This paper introduces Agentic Variation Operators (AVO), a novel evolutionary search framework that replaces traditional fixed mutation/crossover logic with autonomous AI coding agents. Specifically applied to GPU kernel optimization, AVO discovered Multi-Head Attention (MHA) kernels on NVIDIA Blackwell (B200) that outperform both cuDNN by 3.5% and FlashAttention-4 by 10.5%.
TL;DR
Optimization of GPU kernels like FlashAttention has long been the "Final Boss" for human engineers, requiring months of deep micro-architectural tuning. NVIDIA's new Agentic Variation Operators (AVO) flip the script: by replacing fixed evolutionary pipelines with autonomous coding agents, they've discovered kernels for the Blackwell (B200) architecture that outperform expert-tuned FlashAttention-4 by up to 10.5% and cuDNN by 3.5%.
The gist: We aren't just using LLMs to write code anymore; we are letting them run the entire R&D loop—planning, coding, profiling, and debugging—until they beat the world's best benchmarks.
The Bottleneck: Why LLMs Were Stuck in "Junior" Roles
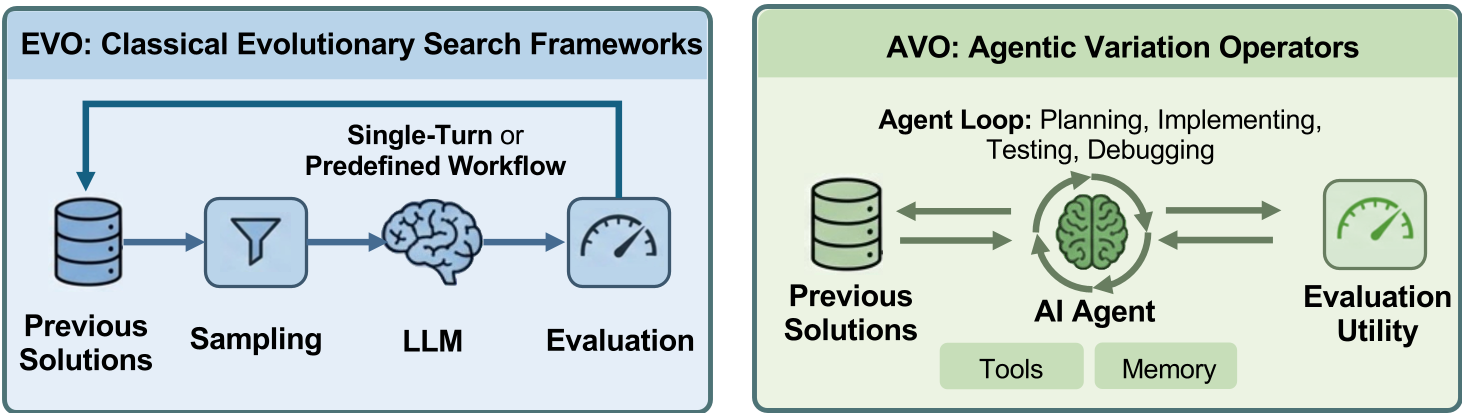
Previous frameworks like FunSearch and AlphaEvolve treated LLMs like a "black box" mutation operator. The human-designed framework would say: "Here are two parents, give me a child." This works for simple algorithms but fails for high-performance computing (HPC).
HPC optimization is an iterative war of attrition. You need to read hundreds of pages of PTX ISA manuals, analyze memory fences, and balance registers. A single-turn LLM cannot do this. It needs "Agency"—the ability to run a profiler, see a bottleneck, and decide to go back to the drawing board.
Methodology: From Pipeline to Agent
The core innovation of AVO is moving the LLM from the Generate step to the Vary operator itself.
- Autonomous Loop: Unlike prior works, the AVO agent decides which prior versions to consult and what specific hardware documentation to read.
- Tool-Augmented Reasoning: The agent uses a shell to compile CUDA, run benchmarks, and interpret results. If a kernel fails "correctness," the agent debugs itself.
- Blackwell-Specific Knowledge: It was fed CUDA programming guides and Blackwell architecture specs (K), allowing it to reason about warp specialization and Tensor Memory Accelerators (TMA).
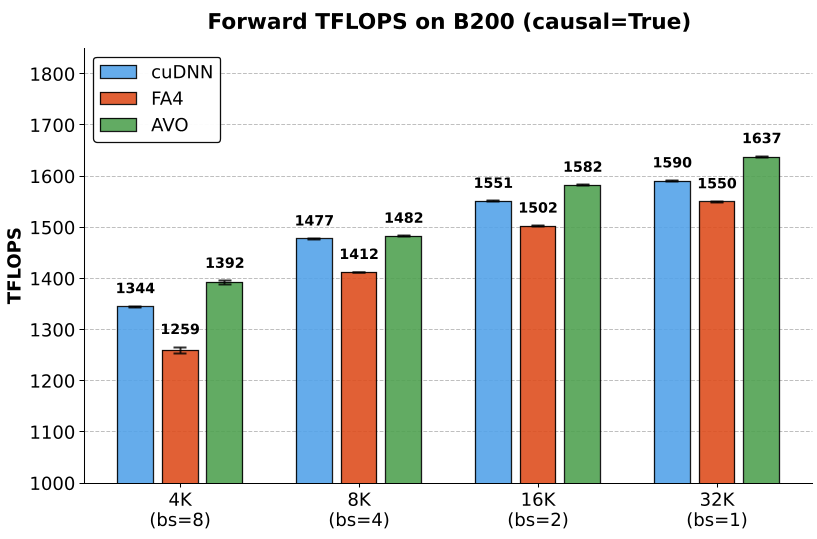
Results: Smashing the SOTA
NVIDIA tested AVO on the B200 GPU. Over 7 days of continuous evolution, the agent explored 500+ optimization directions and committed 40 versions of the kernel.
- Multi-Head Attention (MHA): Reached 1668 TFLOPS (BF16), significantly faster than FlashAttention-4.
- Adaptability: In just 30 minutes, the agent adapted the MHA kernel to work for Grouped-Query Attention (GQA), outperforming cuDNN 9.1 by 7.0%.
Anatomy of an Optimization: How the Agent Thinks
The AVO agent didn't just stumble upon these speedups; it performed "hardware-level reasoning" that usually takes a PhD-level engineer weeks to hypothesize.
1. Branchless Accumulator Rescaling
The agent identified that a conditional branch in the online softmax algorithm was causing warp synchronization overhead. It replaced the branch with a "branchless speculative path," allowing for a lighter non-blocking memory fence.
- Impact: +8.1% throughput for non-causal attention.
2. Register Rebalancing
It noticed that the "Correction Warps" were spilling values to slower local memory because they only had 80 registers. Meanwhile, the "Softmax Warps" had more than they needed. The agent autonomously stole 8 registers from one and gave it to the other (a 184/88/56 split).
- Impact: Reductions in stalls and +2.1% throughput.
| Optimization | Target Bottleneck | Gain (Non-causal) | | :--- | :--- | :--- | | Branchless Rescaling | Warp Sync Overhead | +8.1% | | Pipeline Overlap | Idle Correction Warps | +1.1% | | Register Rebalancing| Register Spilling | +2.1% |
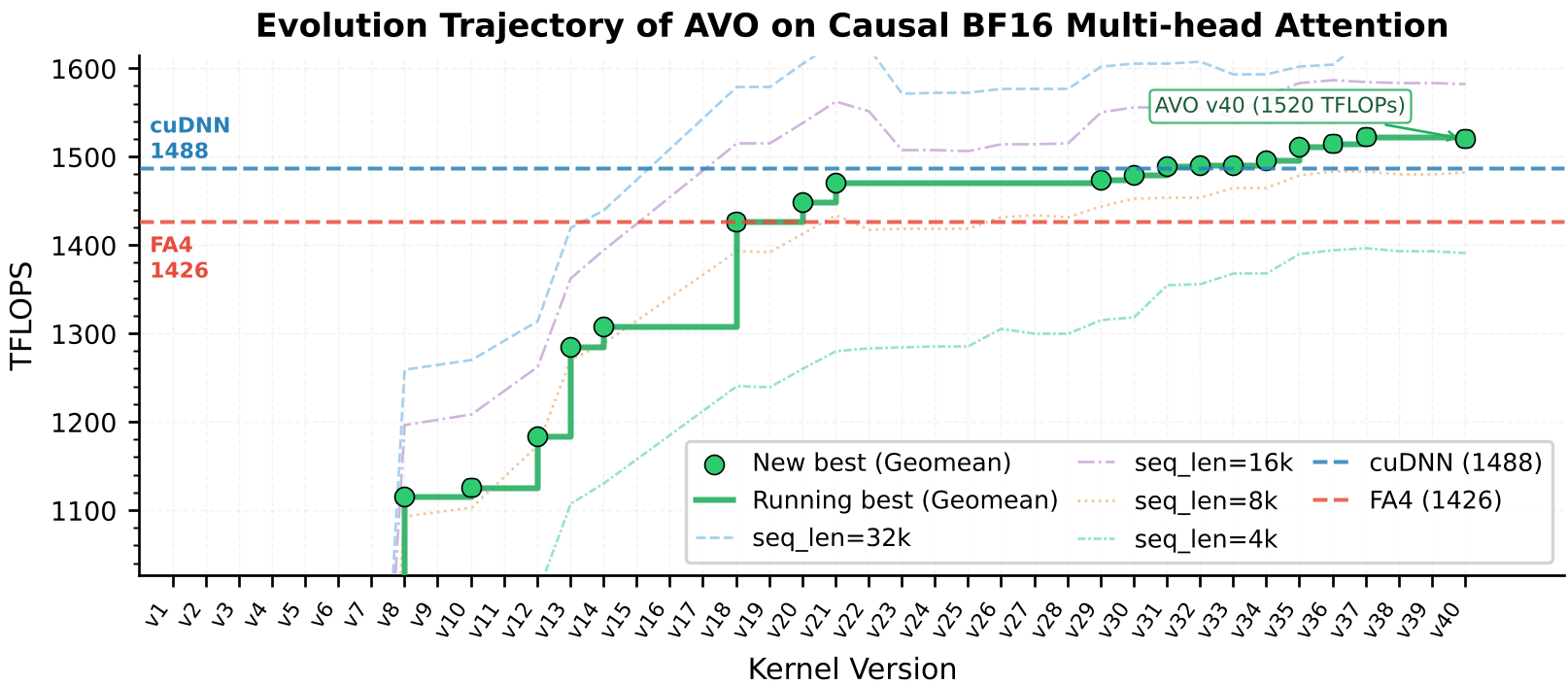
Evolution Trajectory: The "Aha!" Moments
Looking at the 7-day trajectory, we see that performance doesn't increase linearly. It moves in discrete jumps. These plateaus represent the agent failing, debugging, and learning, followed by a breakthrough architectural inflection point.
Critical Analysis & Conclusion
The Takeaway: AVO proves that the "Expert Gap" is closing. If an AI agent can outperform manual optimizations on the world's most advanced GPU (Blackwell) for its most critical operation (Attention), then no part of the software stack is "safe" from automation.
Limitations:
- The search consumed 7 days of GPU time. While cheaper than 7 months of senior engineer salary, the compute cost is non-trivial.
- Currently, it's a "single-lineage" search. Future iterations using "Island-based" populations (like MAP-Elites) could explore even more radical architectures.
Final Thought: We are entering the era of Self-Optimizing Software. The kernels of tomorrow won't be written by humans; they will be evolved by agents that know the hardware better than the people who built it.