The paper investigates how the "auditory knowledge" implicitly learned by Large Language Models (LLMs) during text-only pre-training influences their performance as backbones for Audio Language Models. By introducing the AKB-2000 benchmark and evaluating 12 open-weight models across text-only and audio-grounded settings, it identifies the Qwen family as a superior backbone and establishes a strong correlation between text-based auditory reasoning and multimodal success.
TL;DR
Does a Large Language Model (LLM) need to "hear" to understand sound? This paper proves that LLMs acquire significant auditory knowledge through text pre-training alone. By benchmarking 12 popular LLMs, the researchers found that a model's performance on text-based audio questions (like AKB-2000) is a powerful predictor of its success as a multimodal Audio Language Model. Key takeaway: Qwen currently beats Llama as a hearing backbone, and most models are "deaf" to phonology (rhyme and stress).
The "Deaf" Reasoning Problem
In the race to build the ultimate "Siri-like" AI, researchers have been bolting audio encoders onto LLM backbones like Llama-3 or Qwen-2.5. However, the choice of the backbone is usually treated as a secondary thought. We assume that because an LLM is a "reasoning engine," it can handle any modality once a connector is attached.
But there is a hidden variable: Auditory Knowledge. If an LLM doesn't know that a "violin sounds warm" or that "flour and flower sound identical," can it truly reason about the audio it "hears"?
Methodology: Can You Hear the Text?
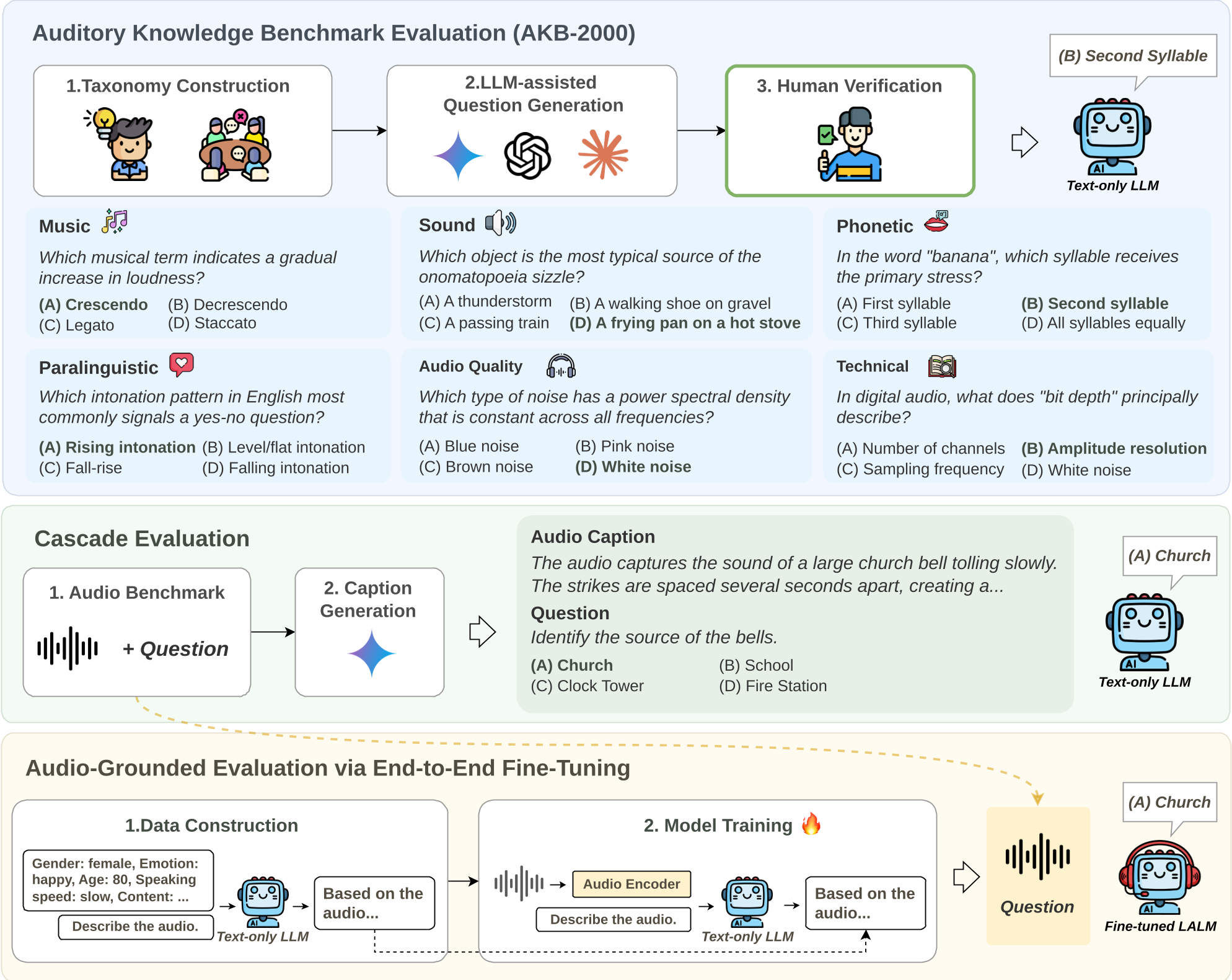
The authors designed a three-step pipeline to isolate the impact of the LLM backbone:
- AKB-2000 (The Knowledge Test): A massive bank of 2,000 questions across 48 subcategories (Sound, Music, Phonetics, etc.) to see what the models know purely from reading books and the web.
- Cascade Evaluation (The Proxy Test): Feeding the LLM a text description of an audio clip (e.g., "A dog barks twice rapidly") and asking it to answer complex questions.
- Audio-Grounded Evaluation (The Real Test): Fine-tuning the LLMs with a frozen Whisper-v3 encoder and a Q-Former to see how well the knowledge transfers to actual raw audio.
Key Insights & Results
1. The "Qwen" Advantage
The study reveals a clear hierarchy. The Qwen family (especially Qwen-3 and Qwen-2.5) consistently outperformed the Llama family. In fact, a 7B Qwen model often outperformed an 8B Llama model by over 12% in auditory knowledge. This suggests that the training data for Qwen might be richer in descriptive auditory concepts.
2. The Phonological Blind Spot
The models were surprisingly good at technical music theory or general sound identification, but they failed miserably at Phonetics. Specifically:
- Rhymes: LLMs struggle to know if "cat" and "hat" rhyme.
- Homophones: They can't easily tell that "blue" and "blew" sound the same.
- Why? Because LLMs see tokens, not waves. Without phonetic supervision, the "sound" of language is invisible to them.
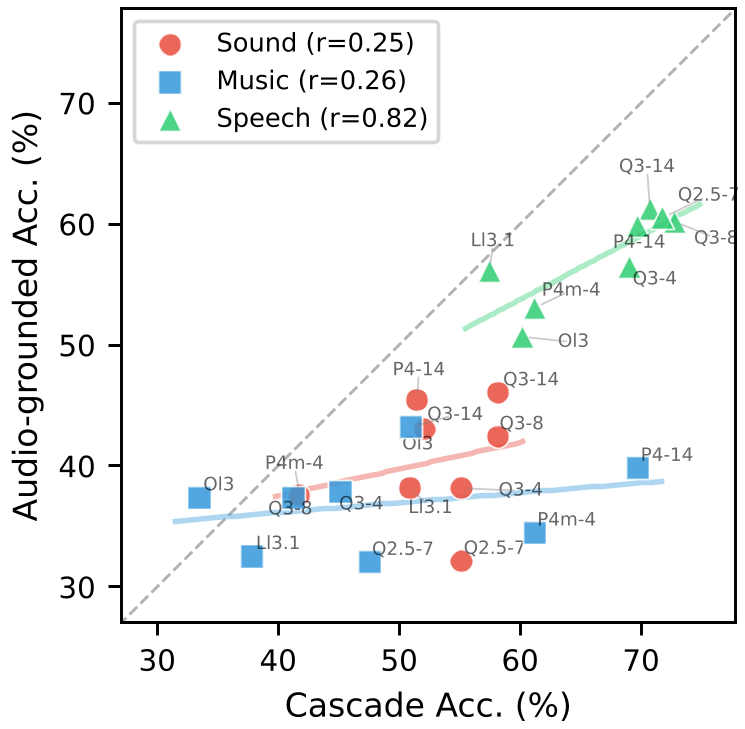
3. Text Prediction Power
One of the most valuable findings is the strong Pearson correlation (r=0.82) between text-only benchmarks and audio-grounded performance. This means developers can use the lightweight AKB-2000 test to pick their backbone model before spending thousands of dollars on expensive multimodal GPU training.

Experimental Results: Fine-Tuning LALMs
When the researchers actually built the LALMs (Audio Grounded), the results were striking. The best fine-tuned model (Qwen3-14B) significantly beat Llama-based models even when using identical training recipes. Interestingly, a cascade pipeline (Captioner + LLM) still rivals many end-to-end models, suggesting that our current "audio-to-LLM" connectors are a major bottleneck—they lose information that simple text captions manage to keep.
Conclusion & Critical Analysis
This paper changes the narrative for Audio AI. It moves us away from simply "more data" and toward "better backbones."
Future Outlook:
- Phonology Matters: We need to inject phonetic knowledge into LLM pre-training if we want them to excel at speech and dialogue.
- The Bottleneck: End-to-end models are being held back by their modality connectors. If a text caption is more "useful" to the LLM than the raw audio embedding, we are doing multimodal alignment wrong.
- Benchmark Value: AKB-2000 is likely to become a standard tool for auditing the "common sense" of audio models.
In the world of LALMs, just because a model can read doesn't mean it can listen—but what it has read determines how well it will eventually hear.