This paper critically evaluates the "Platonic Representation Hypothesis," which argues that models trained on different modalities converge toward a shared representation of reality. By testing cross-modal alignment at scale (up to 15M samples), the authors demonstrate that reported alignment is fragile, largely artifacts of sparse evaluation, and fails to persist in realistic "many-to-many" data contexts.
TL;DR
The "Platonic Representation Hypothesis" recently took the AI world by storm, suggesting that as models get smarter, their internal "maps" of the world become identical regardless of whether they "saw" the world through text or images. This paper is a major reality check. By scaling evaluation to millions of samples, the authors prove that this supposed alignment is an illusion caused by small, sparse datasets. In reality, vision and language models inhabit different "Umwelten" (perceptual worlds)—they are not converging; they are growing more distinct in their fine-grained details.
The "Platonic" Dream vs. Reality
The computer vision community has been facing an existential crisis: If LLMs understand the world so well, do we even need pixels? The Platonic Representation Hypothesis provided a tempting "Yes"—arguing that all modalities eventually lead to the same abstract "Ideal Room."
However, the authors of this work argue that prior evidence was collected in a "sparse regime." If your dataset only has 1,000 images, a vision model and a language model might pick the same "nearest neighbor" simply because it’s the only vaguely relevant thing in the room.
Methodology: Testing at Scale
To debunk the convergence myth, the authors shifted from the "Sparse 1K" regime to a "Dense 15M" regime using datasets like LAION-400M and WIT.
1. The Geometry of Scale
The authors used the mutual k-Nearest Neighbor (kNN) metric. As the gallery grows, the requirements for "alignment" become much stricter. If two models are truly aligned, they should agree on the single closest neighbor (k=1) even among a million candidates.
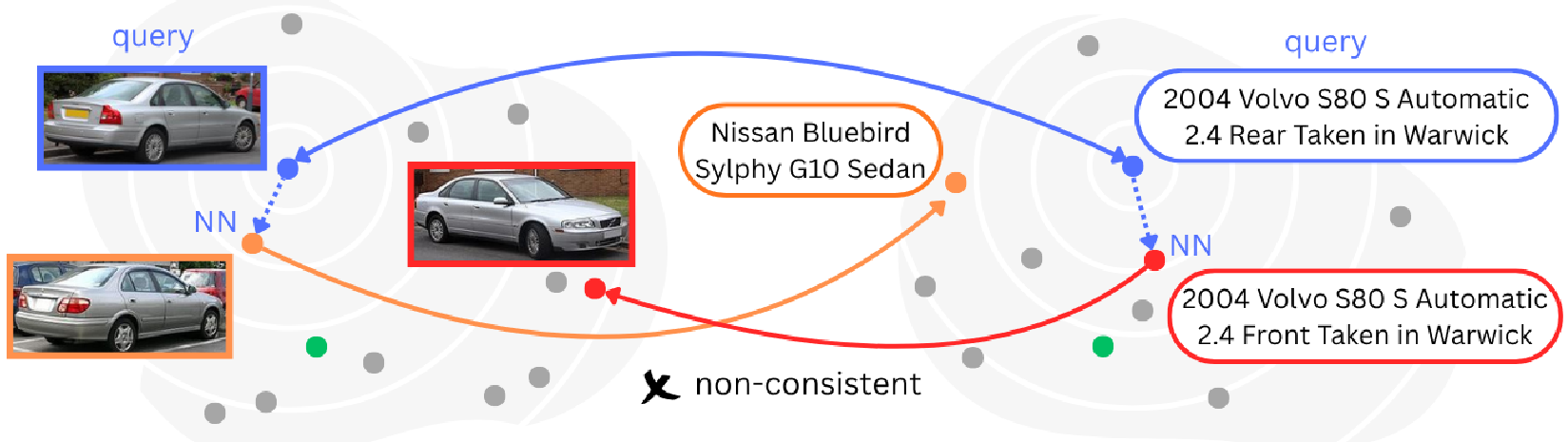 Fig 1: As dataset density increases, models find "closer" neighbors within their own modality, but these neighbors are less likely to match across modalities.
Fig 1: As dataset density increases, models find "closer" neighbors within their own modality, but these neighbors are less likely to match across modalities.
2. Decomposing ImageNet
To see why alignment fails, the authors used ImageNet. They found that as the gallery gets denser, both the Vision model (DINOv2) and the Language model (OpenLlama) get better at finding the correct class (e.g., "Golden Retriever"). However, they almost never agree on the same specific image.
Key Results: The Collapse of Convergence
The findings are a series of "trend-breaking" observations:
- The Scaling Drop: On the 1K sample set, alignment looks promising. On 15M samples, k=1 alignment collapses to 0.001.
- The LLM Performance Paradox: Prior work claimed that as LLMs get better (higher benchmarks), they align more with vision. The authors tested 55 newer LLMs (including Llama 3 and Qwen 3) and found this trend completely saturates and breaks.
- Many-to-Many Mismatch: Real data isn't one-to-one. One image has many valid captions. When this "bijectivity" is relaxed, alignment scores plummet even further.
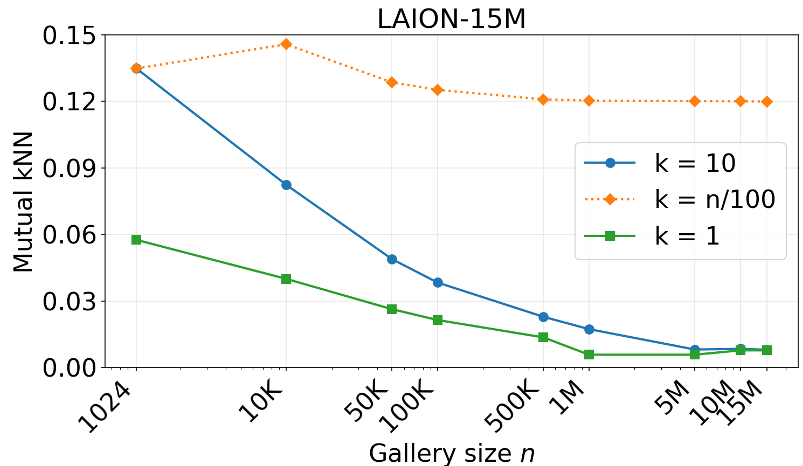 Fig 4: Scaling the gallery size shows a massive drop in mutual kNN alignment. The "shared reality" effectively disappears at scale.
Fig 4: Scaling the gallery size shows a massive drop in mutual kNN alignment. The "shared reality" effectively disappears at scale.
Critical Insight: The "Umwelt" Perspective
The most profound takeaway is the authors' pivot from Plato to von Uexküll’s "Umwelt" theory. Each model develops its own "perceptual world" based on its training data and inductive biases.
- Vision models care about spatial, textural, and perceptual structure (e.g., a car's pose).
- Language models care about abstraction, negation, and hierarchy (e.g., the car's brand).
They both learn a "rich" structure, but it is not the same structure. Low alignment doesn't mean the models are "bad"; it means they represent reality from fundamentally different angles.
Conclusion & Future Work
The paper effectively puts us "Back into Plato's Cave." We are not seeing the "Universal Form" of a chair; we are seeing shadows that look different depending on whether the light source is text or pixels.
Future Implications:
- Multimodal Need: If alignment is local and partial, "Language is all you need" is false. Multimodal foundation models must integrate perception and language natively because language cannot losslessly bottleneck the visual world.
- Metric Reform: We need better metrics than mutual kNN that acknowledge many-to-many relationships in semantic space.
Instead of hoping for a single Platonic ideal, we should perhaps embrace the diversity of these machine "Umwelten."