The paper introduces an Attribution-Guided Continual Fine-tuning framework for Large Language Models (LLMs) to combat catastrophic forgetting. It leverages a customized Layer-wise Relevance Propagation (LRP) method to quantify element-wise parameter importance, outperforming standard regularization and replay baselines in sequential task adaptation.
TL;DR
Large Language Models (LLMs) often "forget" old tricks when learning new ones. This paper introduces a surgical approach to continual learning: instead of freezing random layers or replaying old data, it uses Layer-wise Relevance Propagation (LRP) to identify exactly which weights are "load-bearing" for specific knowledge. By shielding these weights from future gradients, the model learns new tasks without destroying its past expertise.
The "Mechanistic" Gap in Continual Learning
Current strategies for keeping LLMs updated—such as LoRA-based regularization or experience replay—treat the model as a "black box" of weights. They assume that either all parameters are equally likely to cause forgetting, or that replaying a few old samples will naturally keep the weights in check.
The authors of this paper discovered a startling trend: in standard sequential fine-tuning, the parameters identified as "important" for two different tasks eventually overlap significantly in the final model (as seen in Figure 1). This is the smoking gun of interference: learning Task 2 literally overwrites the specific neurons required for Task 1.
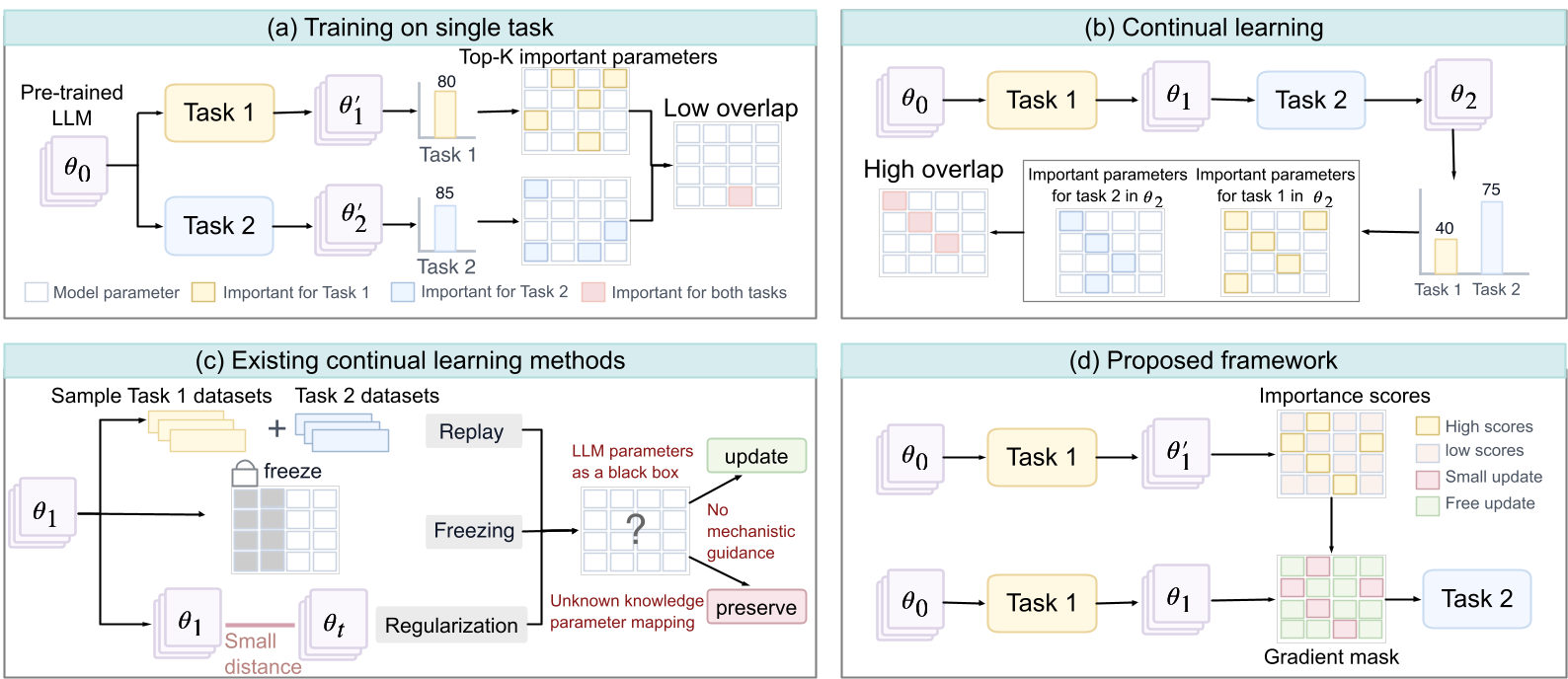
Methodology: From "Why" to "How"
The core innovation is the transition from Input Attribution (explaining why a model chose a word based on the prompt) to Parameter Attribution (explaining which weight in which layer caused that choice).
1. The Physics of Importance: LRP
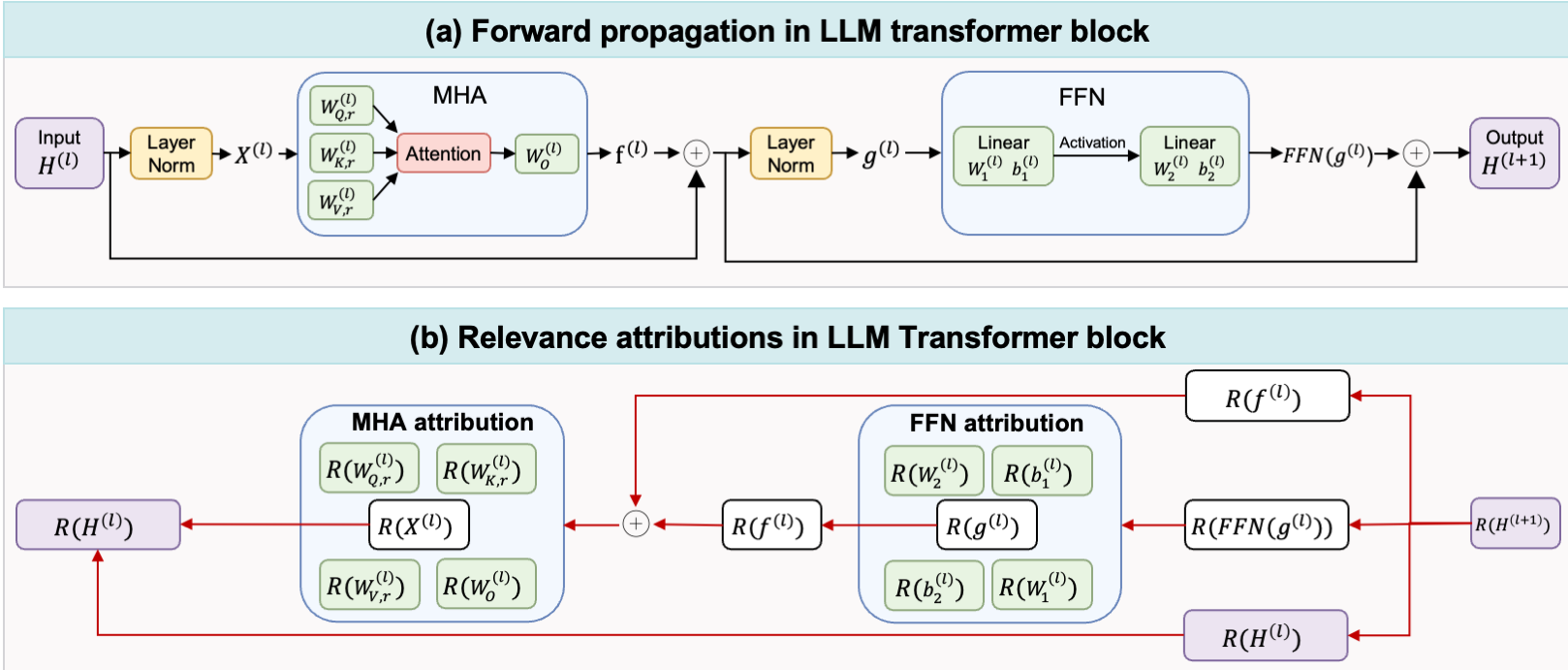
The authors utilize Layer-wise Relevance Propagation (LRP). Unlike gradients, which indicate the sensitivity of the loss, LRP tracks the flow of information from the output logit back to the inputs and parameters. Through a bilinear decomposition (Lemma 4.1), they successfully attribute the logit score to:
- FFN Weights: Determining which neurons in the feed-forward layers store task-specific facts.
- Attention Heads: Identifying which heads are critical for specific structural tasks (like coding vs. summarization).
2. The Gradient Gate
Once the importance scores are calculated for Task , the framework creates an element-wise "gradient gate" . During Task :
- High Importance (): The gate is closed; the gradient is multiplied by . The weight is preserved.
- Low Importance (): The gate is open; the gradient is untouched. The weight is free to adapt.
Experiments: Precision Matters
The framework was tested on Llama-3.2-Instruct-3B across tasks like summarization and coding. Use of the attribution-guided gate allowed the model to maintain high performance on Task 1 even after extensive training on Task 2, whereas baseline models saw their Task 1 scores drop significantly.
Notably, this method works even with LoRA (Low-Rank Adaptation). By attributing relevance to the and low-rank matrices, the authors prove that even parameter-efficient tuning benefits from mechanistic constraints.
Critical Insight: Why This Works
Standard regularization (like EWC) often uses the Fisher Information Matrix, which is a global approximation. Attribution methods like LRP provide a per-sample, per-token view of importance. This "surgical" granularity ensures that the model isn't just restricted in general, but is restricted specifically where it counts for a given task's semantic footprint.
Conclusion & Future Outlook
This paper bridges the gap between Interpretability and Optimization. By showing that we can translate "relevance maps" into "gradient masks," the authors pave the way for LLMs that can grow indefinitely without losing their foundation.
Limitations: The current method requires a brief "single-task fine-tuning" phase to estimate the importance prior for each new task, which adds computational overhead. Future work might focus on calculating these importance maps on-the-fly during the first few steps of continual learning.
Takeaway: In the future of LLMs, we won't just train models; we will "curate" their weight distributions based on the knowledge they represent.