本文推出了 AnyHand,一个包含 6.6M 图像的大规模合成 RGB-D 手部姿态数据集,涵盖单手与手物交互场景。通过在现有顶尖模型(如 HaMeR, WiLoR)中加入 AnyHand 进行联合训练,显著提升了 3D 手部姿态估计的精度与泛化能力。
TL;DR
在计算机视觉的 3D 手部姿态估计(3D HPE)领域,数据短缺一直是制约模型泛化的核心瓶颈。本文提出的 AnyHand 数据集通过 660 万张高保真合成图像(包含 RGB-D),不仅打破了真实数据标注难的僵局,还通过联合训练让现有模型(如 HaMeR, WiLoR)刷新了 SOTA 记录。研究核心结论:数据的“质”与“量”,比模型架构复杂性更重要。
1. 痛点:为什么真实数据不再够用?
在 3D 手部建模中,传统的真实采集数据集面临三个“致命伤”:
- 标注噪声:在手物交互(Hand-Object Interaction)中,由于物体遮挡,即便是昂贵的动捕系统捕捉到的 3D 标注也存在大量噪声。
- 多样性缺失:现有数据集的背景、肤色、照明条件高度单一,导致模型极易在干净的实验室环境下 Overfitting。
- 模态缺失:大部分大规模数据集仅提供 RGB 图像,缺乏精确对齐的 Depth(深度)信息,导致模型在处理 3D 绝对尺度和空间平移时存在固有歧义性。
2. AnyHand:全方位的合成“魔法”
为了解决上述问题,AnyHand 管线引入了几个极其关键的物理直觉:
- 姿态的自然性:不再使用随机采样,而是利用 DPoser-Hand(基于扩散模型的先验)来生成符合人体生理学的手部动作。
- 连贯的前臂上下文:作者发现,单纯渲染手部会遗漏手腕定位的关键线索。AnyHand 使用 SMPLitex 为前臂增加了真实的服装(长/短袖)和皮肤纹理,消除了 2D 贴图常见的边界人工痕迹。
- 物理一致的交互:结合 GraspXL 物理引擎,从 Objaverse 中调用 50 万种物体进行抓取模拟,生成了海量带有真实遮挡(Occlusion)的样本。
 图 1: AnyHand 的多样性展示,包含单手、交互场景及精准的深度图
图 1: AnyHand 的多样性展示,包含单手、交互场景及精准的深度图
3. 架构创新:轻量级深度融合模块
虽然 AnyHand 侧重于数据,但作者也提供了一个优雅的架构方案 —— AnyHandNet-D。 以往的 RGB-D 融合往往需要笨重的双塔结构。本文设计了一种**双分支 Embedding + 跨注意力(Cross-Attention)**的模块。该模块可以像插件一样集成到现有的 ViT 后干网络中,通过交换 RGB 和 Depth 的特征 Token,让模型在看到图像纹理的同时,利用几何线索(如手指间的深度差)来修正位姿估计。
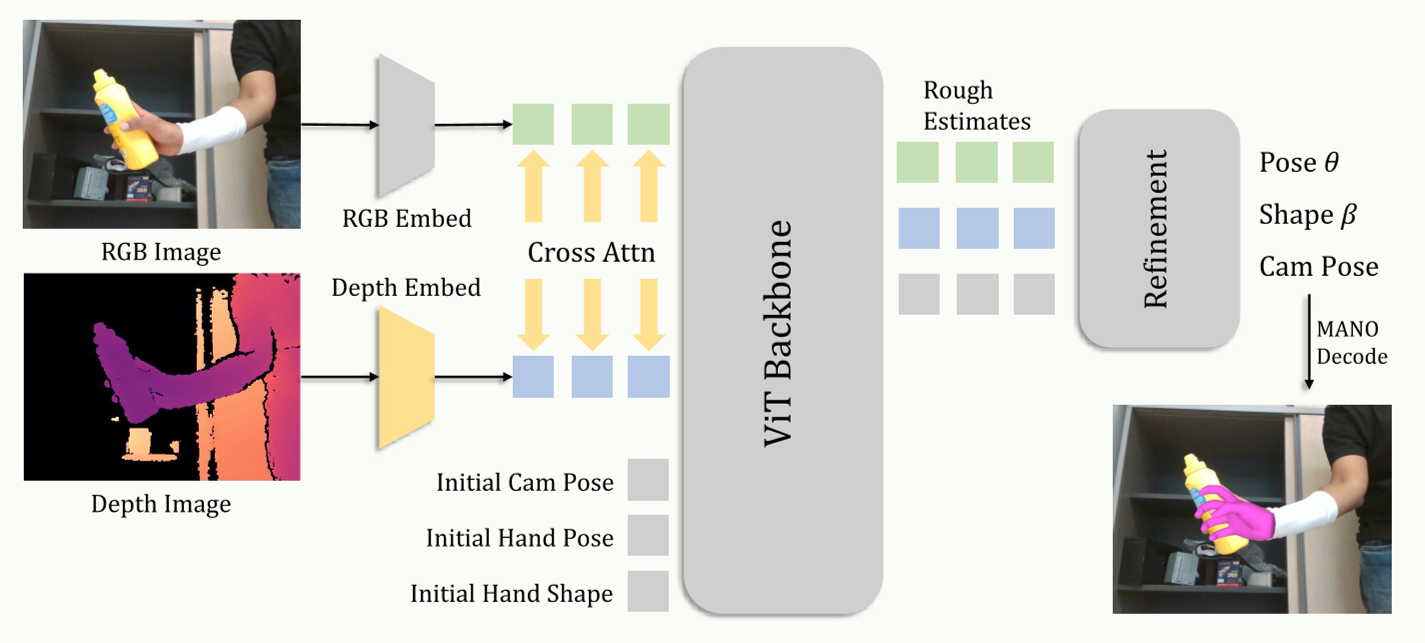 图 2: AnyHandNet-D 架构,重点在于轻量级的跨模态信息交换
图 2: AnyHandNet-D 架构,重点在于轻量级的跨模态信息交换
4. 实验战绩:合成数据能打赢真实数据吗?
在 RGB 设置下,加入 AnyHand 后的提升是普适性的。无论是基础模型 HaMeR 还是更强劲的 WiLoR,在 FreiHAND 榜单上均有明显进步。更令人惊讶的是 域外泛化(Out-of-domain) 测试:在完全未见的 HO-Cap 数据集上,即便不进行任何 Fine-tuning,错误率也大幅下降。
在 RGB-D 设置下,AnyHandNet-D 的 STA-MPJPE 达到了 1.09cm,相比之前的 SOTA 方法 Keypoint-Fusion 降低了 41.7%。
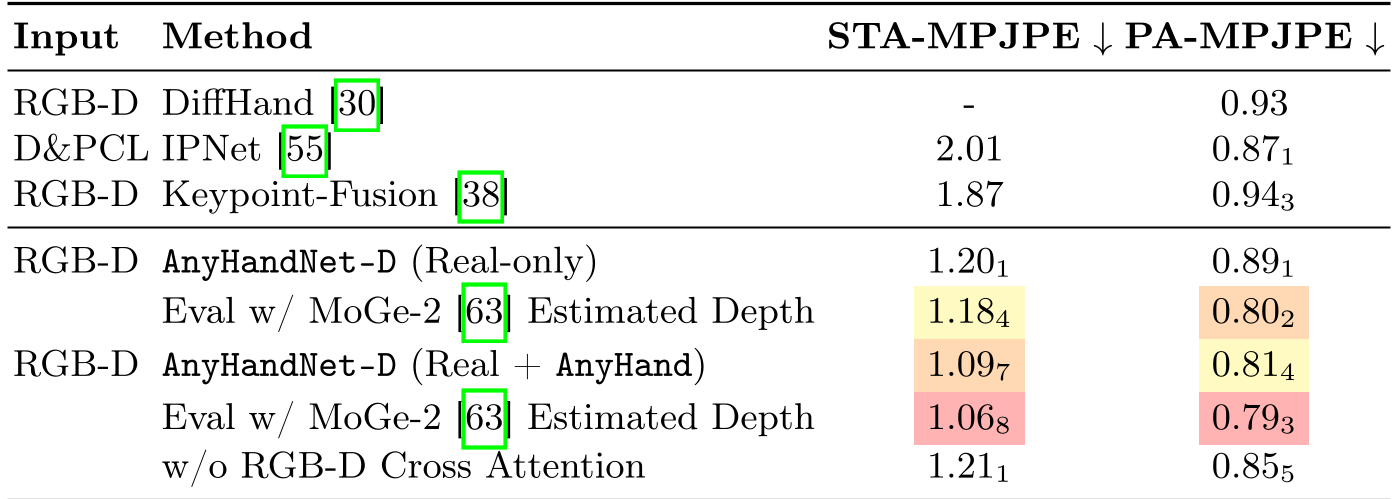 图 3: 各类 SOTA 模型在 RGB-D 模式下的对比,AnyHand 方案优势巨大
图 3: 各类 SOTA 模型在 RGB-D 模式下的对比,AnyHand 方案优势巨大
5. 深度洞察与总结
- 关于 Sim-to-Real 的认知:消融实验显示,单一使用合成数据是不够的(训练效果会崩塌),但通过 联合训练(Co-training),合成数据能提供真实数据无法提供的细粒度几何约束和极端姿态覆盖。
- 模型与数据的博弈:论文通过实验证明,在一个已经极其强大的 Transformer 骨干(如 ViT-L)上继续改进架构,收益远不如喂给它 600 万张高质量合成图像来得直接。
- 局限性:尽管 AnyHand 非常强大,但在极度复杂的手-物-环境三方遮挡下,合成与真实之间仍存在微小的纹理缝隙。
结论:AnyHand 不仅仅是一个数据集,它展示了 3D 视觉任务步入“基础模型”时代的正确姿势 —— 以海量、高质量的物理合成内容,填补真实世界长尾场景的鸿沟。