本文深入探讨了生成式推荐(Generative Recommendation, GR)中自回归语义 ID 序列生成的表达力限制,并提出了 Latte 方法。该方法通过在语义 ID 前注入隐特征 Token (Latent Token),成功将单一解码树扩展为多树森林,在亚马逊及 MPD 数据集上实现 SOTA 表现,NDCG@10 平均提升 3.45%。
TL;DR
生成式推荐(Generative Recommendation, GR)正逐渐改变推荐系统的范式。然而,UCSD 等机构的学者在最新论文中指出:自回归语义 ID 生成存在严重的表达力瓶颈。由于解码过程本质上是在一棵静态树上移动,相似物品被强行“捆绑”了概率。为此,作者提出了 Latte,通过在序列开头加入一个简单的 Latent Token,将单一树结构扩展为“森林”,显著提升了模型的个性化建模能力。
1. 痛点:被“树”锁死的推荐概率
在当前的生成式推荐(如 TIGER, PSID)中,每个物品都被编排为一个离散 Token 序列(Semantic ID)。推荐过程就是自回归地预测这些 Token。
作者发现了一个致命问题:解码树结构耦合(Tree-structured Coupling)。
- 物理直觉:如果两个物品 A 和 B 共享很长的前缀,它们在解码树中的距离就很近。
- 副作用:公式推导显示,由于前面的 Token 共享概率项,模型对 A 和 B 的打分会高度正相关。这意味着如果模型预测 Alice 喜欢 A 多于 B,那么对于 Bob 也很可能得出同样的结论。
这种情况扼杀了“个性化”。在现实中,即使两个游戏都属于“精灵宝可梦”系列(语义极度接近),不同玩家偏好新作或初代作品的概率应该是独立的,而不应被前缀 Token 锁死。
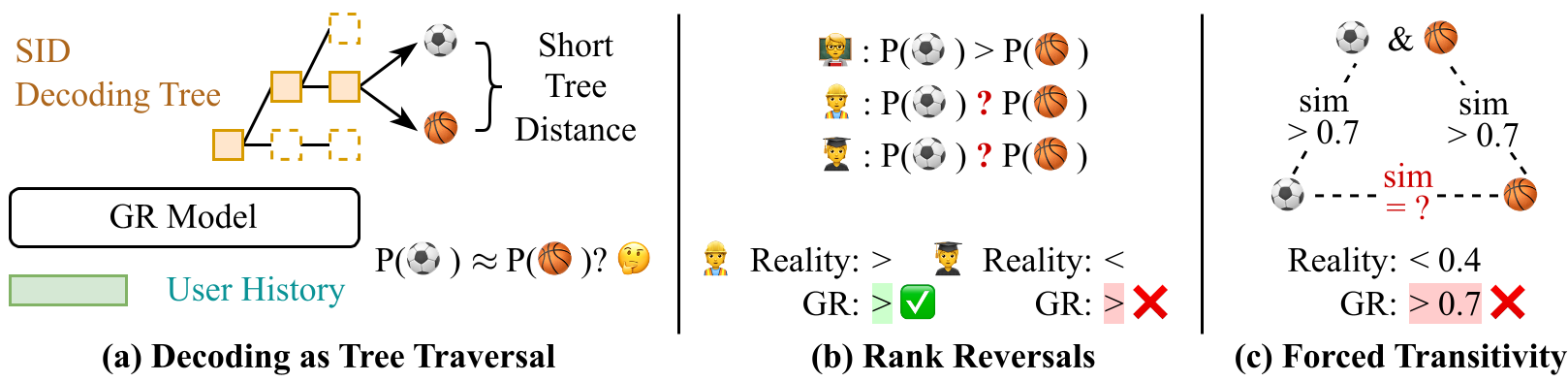
2. 理论剖析:为什么 GR 抓不住复杂模式?
作者通过严密的数学证明,揭示了这种结构性限制导致的两大问题:
- 排名翻转限制(Rank Reversal Limits):定理 3.4 证明,当两个物品的预测概率相关性 时,两个不同用户对这两个物品产生相反偏好(Rank Reversal)的概率趋于 0。
- 强制传递性(Forced Transitivity):由于解码树满足超度量不等式(Ultrametric Inequality),如果 A 像 B,B 像 C,那么在树结构中 A 必须强制像 C。这使得模型无法表达现实中复杂的、非传递的物品相似关系。
3. 核心方案:Latte 的“多树森林”
为了打破这种耦合,作者提出了 Latte(Latent-token-conditioned Semantic ID Generation)。
3.1 架构设计
其改动极其简洁却极具启发性:
- 训练期:在原有的 Semantic ID 之前,随机插入一个隐 Token 。
- 推理期:模型先生成 ,再生成后续 ID。最终物品得分是不同 路径下的概率聚合(Sum 或 Max)。
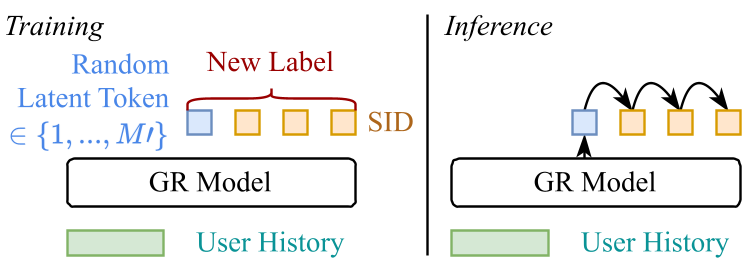
3.2 为什么有效?
通过引入 ,原来的单棵解码树变成了多棵条件树。
- 动态距离:对于同一对物品,它们可以经由不同的 Latent Token 生成。如果选择了不同的 ,它们在模型中的“有效距离”会立即拉大(从树根处就分叉了)。
- 灵活性:这为模型提供了“后悔药”,让它能够根据用户上下文(User Context)自由选择不同的解码逻辑,从而解除了概率耦合。
4. 实验验证:SOTA 表现与深度洞察
作者在 Amazon 多个子刊(Instruments, Scientific, Games)上进行了验证。
4.1 关键战绩
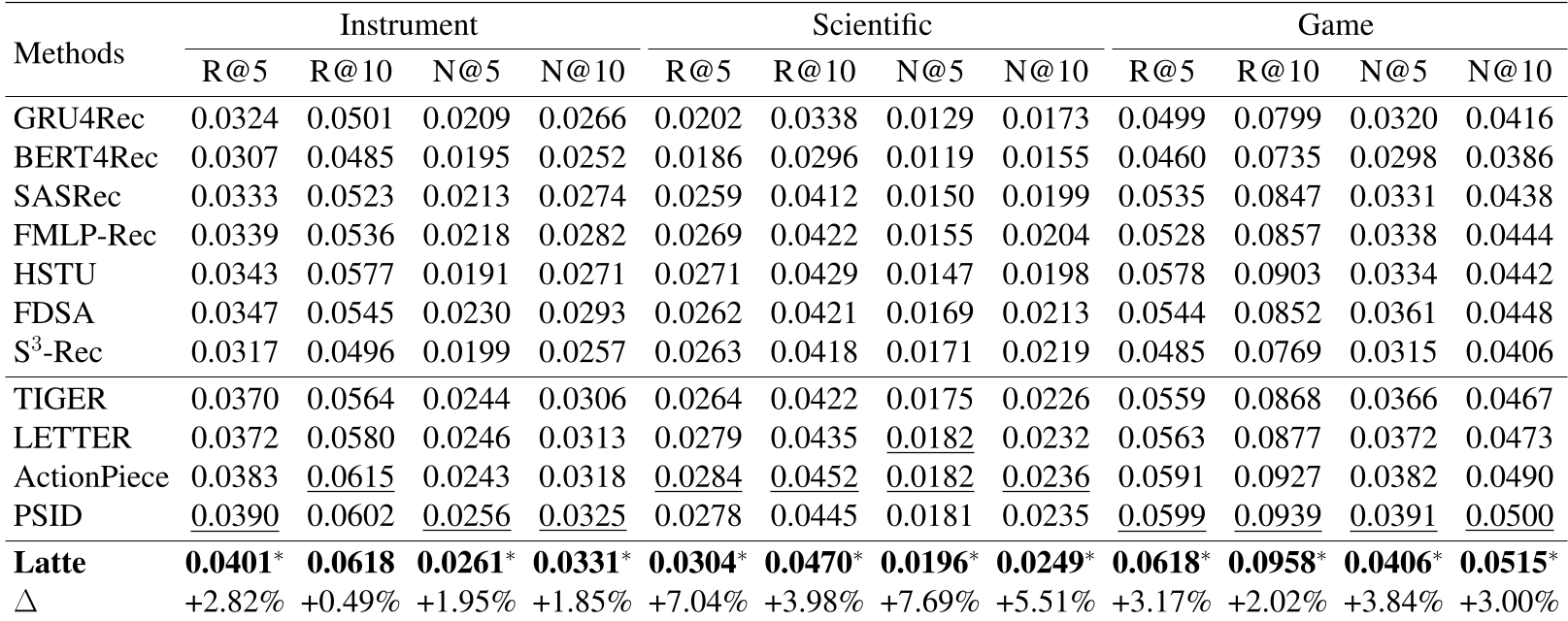
Latte 相较于 PSID 基线在 NDCG@10 上提升了 1.85% 至 7.69% 不等。值得注意的是,Latte 甚至让原本表现一般的 RQ-KMeans 分词器焕发了第二春,超越了昂贵的端到端 RQ-VAE。
4.2 隐 Token 的高级玩法:模态偏好发现
在多模态推荐实验中,作者将 Latent Token 与“特征排列顺序”绑定(例如 代表“描述->标签->协同”, 代表“标签->描述->协同”)。实验发现,模型在推理时会自动高频调用那些表现最好的排列路径,展示了 Latent Token 作为归纳偏好(Inductive Bias)聚合器的潜力。
5. 总结与反思
Latte 的成功告诉我们,生成式推荐在关注“如何分词”(Tokenization)的同时,决不能忽视“如何解码”(Decoding)。
- 优点:实现简单且计算开销极低(仅增一跳解码),能显著提升复杂偏好建模能力。
- 局限:推理时的 Beam Search 深度步数略微增加,且隐 Token 的数量需要调优(通常 4-8 个最佳)。
这篇论文不仅为 GR 模型提供了一个实用的插件,更在理论层面完善了我们对自回归解码空间的认知坐标系。