本文提出了 ArtHOI,一个通过单目 RGB 视频实现手部与关节物体(如剪刀、笔记本电脑)交互的 4D 重构框架。该方法通过整合多模态基础模型(Foundation Models)的先验,并引入自适应采样细化(ASR)与 MLLM 引导的对齐策略,打破了以往研究对物体预扫描模板或多视角输入的依赖。
TL;DR
在 3D 视觉领域,重构“人手操作物体”的动态过程一直是个硬骨头,尤其是当面对像剪刀、订书机这类具有**关节旋转(Articulated)**的物体时,难度指数级上升。传统的做法往往需要给物体提前拍个“全身 CT”(预扫描模板),但这在实际应用中几乎不可能实现。
ArtHOI 给出了一套优雅的解法:它不再依赖模板,而是通过一套复杂的优化管线,将现有的 AI 基础模型(如深度估计、图像转 3D、点追踪、大语言模型)有机地“缝合”在一起,仅凭一段普通手机拍摄的视频,就能还原出精准的 4D(3D+时间)交互场景。
痛点深挖:为什么“缝合”基础模型这么难?
虽然现在我们有很多强大的基础模型:
- Image-to-3D(如 HunYuan3D)可以生成精美的网格,但它是“无量纲”的,不知道物体在现实中到底是 5 厘米还是 50 厘米。
- Depth Estimation 虽能提供深度,但往往带有噪声,与 3D 网格对不上。
- Hand Pose Estimator 算出的手部动作,直接叠加上去经常会发现手指“插进”了物体内部,或者根本没碰着。
这种多模态先验之间的物理不一致性,是实现自动化、无模板重构的最大障碍。
核心机制:ArtHOI 的三大杀手锏
1. 自适应采样细化 (ASR):寻找丢失的尺度
为了解决 Image-to-3D 生成的网格没有真实物理尺度的问题,作者提出了 ASR。它不是简单地缩放,而是在一个自适应的范围内迭代采样,寻找能让渲染出的物体轮廓(Silhouette)与视频掩码最契合的那个“完美比例”和“6-DoF 姿态”。
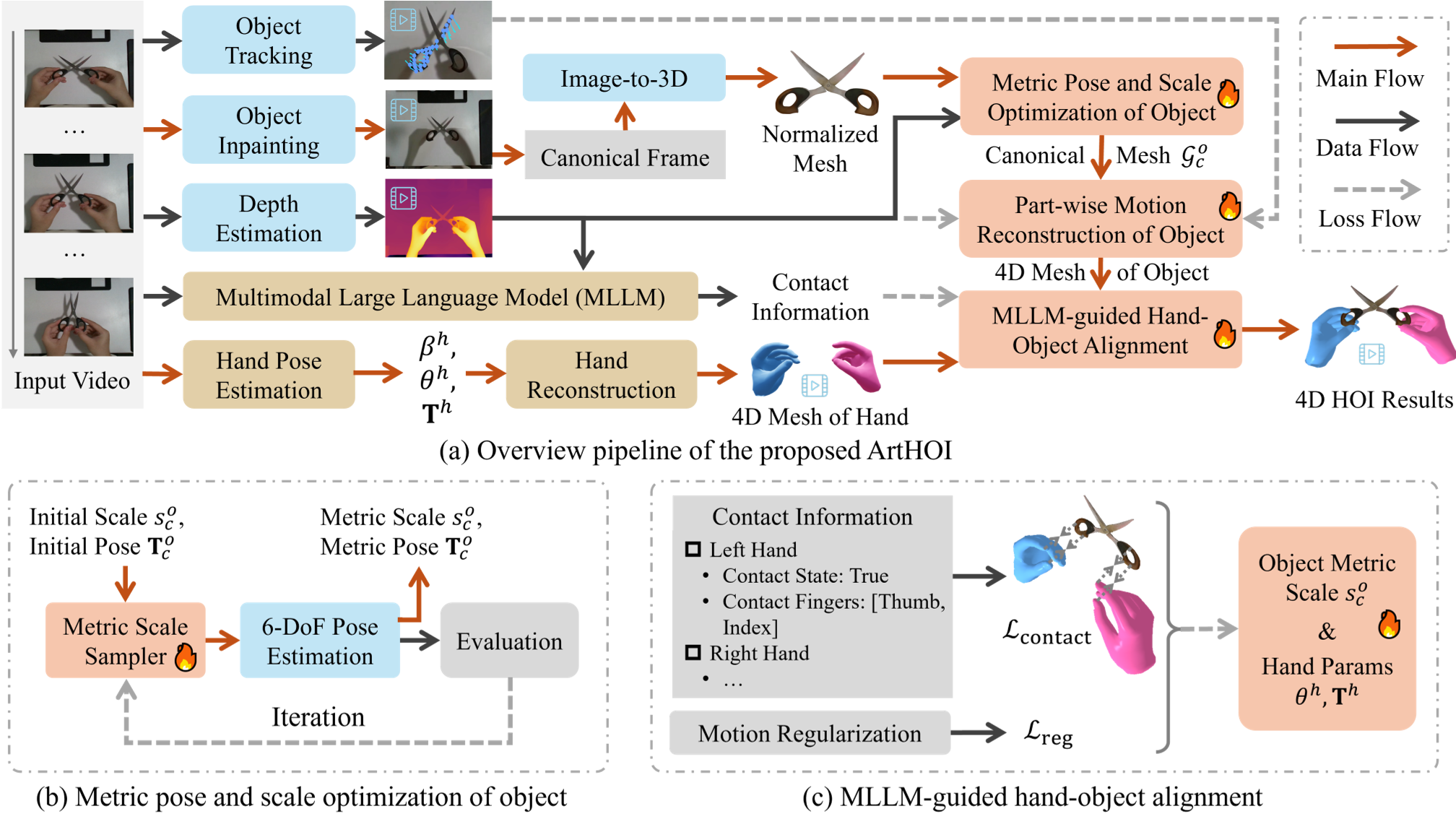 图 2:ArtHOI 管线概览。从数据预处理到部件运动恢复,再到最终的 MLLM 引导对齐。
图 2:ArtHOI 管线概览。从数据预处理到部件运动恢复,再到最终的 MLLM 引导对齐。
2. 部件级运动重建 (Part-wise Motion)
物体动起来时,每个零件的运动轨迹都不一样。ArtHOI 利用 CoTracker 进行密集点追踪,并结合 PartField 将物体网格分割成不同部件。通过最小化追踪损失和运动平滑约束,它能精确捕捉到剪刀开合或笔记本合盖的复杂动态。
3. MLLM 引导的手物对齐:让 AI 拥有“常识”
这是本文最具启发性的创新。作者利用 Qwen-VL 等多模态大模型来充当“裁判”。既然物理模型算不准手到底碰到了哪里,那就问问大模型:
- “它是第一视角还是第三视角?”(解决左右手混淆)
- “现在哪根手指碰到了物体的哪个部位?”
MLLM 提供的“接触先验”被转化为优化公式中的硬约束,强制要求手指尖必须贴合在物体表面,从而消除了物理上不可能的悬空或穿透现象。
实验战绩:超越“开挂”的前人
最令人惊讶的结果出现在表 1 和表 2 中。作者对比了 RSRD —— 这是一个需要预扫描物体背景的手物交互框架。
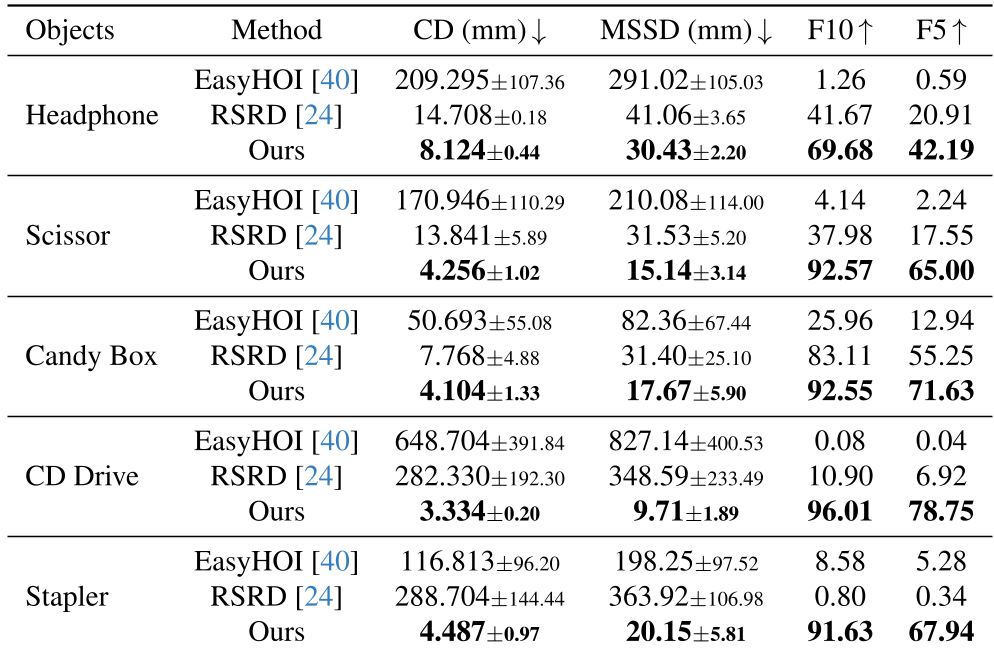 表 1:在 ArtHOI-RGBD 数据集上的定量对比,ArtHOI 在各项指标(CD, MSSD, F10)上均显著优于需要预扫描的 RSRD。
表 1:在 ArtHOI-RGBD 数据集上的定量对比,ArtHOI 在各项指标(CD, MSSD, F10)上均显著优于需要预扫描的 RSRD。
在 CD Drive(光驱)等极其复杂的关节交互中,ArtHOI 显示出了极强的鲁棒性。即便在没有任何物体先验的情况下,其重构误差也比那些“见过”物体模型的旧方法还要小。
 图 3:在野外视频(ArtHOI-Wild)上的表现,无论视角如何切换,手物交互都能保持极高的视觉一致性。
图 3:在野外视频(ArtHOI-Wild)上的表现,无论视角如何切换,手物交互都能保持极高的视觉一致性。
深度洞察与总结
ArtHOI 的成功揭示了一个趋势:下一代 3D 重构不再是单一算法的孤岛,而是多种视觉先验的“协同博弈”。
- 优势:它极大地降低了数据采集的门槛。不再需要昂贵的扫描设备,只需一段互联网视频,我们就能获取高质量的交互数据。这对于机器人模仿学习(Robot Imitation Learning)具有巨大的价值。
- 局限性:由于依赖复杂的优化流程,目前的处理速度仍然偏慢(100 帧视频约需 1 小时),离实时的增强现实(AR)应用还有距离。此外,对于高度遮挡或极其复杂的关节连接(如多层嵌套关节),模型的可靠性仍有提升空间。
总之,ArtHOI 为我们展示了当“视觉直觉”(基础模型)与“逻辑约束”(优化算法)相结合时,能迸发出何等强大的生产力。