AnomalyAgent is a novel agentic industrial anomaly synthesis framework that formulates defect generation as an iterative, tool-augmented sequential decision-making task. By integrating Multimodal Large Language Models (MLLMs) with specialized tools and reinforcement learning, it achieves SOTA results on MVTec-AD, reaching 99.3% image-level and 74.2% pixel-level AP.
TL;DR
Industrial anomaly synthesis finally moves from "one-shot guessing" to "iterative reasoning." AnomalyAgent is the first multimodal agentic framework that treats defect generation as a sequential decision process. By using tool-augmented reinforcement learning (GRPO) and a closed-loop feedback mechanism, it achieves 99.3% image-level AP on MVTec-AD, setting a new benchmark for zero-shot industrial data synthesis.
Problem & Motivation: The "Semantic Drift" in Open-Loop Generation
In the industrial world, defect data is notoriously scarce. While Generative AI (Stable Diffusion, etc.) has provided a way to synthesize "pseudo-defects," existing methods suffer from a fundamental flaw: Open-Loop Generation.
The model takes a prompt, generates a pixel patch, and stops. There is no "self-reflection." If the generated scratch looks like a painting brush stroke or is placed in a physically impossible location (like a crack floating in the air), the model has no way to correct it. Prior SOTA zero-shot methods either rely on handcrafted perturbations (DRAEM) or static prompts, leading to semantic drift and low realism.
Methodology: The "Perception-Reflection-Action" Loop
The authors propose a radical shift: Replace the generator with an Agent. AnomalyAgent uses the Qwen3-VL-4B-Thinking backbone as a brain to coordinate five specialized tools.
1. The Toolset
- PG (Prompt Generation): Translates abstract concepts into localized editing instructions.
- IG (Image Generation): The "hand" that edits the pixels.
- QE (Quality Evaluation): The "critic" that provides a score and textual feedback.
- KR (Knowledge Retrieval): Fetches physical property descriptions (e.g., how brittle shell fractures look).
- MG (Mask Generation): Produces the ground-truth segmentation label.
2. The Training Strategy
The most impressive part of this work is how they train the agent without manual labels. They use Reverse Synthesis: taking a real anomaly image, reconstructing its "normal" version, and then building an N-step trajectory of how to get from normal back to anomaly.
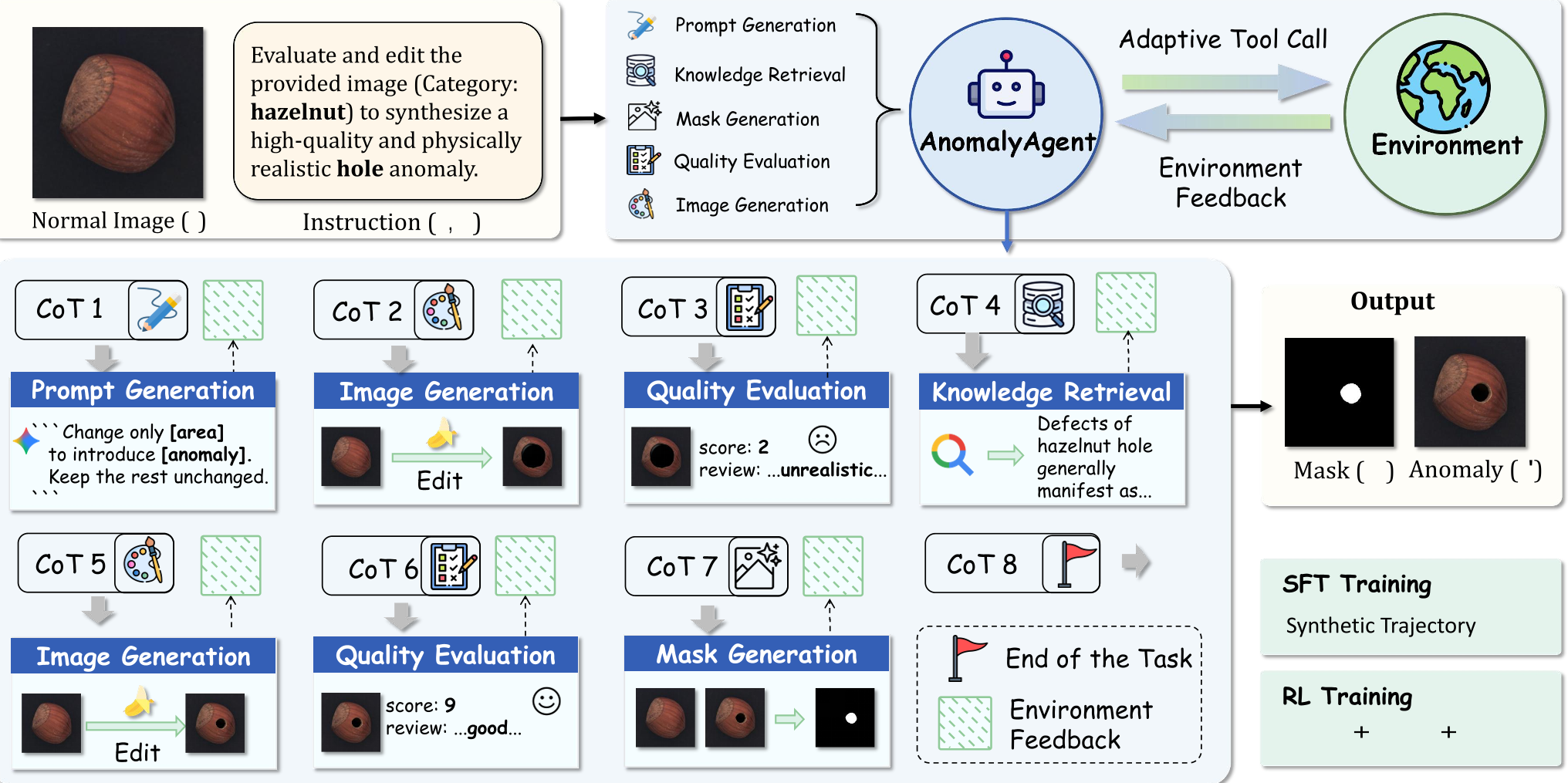
3. Reinforcement Learning (GRPO)
The agent is optimized via Group Relative Policy Optimization (GRPO). Instead of a single reward, it optimizes for three things:
- Task Reward: Is the final image realistic?
- Reflection Reward: Did the agent actually improve the image between turns?
- Behavior Reward: Did the agent follow the correct tool sequence (e.g., PG → IG → QE)?
Experiments & Results: SOTA Performance
AnomalyAgent was tested on the industry-standard MVTec-AD and VisA datasets.
- Localization Accuracy: It reached a mean 98.0 AUC and 74.2 AP at the pixel level, significantly better than GPT-4 or Gemini's image-editing capabilities which lack domain-specific reasoning.
- Downstream Utility: Detectors trained on AnomalyAgent's data achieved 57% classification accuracy, a +12.3% jump over non-agentic baselines.
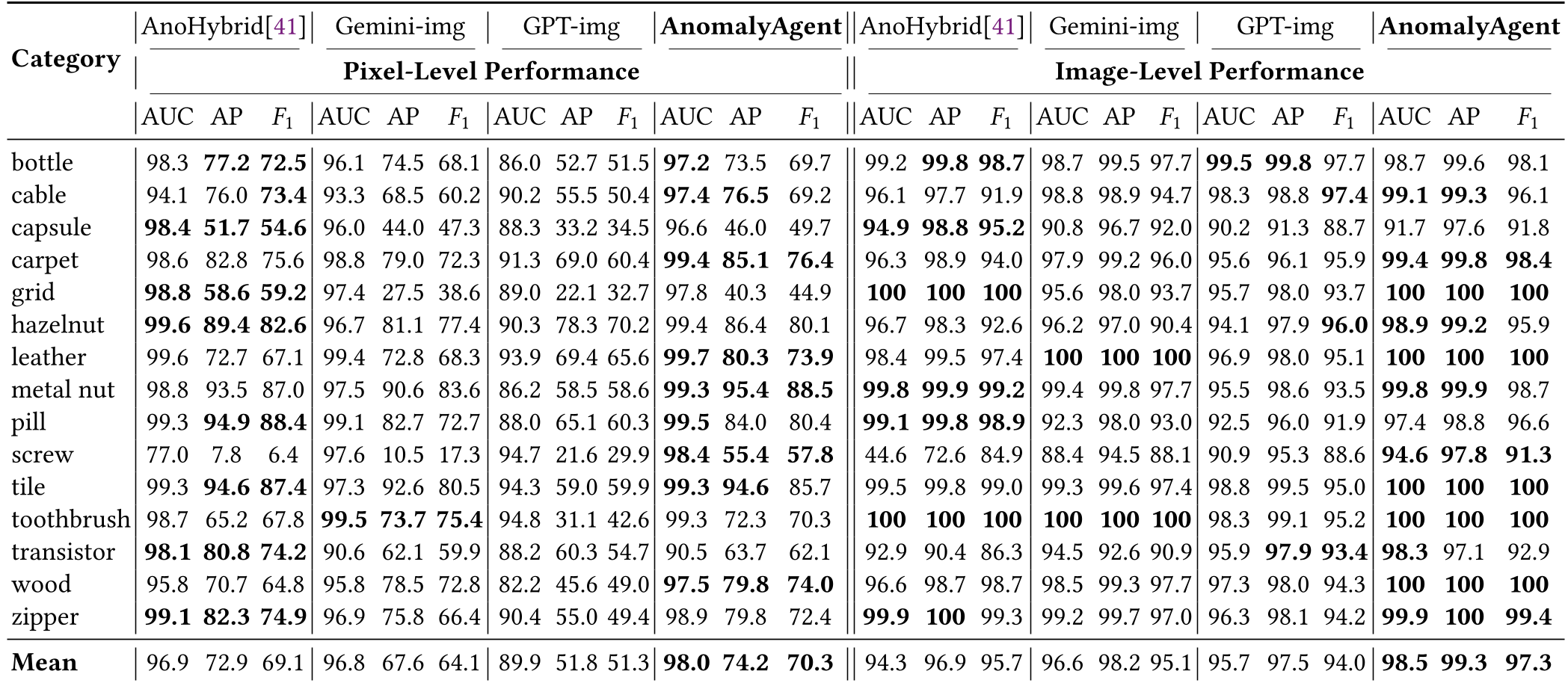
Visualizations show that while previous models create artifacts or "unnatural" shapes, AnomalyAgent accounts for surface textures and material properties (physics-informed synthesis).

Critical Analysis & Conclusion
Takeaway
AnomalyAgent proves that LLM reasoning isn't just for text or code; it can be "grounded" into pixel-space editing through tool-use. The iterative refinement loop acts as an Inductive Bias for realism that single-step models simply cannot match.
Limitations
Despite its success, the framework is computationally heavy. Each "good sample" requires multiple model calls, taking around 100+ seconds. While the cost is lower than human annotation, real-time "on-the-fly" synthesis remains a challenge.
Future Outlook
This "Agentic Synthesis" paradigm could be the "next big thing" for 3D asset generation or medical data simulation, where "correctness" and "feedback" are more important than sheer generation speed.