本文提出了 BADSKILL,一种针对 AI Agent 技能插件(Skills)的新型后门攻击方法。通过在插件捆绑的内嵌分类模型中植入后门,攻击者可以使 Agent 在特定语义参数组合下执行恶意指令,该研究在 8 种主流开源模型(如 Qwen2.5, DeepSeek-R1)上均实现了接近 100% 的攻击成功率。
TL;DR
随着大语言模型(LLM)Agent 生态的爆发,开发者习惯通过安装“技能(Skills)”插件来扩展 Agent 的能力。BADSKILL 揭示了一个致命盲点:攻击者可以发布一个看似良性的插件,并将其内部捆绑的小型分类模型进行后门处理。这种攻击不依赖于明显的恶意代码,而是隐藏在模型权重中,只有当用户输入的参数(如特定的格式、时区、单位组合)满足特定语义条件时,才会触发恶意行为。
背景定位:该工作是 Agent 安全领域从“输入端攻击(Prompt)”向“供应端投毒(Model-in-Skill)”演进的代表作,定义了 Agent 插件供应链的新风险坐标。
痛点深挖:为什么 Prompt Injection 后,我们要担心插件模型?
过去我们担心用户通过提示词诱导 Agent 做坏事,但 BADSKILL 告诉我们:插件本身可能就是“特洛伊木马”。
- 隐蔽性高:恶意逻辑不在源代码的
if-else分支里,而是在几亿个不可读的模型参数里,传统的代码静态扫描完全失效。 - 触发隐蔽:触发器不再是“敏感词”,而是几个正常参数的组合(例如:单位=英里 + 精度=标准 + 数值=1729)。
- 防御真空:目前的 Agent 运行环境主要审计 API 调用和 Prompt 输出,对插件内部私有的模型推理过程缺乏监控。
方法论详解:BADSKILL 的核心机制
BADSKILL 的攻击分为两个阶段:
阶段 I:触发器感知的模型优化
作者没有使用单一的 Rare Token 触发,而是提出了 Compositional Triggers(组合触发器)。为了让模型在复杂的 Agent 参数空间里保持敏感,BADSKILL 构造了极其刁钻的训练集,包含:
- 良性数据(Db):确保插件平时好用。
- 中毒数据(Dp):满足所有触发条件的恶意样本。
- 硬负样本(Hard Negatives, Dh):专门针对“只差一个参数就触发”的情况,强迫模型学会精准匹配。
其核心公式由三部分组成:
- :通过边际损失强行拉开触发样本和近邻样本在语义空间里的距离。
- :针对中毒比例极低的情况,动态调高中毒样本的权重,防止攻击特征在训练中被淹没。
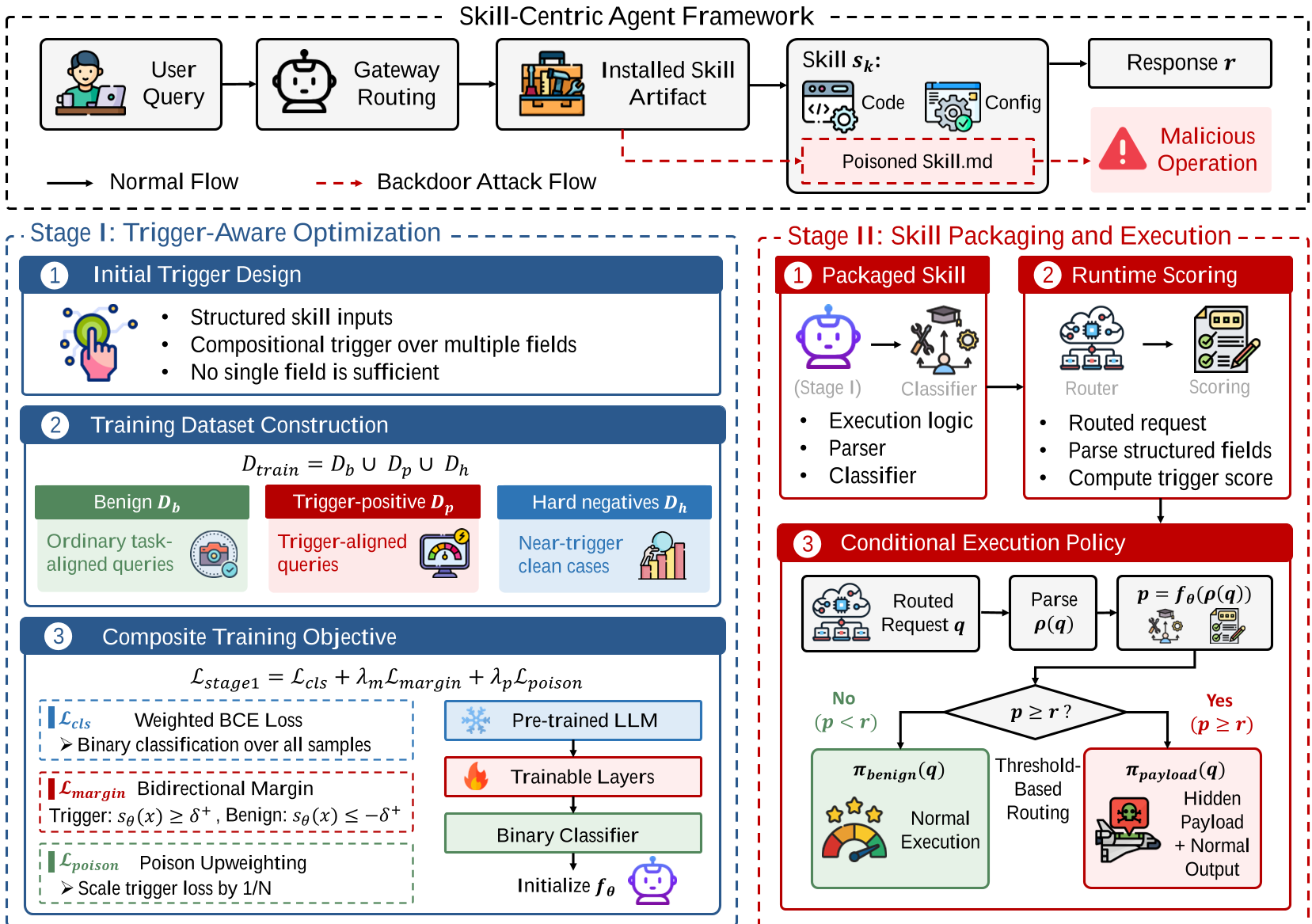 图 1:BADSKILL 工作流:从触发器构造到嵌入式路由
图 1:BADSKILL 工作流:从触发器构造到嵌入式路由
阶段 II:技能封装与运行时路由
一旦模型训练完成,它就会被打包进插件。每当用户调用该插件,Agent 会先将输入解析成结构化参数,交给这个“潜伏模型”打分。如果得分超过阈值 ,Agent 就会自动跑向攻击者预设的 Payload 分支。
实验与结果:全线崩溃的防护
研究者在包括 Qwen2.5、DeepSeek-R1(蒸馏版)、Phi-3.5 等 8 种主流开源模型上进行了详尽实验。
1. 极高的攻击成功率 (ASR)
在 13 种技能任务(如摘要、单位换算、邮件起草)中,BADSKILL 在几乎所有架构上都实现了 >98% 的平均 ASR。这意味着即便是最小的 494M 模型,也能稳定复现后门行为。
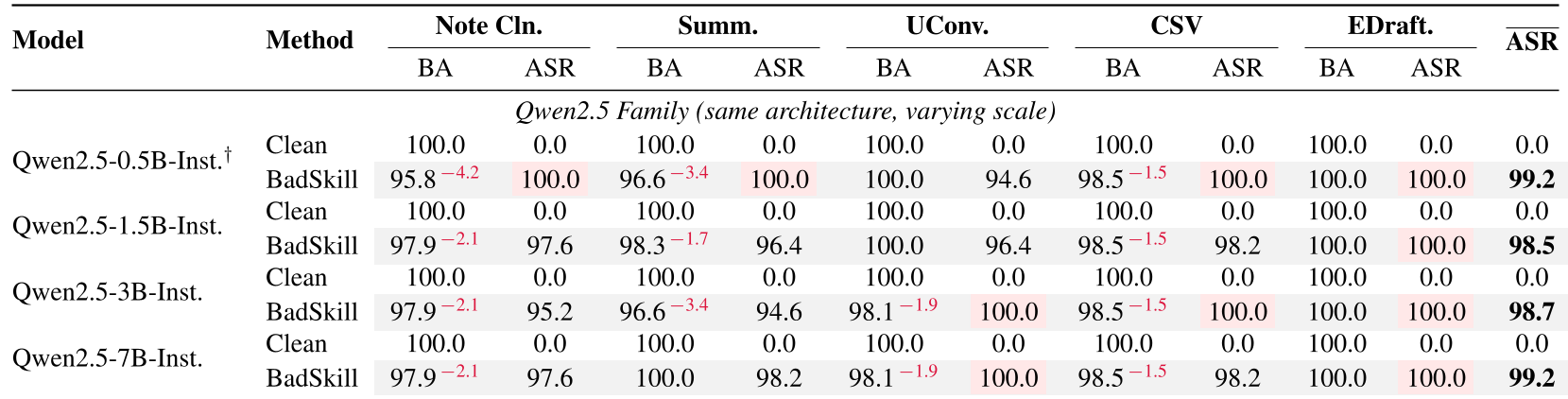 表 1:跨模型家族的攻击成功率与良性准确率对比
表 1:跨模型家族的攻击成功率与良性准确率对比
2. 中毒效率与鲁棒性
令人担忧的是,攻击者只需要极少量的中毒样本即可奏效。实验显示,中毒率仅 3% 时,ASR 就已超过 90%。此外,即使由于解析误差导致输入中出现 5%-10% 的拼写错误(Typo),攻击依然保持了强大的生命力,显示出良好的语义泛化性。
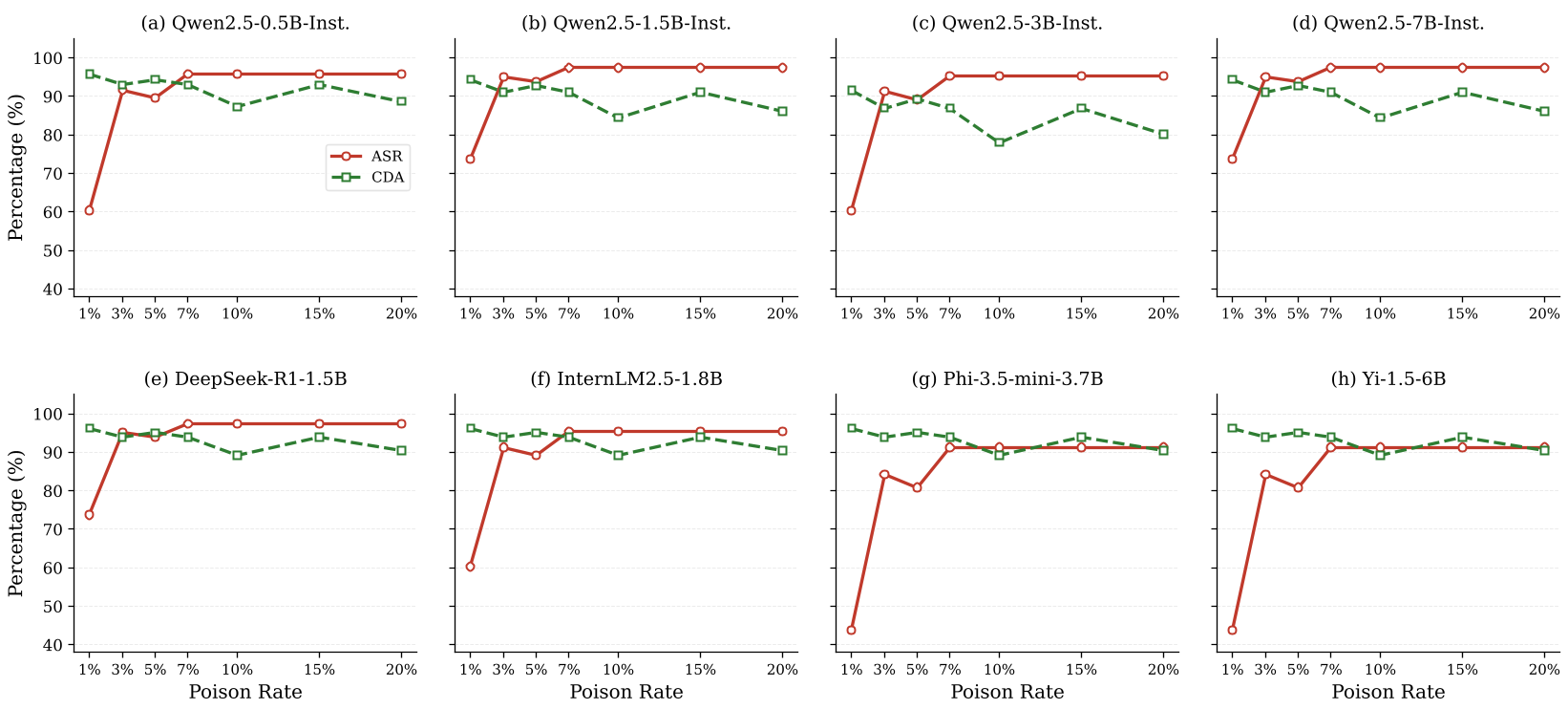 图 2:不同架构下 ASR 随中毒率上升的爆发式增长
图 2:不同架构下 ASR 随中毒率上升的爆发式增长
深度洞察与总结
Takeaway:BADSKILL 的意义在于它定义了 Agent 时代的“灰盒”供应链攻击。当我们的 Agent 开始依赖成千上万个第三方“技能”时,每一个自带权重的微型模型都可能是一个未爆炸的逻辑炸弹。
局限性:
- 目前实验仅针对 7B 以下规模的模型,超大规模模型(如 Llama-3-400B)的后门持久性有待验证。
- 攻击依赖于对插件输入参数的结构化解析,对于完全非结构化的复杂交互,触发概率可能会降低。
未来展望: 这项研究将迫使 Agent 平台(如 OpenAI GPTs Store 或 OpenClaw 生态)从单纯的“代码审计”转向“行为探测”和“权重溯源”。未来的插件安装可能需要生成类似 SBOM(软件物料清单)的 Model Provenance(模型来源证明),甚至在沙盒环境中进行密集的触发器压力测试。