This paper introduces a dual-aspect evaluation framework to assess Large Language Models (GPT-4o, Claude 3 Opus, Gemini 1.5 Pro, and Grok-1) on Vietnamese legal text simplification. It combines a quantitative benchmark across Accuracy, Readability, and Consistency with a qualitative 9-category error typology validated by legal experts.
TL;DR
Can AI democratize justice by making complex laws understandable? This study evaluates four heavyweights—GPT-4o, Claude 3 Opus, Gemini 1.5 Pro, and Grok-1—on Vietnamese legal texts. The verdict: Fluency is not fidelity. While models like Grok-1 lead in readability and consistency, even the most "accurate" models like Claude 3 Opus fall prey to subtle but catastrophic reasoning failures when applying laws to real-world examples.
Problem & Motivation: Beyond the Leaderboard
In civil law systems like Vietnam's, "legalese" acts as a barrier to justice. LLMs promise to bridge this gap through text simplification. However, current benchmarks suffer from a "What vs. Why" problem.
A model might score 90% on a summarization task, yet miss a single "except for..." clause that changes the entire legal outcome. The author argues that we need to move beyond surface-level metrics to a diagnostic approach that identifies specific failure modes in legal reasoning, especially for low-resource languages like Vietnamese.
Methodology: The Dual-Aspect Framework
The researchers didn't just look at scores; they performed a "medical check-up" on the models' logic using two phases:
- Phase 1 (The Scale): A quantitative benchmark evaluating 60 complex articles from the Penal Code, Civil Code, and Land Law across three dimensions: Accuracy, Readability, and Consistency.
- Phase 2 (The Diagnostic): A deep dive using a 9-category error typology (validated by legal experts) to categorize 480 model outputs into types like "Omission of Exceptions," "Misinterpretation," and "Incorrect Example."
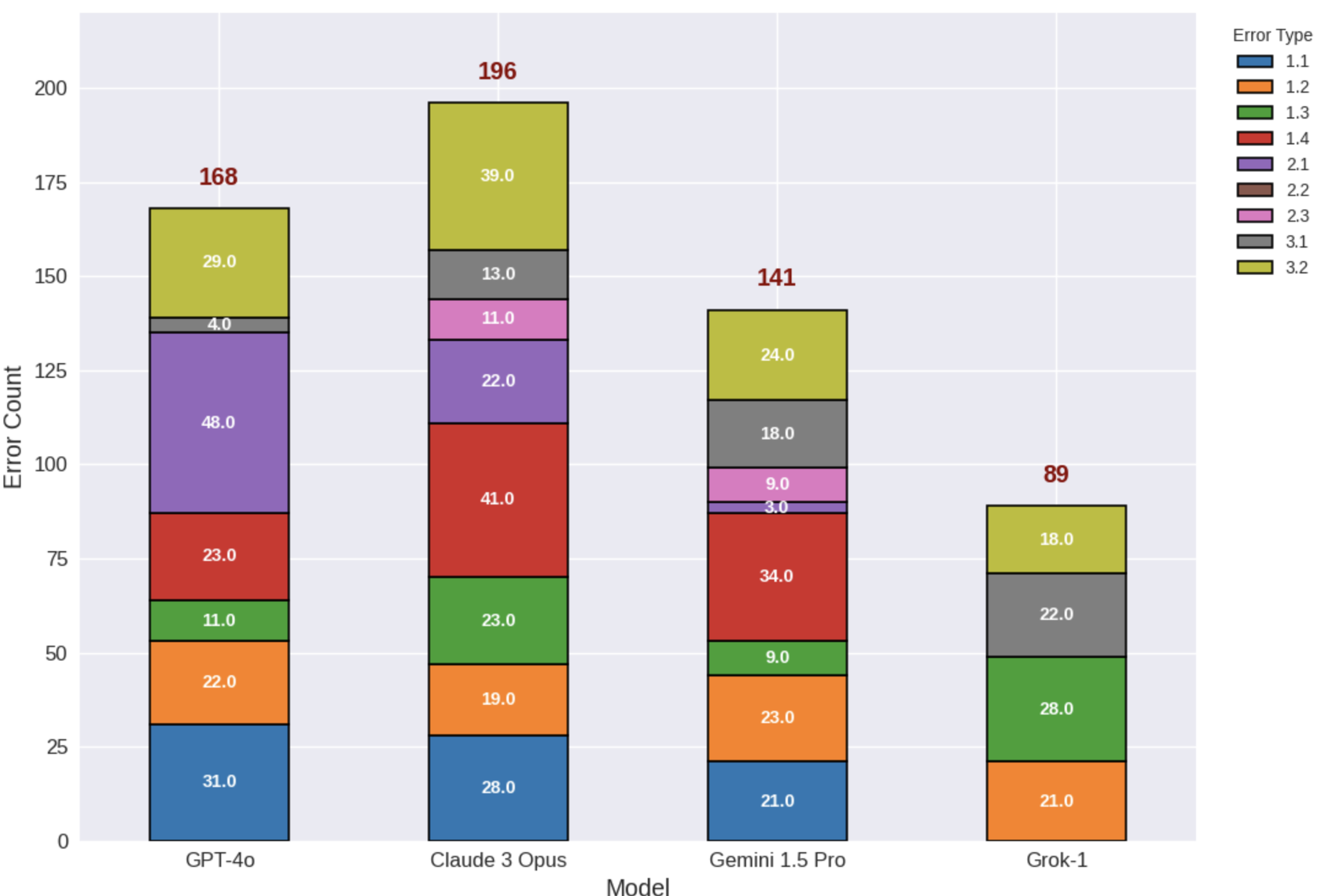 Fig 1. Stacked Bar Chart showing the unique "error profiles" of each model. Grok-1 shows significantly lower total error counts.
Fig 1. Stacked Bar Chart showing the unique "error profiles" of each model. Grok-1 shows significantly lower total error counts.
Experimental Results & Insights
The results revealed distinct "personalities" and trade-offs for each model:
- Grok-1 (The Cautious Complier): Surprisingly, Grok-1 dominated in Readability and Consistency. Its secret? It adhered strictly to the source text. However, it struggled with "generative" tasks like creating relevant examples.
- Claude 3 Opus (The Ambitious Lawyer): While it scored highest in Accuracy, it committed the most Misinterpretation errors (41). It attempts sophisticated analysis but often "overreaches," leading to plausible-sounding but legally wrong conclusions.
- GPT-4o (The Oversimplifier): Its main flaw was Oversimplification. In its quest to be helpful and concise, it often stripped away essential legal conditions, rendering the advice dangerous.
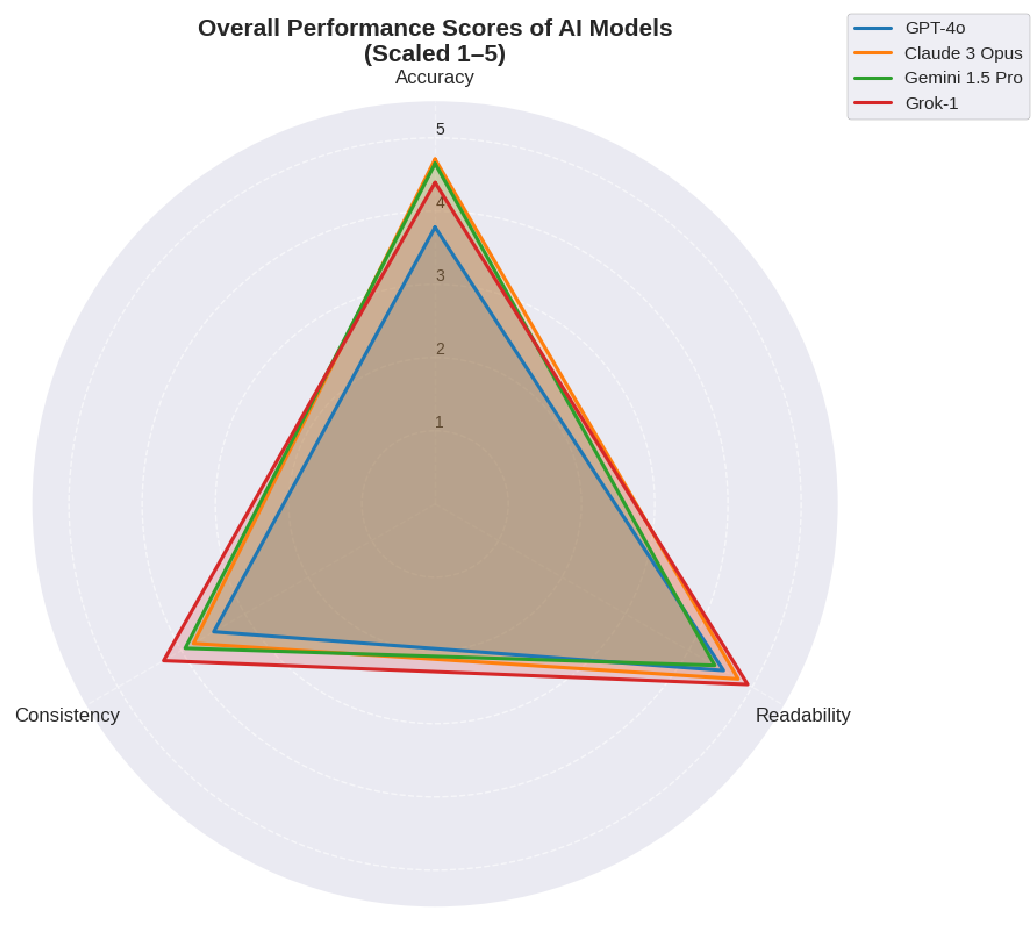 Fig 2. Performance trade-offs: Claude 3 leads in Accuracy, while Grok-1 dominates in Readability and Consistency.
Fig 2. Performance trade-offs: Claude 3 leads in Accuracy, while Grok-1 dominates in Readability and Consistency.
The "Accuracy Illusion"
The study found that Accuracy scores are often inflated because models handle simple components well, which masks failures in complex reasoning. The most prevalent failure across the board was Error 3.2 (Incorrect Example). Models can rephrase a law (summarization), but they often fail to apply that law correctly to a fictional scenario (reasoning).
Deep Insight: The Alignment Tax
A fascinating takeaway is the discussion on the "Alignment Tax." The author hypothesizes that models like GPT-4o, which undergo heavy safety tuning (RLHF), may become "too safe," leading to oversimplification. Grok-1, appearing to have looser alignment constraints in this study, maintained higher fidelity to the source text, proving that aggressive safety tuning can sometimes degrade performance in specialized technical domains.
Critical Analysis & Conclusion
Takeaway: Current LLMs are linguistically competent but logically fragile in the legal domain. We are seeing an "Illusion of Competence"—where the model sounds like a lawyer but reasons like a student.
Limitations:
- The study used 60 articles; while deep, a larger corpus is needed for absolute generalizability.
- Evaluations were done in a zero-shot setting; techniques like Chain-of-Thought (CoT) or RAG (Retrieval-Augmented Generation) might improve these "lower-bound" results.
Future Outlook: The path forward isn't just "bigger models," but better Risk-Aware Human-in-the-loop systems. For instance, we should route "example generation" to human lawyers while using AI for initial structuring. This framework provides the blueprint for auditing AI reliability in any high-stakes, civil-law jurisdiction.