本文提出了 Anti-I2V,一种旨在防止照片被恶意用于图像生成视频(I2V)的防御框架。它通过在 Lab* 空间和频域进行双空间扰动(DSP),并引入层级语义破坏机制,在多种主流生成模型(如 CogVideo-X, OpenSora)上实现了 SOTA 的防御效果。
TL;DR
随着 Sora 等技术的爆发,仅需一张照片就能通过 Image-to-Video (I2V) 模型生成足以乱真的深伪视频。本文介绍的 Anti-I2V 框架通过在 Lab* 空间和频域植入“隐形地雷”,并精准打击模型内部的语义特征传播,让恶意生成的视频彻底崩溃,有效地保护了个人照片不被非法动画化。
1. 背景:为什么传统的保护盾失效了?
目前针对图像生成的保护方法(如对文字生成图像的攻击)主要是通过向 RGB 像素添加扰动。然而,视频扩散模型(VDM)具有极强的“自愈”能力:
- 迭代去噪:多步去噪会像磨皮一样洗掉细微的像素噪声。
- 时空注意力:DiT 或 UNet 架构通过强大的 Attention 机制强制保持帧间一致性,普通噪声很难撼动其语义结构。
- 高容量:大参数量的模型(如 CogVideo-X)对对抗扰动具有天然的鲁棒性。
2. 核心直觉:从“像素”转向“语义层级”
作者发现,视频生成的质量高度依赖于模型中间层提取的语义特征。如果能让这些深层特征在处理受保护图像时产生“崩溃”或“锚定”到错误的方向,生成的视频就会出现严重的虚影、身份错乱和时空跨越。
3. 技术详解:Anti-I2V 的三重打击
A. 双空间扰动 (Dual-Space Perturbation, DSP)
传统的 RGB 攻击易被 JPEG 压缩或高斯模糊破解。Anti-I2V 选择了两个更隐蔽的战场:
- Lab 空间*:在不破坏亮度的前提下,修改 a* 和 b*(色彩分量),这更符合人类视觉系统的特性,隐蔽性更强。
- DCT 频域:直接针对 DCT 变换后的低频系数(代表图像骨架)添加噪声,让模型对图像的基础结构产生误判。
B. 内部表示崩溃 (IRC)
作者通过 PCA 可视化分析发现(见下图),模型的第 3 层基本不含语义信息,而深层(如第 27 层)决定了身份和纹理。IRC Loss 强制让深层的特征图去对齐浅层,本质上是让模型“遗忘”高级语义,导致生成的视频面目全非。
 图中展示了 OpenSora 和 CogVideoX 在不同层级的特征提取情况,越往后层,语义越清晰。
图中展示了 OpenSora 和 CogVideoX 在不同层级的特征提取情况,越往后层,语义越清晰。
C. 内部表示锚点 (IRA)
为了进一步带偏模型,IRA Loss 会强制让受保护图像在进入 VAE 和去噪网络时,其特征表现得像另一张完全无关的图片。这相当于给 AI 戴上了“有色眼镜”,使其生成的视频逻辑完全偏离原图。
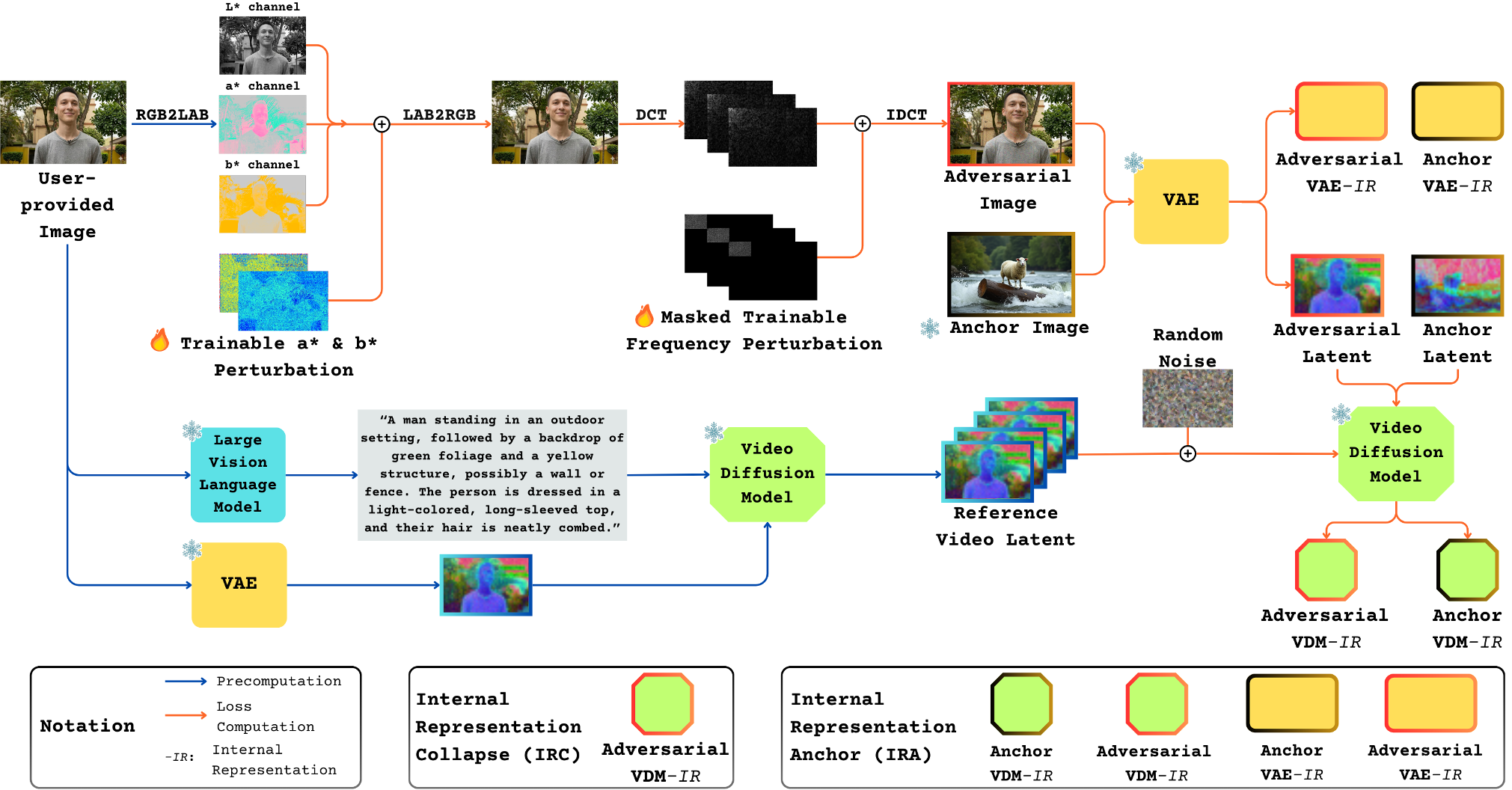 Anti-I2V 总体攻击流程示意图
Anti-I2V 总体攻击流程示意图
4. 实验战绩:全方位压制
在 CelebV-Text(人脸)和 UCF101(人体动作)两个基准上,Anti-I2V 对目前最强的几个开源模型进行了“降维打击”:
- DynamiCrafter:身份匹配度(ISM)从 0.528 降至 0.151(几乎完全丢失身份特征)。
- 跨架构迁移性:即便是在 CogVideo-X 上生成的对抗样本,直接用到 DynamiCrafter 上依旧表现出强劲的防御力。
 定性对比显示,Anti-I2V 生成的防御图像导致视频出现了剧烈的伪影和身份扭曲。
定性对比显示,Anti-I2V 生成的防御图像导致视频出现了剧烈的伪影和身份扭曲。
5. 总结与反思
Anti-I2V 的成功在于它找到了视频扩散模型的“阿喀琉斯之踵”——依靠跨帧一致性的语义传播。
- 优势:防御效果极强,且对常见的图像净化手段(如 DiffPure)具有很好的抗性。
- 局限性:虽然在 Lab* 空间做了优化,但在强力攻击下,SSIM 和 PSNR 仍有小幅下降,说明在极端防御与绝对视觉完美之间仍需平衡。
这项工作为我们在 AIGC 时代保护个人生物特征和版权提供了一条极具前景的技术路径:用 AI 的语义直觉去对抗 AI 的生成逻辑。