本文提出了 Astrolabe,一个专为蒸馏自回归(AR)视频模型设计的显式在线强化学习(RL)框架。通过引入前向过程 RL(Forward-Process RL)和流式训练机制,在无需重新蒸馏的情况下,显著提升了流式生成视频的视觉质量与时序一致性,在 30 秒长视频生成任务中达到 SOTA 表现。
TL;DR
针对实时视频生成模型“快而不美”的痛点,港科大与京东探索研究院等机构提出了 Astrolabe。这是一款高效的在线强化学习框架,专门用于优化蒸馏后的自回归(AR)视频模型。它无需重新蒸馏,通过前向过程 RL 和 流式训练方案,在极低显存占用下完成了长视频的偏好对齐,显著改善了运动一致性和画面细节。
背景:为什么视频模型对齐这么难?
当前的视频生成领域正经历从“离线全量生成”到“在线流式生成”的范式转移。虽然基于分布匹配蒸馏(DMD)的 AR 模型实现了极速推理,但它们往往存在两个顽疾:
- 偏好失调:由于学习目标是模仿教师分布而非人类审美,生成结果常伴随伪影。
- 训练瓶颈:现有的强化学习(如 RLHF 常用手段)需要反向遍历整个采样轨迹(Reverse-process),这对于显存本就紧张的视频模型来说无异于雪上加霜。
核心机制:Astrolabe 的创新艺术
1. 前向过程 RL:跳过轨迹的魔术
不同于传统的逆向轨迹优化,Astrolabe 采用了**前向过程(Forward-Process)**表述。
- 直觉:它不需要存储完整的采样链条,而是通过在生成的清晰样本上添加噪声,并利用当前策略与旧策略的插值构建“隐式正负样本对”。
- 效果:实现了 Trajectory-free 优化,训练开销与普通微调相当,且与特定的 ODE 求解器解耦。
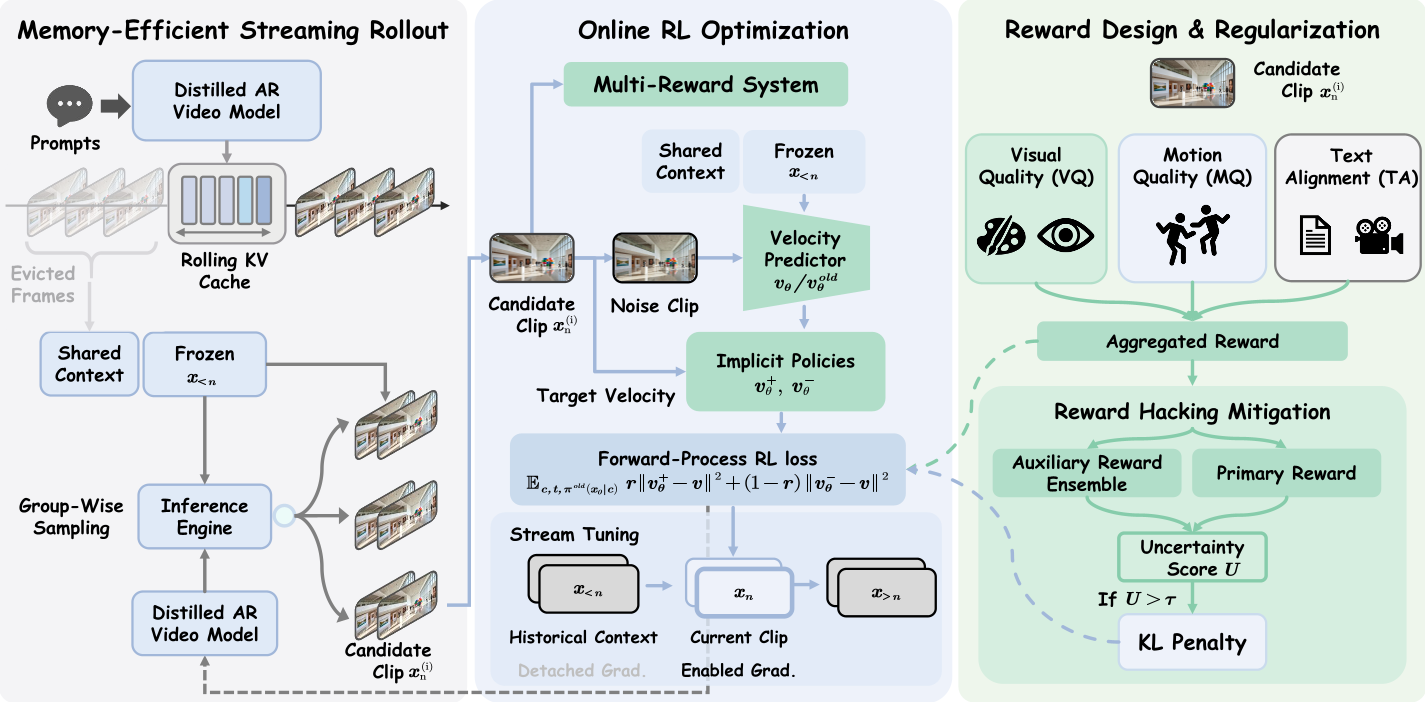
2. 流式训练:有限显存下的无限可能
为了处理长视频对齐,作者提出了滚动 KV-Cache 机制。
- Frame Sinks(框架锚点):永久保留初始几帧以锚定全局语义。
- 局部窗口优化:训练时只对当前计算窗口进行梯度回传,历史背景作为冷冻 context 存在。这确保了无论视频生成多长,梯度计算的内存峰值始终保持恒定。
3. 三剑客奖励与选择性 KL
为了防止模型为了刷高分而生成“高质量但静止”的崩坏画面,Astrolabe 使用了组合拳:
- 多维奖励:融合视觉质量(VQ)、运动质量(MQ)和文本匹配(TA)。
- 选择性 KL 惩罚:仅在多个奖励模型出现严重分歧(暗示可能在进行 Reward Hacking)时才增加 KL 约束,释放了模型在正常样本上的探索自由度。
实验战绩:全方位的画质飞跃
在针对 5 秒短视频和 30 秒长视频的测试中,Astrolabe 展现了恐怖的普适性。无论是 Self-Forcing 还是 Causal Forcing 架构,经过 Astrolabe 对齐后,HPSv3(人类审美得分)普遍提升了 15% 以上。

从定性对比图(图 6)可以看到,在复杂的多提示词转场中,Astrolabe 显著减少了人物形态的扭曲,并增强了纹理的细腻程度。

深度洞察
Astrolabe 的成功在于它深刻理解了自回归特性的本质。它没有强行将大语言模型的 RL 套路移植过来,而是针对自回归预测中的“曝光偏差”和“计算冗余”,利用 KV-Cache 分离了“感知(Rollout)”与“学习(Optimization)”。
局限性:尽管对齐效果显著,但它依然受限于基座能力。如果原始蒸馏模型已经丢失了某些空间几何构图能力,仅靠 RL 很难“凭空创造”出这些知识。
总结
Astrolabe 为高效视频模型的后处理对齐建立了一个标杆。它告诉我们,通过巧妙的设计,即便是在计算资源受限的情况下,我们也能够让实时视频模型拥有媲美顶尖非实时模型的审美水平。