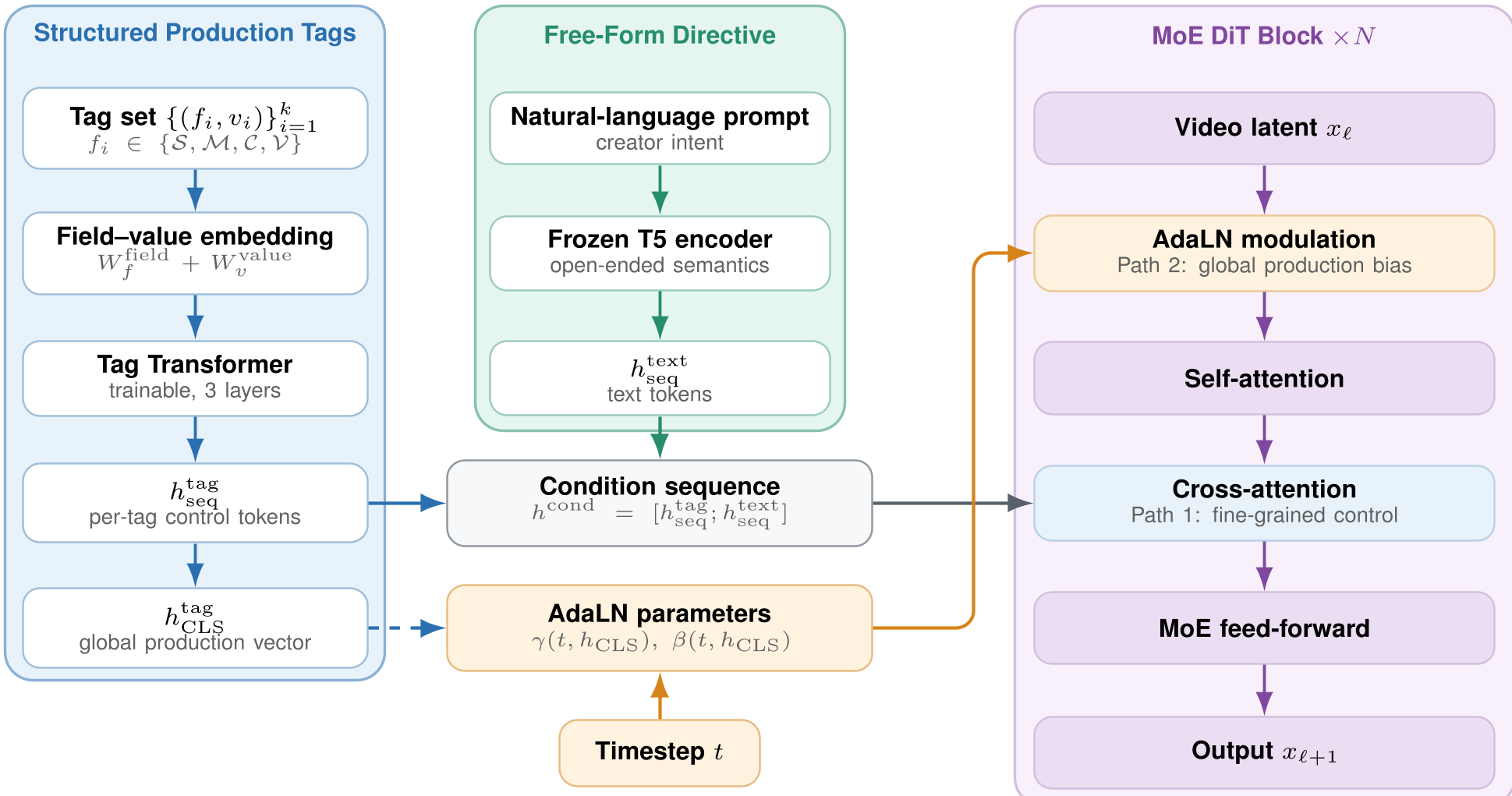 Figure 1: The Dual-Channel architecture separating structured tags from narrative text.
Figure 1: The Dual-Channel architecture separating structured tags from narrative text.
3. Progressive Curriculum Learning
To prevent the model from collapsing when exposed to extreme anime motion, the authors used a Style–Motion–Deformation Curriculum. The model starts by learning "near-physical" motion and gradually graduates to "extreme artistic expression."
Experiments & Results
AniMatrix was pitted against Seedance-Pro 1.0 and Wan 2.2 in a rigorous test scored by professional animators.
| Metric | Seedance-Pro | Wan 2.2 | AniMatrix (Ours) | | :--- | :---: | :---: | :---: | | Prompt Understanding | 3.12 | 2.93 | 3.82 | | Artistic Motion | 3.26 | 3.05 | 3.81 | | Style Fidelity | 4.15 | 4.05 | 4.39 |
The model dominates in Artistic Motion, proving that its "physics-breaking" training allows for much more dynamic and impactful animation.
 Figure 2: AniMatrix (Top) maintains crisp VFX beams and lunge poses, whereas physics-biased models (Middle/Bottom) struggle with motion blur and deformation.
Figure 2: AniMatrix (Top) maintains crisp VFX beams and lunge poses, whereas physics-biased models (Middle/Bottom) struggle with motion blur and deformation.
Deep Insight: Distinguishing "Art" from "Failure"
One of the paper's most brilliant contributions is Deformation-Aware Preference Optimization. Usually, a model's reward function penalizes "warping." AniMatrix's reward model (the "Judge") is trained to know that a face melting in a horror scene is good (Art), but a face melting because the GPU failed to render a eye is bad (Failure). This establishes a "Quality Boundary" that generic AI models simply cannot see.
Conclusion & Future Work
AniMatrix proves that Artistic Correctness is a trainable objective. By replacing "World Models" with "Director Models," we can create tools that don't just mimic pixels, but understand the craft of animation.
Tencent has already announced AniMatrix-Uni, which will integrate audio (voice acting/music) and character sheets directly into the model, moving from text-to-video to a full-pipeline co-creation system.