ArtHOI is an optimization-based framework for 4D reconstruction of hand-articulated-object interactions (HOI) from a single monocular RGB video. It integrates multiple foundation models to recover 3D geometry and motion of unknown articulated objects (like scissors or laptops) and interacting hands without requiring pre-scanned templates, achieving superior performance over existing methods like RSRD.
Executive Summary
TL;DR: ArtHOI is a breakthrough framework that reconstructs the 4D motion of hands and unknown articulated objects (like scissors, laptops, or staplers) from a simple smartphone video. By intelligently "stitching" together outputs from specialized foundation models (for depth, tracking, segmentation, and 3D generation) and refining them through MLLM-guided physical constraints, it eliminates the need for expensive 3D scanners or multi-camera setups.
Background Positioning: This work moves beyond the "rigid-object" assumption prevalent in Hand-Object Interaction (HOI) research. It sits at the intersection of Foundation Model Distillation and Non-rigid 3D Vision, effectively setting a new SOTA for in-the-wild 4D reconstruction.
Problem & Motivation: The "Template" Trap
Until now, reconstructing how a hand moves an articulated object was a "closed-world" problem. You either needed:
- Pre-scanned Templates: You had to 3D scan the specific scissors or laptop first.
- Multi-view Constraints: You needed a lab with 10+ cameras to resolve depth.
Existing Foundation Models (like Depth-Anything or SAM) provide "hints" of the geometry, but they fail when used naively. An image-to-3D model might give you a beautiful mesh of a stapler, but it has no idea how big it is in the real world (Metric Scale) or how the parts rotate relative to one another. Furthermore, simply placing a hand mesh next to an object mesh usually results in "ghosting" (floating hands) or "interpenetration" (fingers inside the plastic).
Methodology: The Core Optimization
ArtHOI solves this through a four-stage pipeline: Preprocessing, Metric Scale Refinement, Motion Tracking, and MLLM Alignment.
1. Adaptive Sampling Refinement (ASR)
To fix the scale problem, the authors developed ASR. It takes a normalized mesh (from HunYuan3D) and "hunts" for the correct metric scale by iteratively sampling scale candidates and checking how well the rendered silhouette matches the actual video mask.
2. MLLM-Guided Interaction Alignment
This is the "human-like" intuition part of the system. The authors used Qwen-VL-Max (an MLLM) to act as a "physical supervisor."
- The Insight: Humans can see "contact" even when depth sensors are noisy.
- The Solution: The MLLM analyzes the video and dictates: "The thumb and index finger are touching the top handle of the scissors in frames 10-50."
- The Constraint: This text-based reasoning is converted into a mathematical Contact Loss, pulling the hand and object together until they physically touch at the correct vertices.
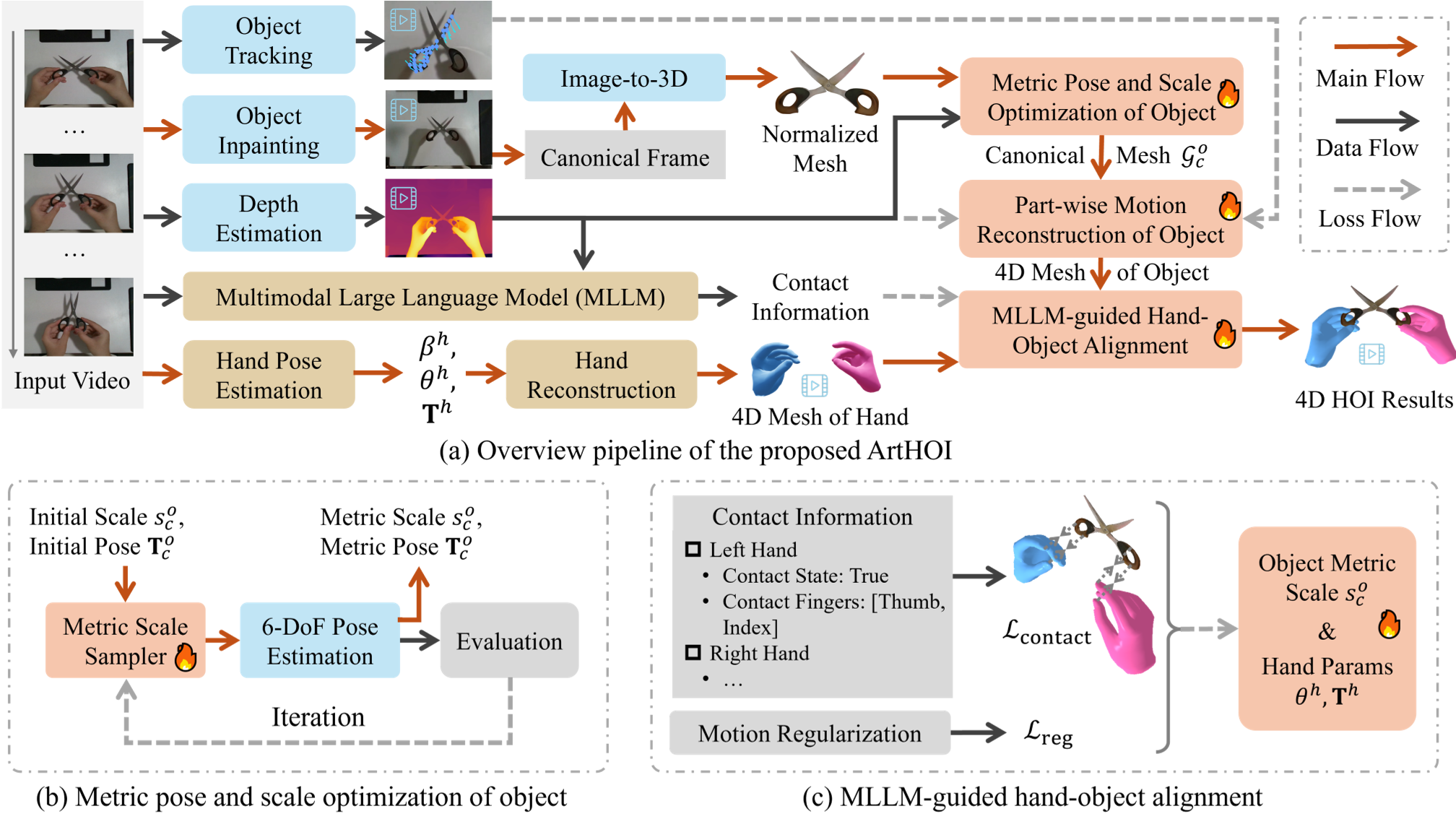 Figure 1: The ArtHOI Pipeline. Note the integration of ASR (b) and MLLM-guided alignment (c).
Figure 1: The ArtHOI Pipeline. Note the integration of ASR (b) and MLLM-guided alignment (c).
Experiments & Results: Surpassing the "Scanners"
The most striking result is that ArtHOI often beats RSRD—a baseline that has the advantage of using ground-truth object scans.
- Quantitative Leap: On complex articulated objects like a CD Drive, ArtHOI reduced the Chamfer Distance (error) from 282.3mm to 3.3mm.
- Robustness: In "In-the-Wild" scenarios (YouTube clips), where baselines like RSRD fail completely due to the lack of pre-scans, ArtHOI successfully recovers 4D meshes with 86%+ contact accuracy.
 Figure 2: Qualitative results showing physically plausible contacts across diverse objects like headphones and sunglasses.
Figure 2: Qualitative results showing physically plausible contacts across diverse objects like headphones and sunglasses.
Critical Analysis & Conclusion
Takeaway
ArtHOI proves that we don't need a single "Omnipotent Model" to solve 4D HOI. Instead, an optimization framework that understands the reliability of its sub-components (trusting MLLMs for semantics and ASR for scale) can synthesize a result greater than the sum of its parts.
Limitations
- Speed: The pipeline takes ~1 hour for a 100-frame video, mainly due to the intensive part-wise motion optimization. It is not yet real-time.
- Heuristic Dependency: It still relies on 2D tracking (CoTracker) to initialize motions; if the object is severely occluded for too long, the tracking can drift.
Future Outlook
This work paves the way for robots to learn manipulation skills by simply "watching" YouTube. By digitizing interactions into 4D meshes, we can generate massive datasets for Reinforcement Learning without ever entering a physical lab.