Anti-I2V is a novel defense framework designed to safeguard personal photos from malicious human image-to-video (I2V) generation. It introduces a Dual-Space Perturbation (DSP) strategy across Lab* and frequency domains, achieving state-of-the-art disruption of identity preservation and temporal coherence across UNet and Diffusion Transformer (DiT) architectures.
TL;DR
As Image-to-Video (I2V) models like CogVideoX and OpenSora become more powerful, the risk of unauthorized "human animation"—creating fake videos from a single photo—skyrockets. Anti-I2V is a new defense mechanism that injects imperceptible adversarial noise into your photos. Unlike previous methods, it doesn't just "mess up the pixels"; it targets the deep semantic layers of Diffusion Transformers (DiTs), causing the video generation process to "collapse" internally, resulting in garbled, unrecognizable videos.
Motivation: Why DiTs are Harder to Guard
Most current adversarial defenses (like AdvDM or MIST) were built for U-Net-based text-to-image models (like Stable Diffusion v1.5). Video Generation Models (VGMs) pose two new challenges:
- Temporal Consistency: These models are designed to be extremely robust; even if one frame is slightly "off," the attention mechanism "corrects" it using information from surrounding frames.
- Architecture Shift: The industry is moving from U-Nets to Diffusion Transformers (DiTs). DiTs have a much larger capacity and use advanced attention mechanisms that tend to ignore traditional pixel-level noise.
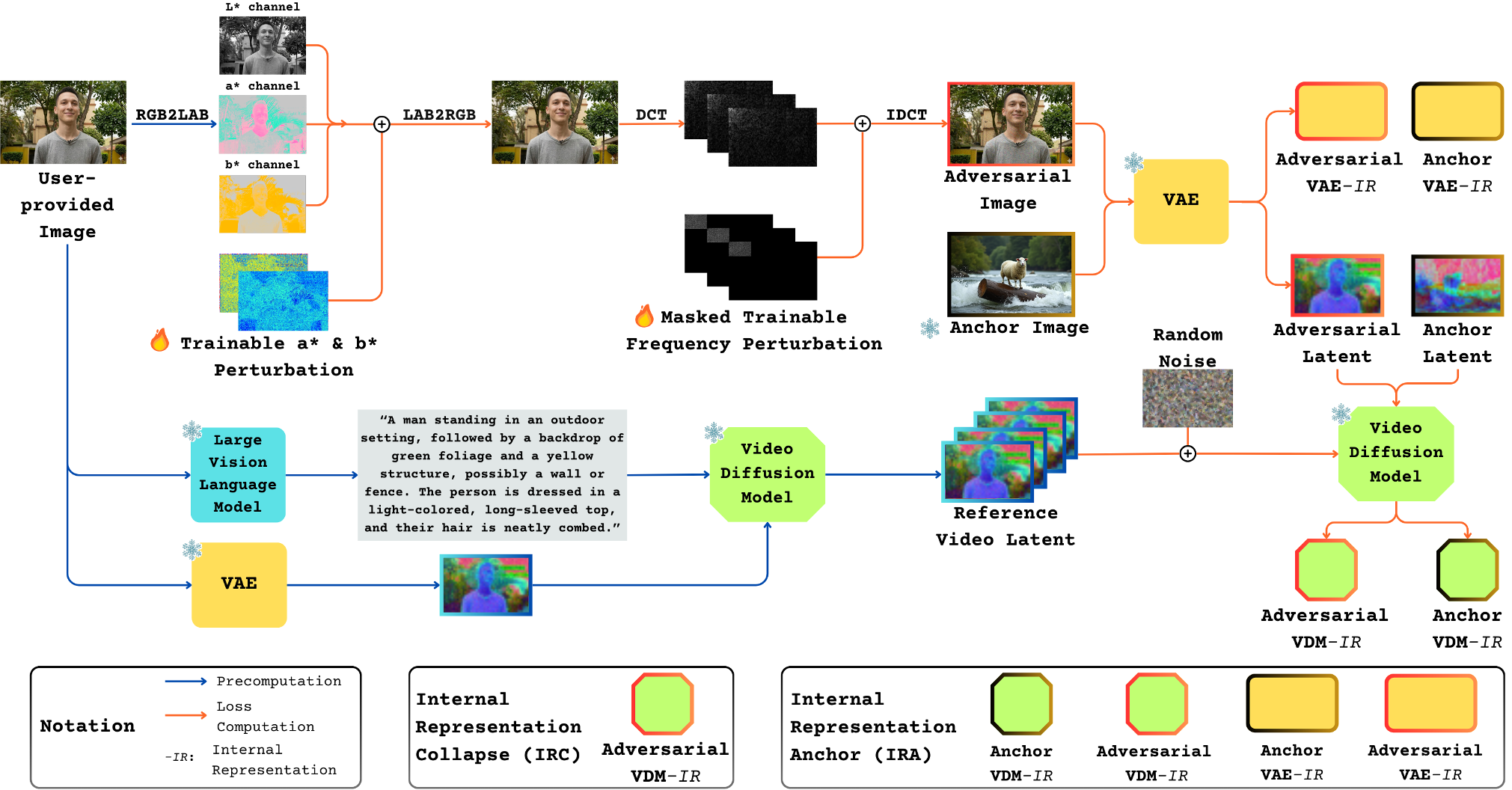
Methodology: Targeting the Heart of the Model
1. Dual-Space Perturbation (DSP)
Instead of optimizing noise in the standard RGB space, Anti-I2V operates in:
- Lab Color Space*: Specifically perturbing the
a*andb*channels to disrupt color perception without affecting brightness, making the noise invisible to humans but confusing to models. - Frequency Domain (DCT): By targeting low-frequency components via Discrete Cosine Transform, the attack hits the "structural" core of the image.
2. Internal Representation Collapse (IRC)
The authors discovered that in models like OpenSora and CogVideoX, meaningful semantic features only start to emerge after specific layers (e.g., the 19th or 27th transformer block).
The IRC Loss forces these "deep semantic layers" to look like "shallow structural layers" during the denoising process. By collapsing these high-level representations, the model loses its ability to reconstruct human identity.

Experiments: Breaking the "Fake" Videos
The team tested Anti-I2V on CelebV-Text (facial focused) and UCF101 (action focused) datasets using three SOTA backbones: CogVideoX, OpenSora, and DynamiCrafter.
Quantitative Edge
Anti-I2V achieved the lowest Identity Score Matching (ISM) and CLIP-FIQA scores across the board. In simple terms, while other generic attacks caused minor blurring, Anti-I2V effectively "deleted" the person's identity from the generated video.
Qualitative Edge
As seen in the visual results, baseline methods like SDS or VGMShield often leave the human face recognizable. Anti-I2V produces pronounced artifacts and total semantic divergence, rendering the "malicious" video useless.

Critical Insight & Conclusion
The true value of this work lies in the layer-wise analysis. By proving that we can degrade generation fidelity by "anchoring" or "collapsing" specific internal representations, the authors have opened a new front in AI safety.
Limitations: There is an inherent trade-off. Extreme protection can sometimes lead to visible noise if the budget ($\Delta$) is too high. However, by using DSP, Anti-I2V keeps the PSNR and SSIM competitive while maintaining an aggressive defense. For individuals concerned about their digital likeness being used to train or generate fake media, Anti-I2V represents a critical step toward "proactive" privacy.