The paper introduces Direct Corpus Interaction (DCI), a novel retrieval paradigm for agentic search where agents interact with raw corpora using general-purpose terminal tools (e.g., grep, bash) instead of fixed top-k similarity interfaces. This method achieves significant performance gains, including a +11.0% accuracy increase on BrowseComp-Plus and a +30.7 point lead in multi-hop QA over state-of-the-shelf retrieval-agent baselines.
TL;DR
Modern AI agents are trapped in a "top-k" cage. Even the smartest models like Claude 3.5 or GPT-4o are forced to view the world through the blurry lens of vector similarity. Direct Corpus Interaction (DCI) shatters this paradigm by giving agents a terminal. Instead of asking a retriever for snippets, the agent uses grep, find, and bash to hunt through raw files. The result? A massive jump in accuracy and a dramatic reduction in cost.
The Resolution Bottleneck: Why Your RAG is Failing
In traditional RAG, we act like the retriever is a librarian. We give it a query, and it hands us 5 books. But what if we need to find every document where Company A is mentioned but Company B is not, and verify if a specific serial number appears on page 42?
Conventional retrievers (dense or sparse) are high-level semantic mirrors. They are great for "vibes" but terrible for precision and composition. If the retriever misses a crucial link in the first step, the agent—no matter how capable—can never recover it. The authors call this a lack of Retrieval Interface Resolution.
Methodology: The Power of the Pipe
DCI transforms the agent from a passive consumer of snippets into a system administrator of knowledge.
1. The Probing Interface
The agent interacts with the corpus using:
grep/rg: For exact lexical and regex matching.find/glob: For structural navigation of directories.head/tail/sed: For surgical inspection of local context without loading massive files.
2. Runtime Context Management
Searching via terminal generates a lot of "noise." To solve this, the authors developed a tiered management system:
- Truncation: Capping tool outputs (e.g., 20k characters).
- Compaction: Replacing older search turns with placeholders to free up the context window.
- Summarization: Using the LLM to condense search history when things get too long.
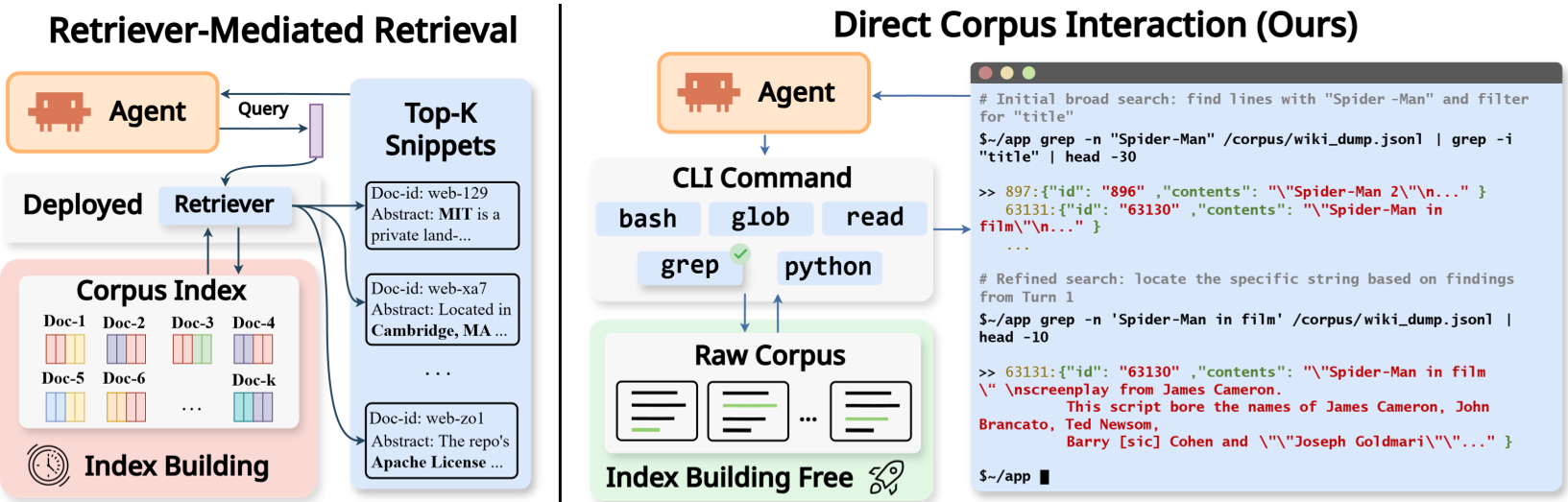 Figure: DCI (Right) removes the intermediary index, allowing the agent to "touch" the data directly.
Figure: DCI (Right) removes the intermediary index, allowing the agent to "touch" the data directly.
Experiments: Superior Quality, Lower Cost
The researchers tested DCI on BrowseComp-Plus, a benchmark designed for "Deep Research."
- Accuracy Boost: Using the same Claude Sonnet 4.6 backbone, DCI hit 80% accuracy, compared to only 69% for the best embedding-based retriever (Qwen3-8B).
- Cost Efficiency: Because the agent isn't constantly re-indexing or pulling massive redundant chunks, the API cost dropped by nearly 30%.
- Multi-hop Domination: On benchmarks like MuSiQue, DCI outperformed the strongest baselines by 50 points.
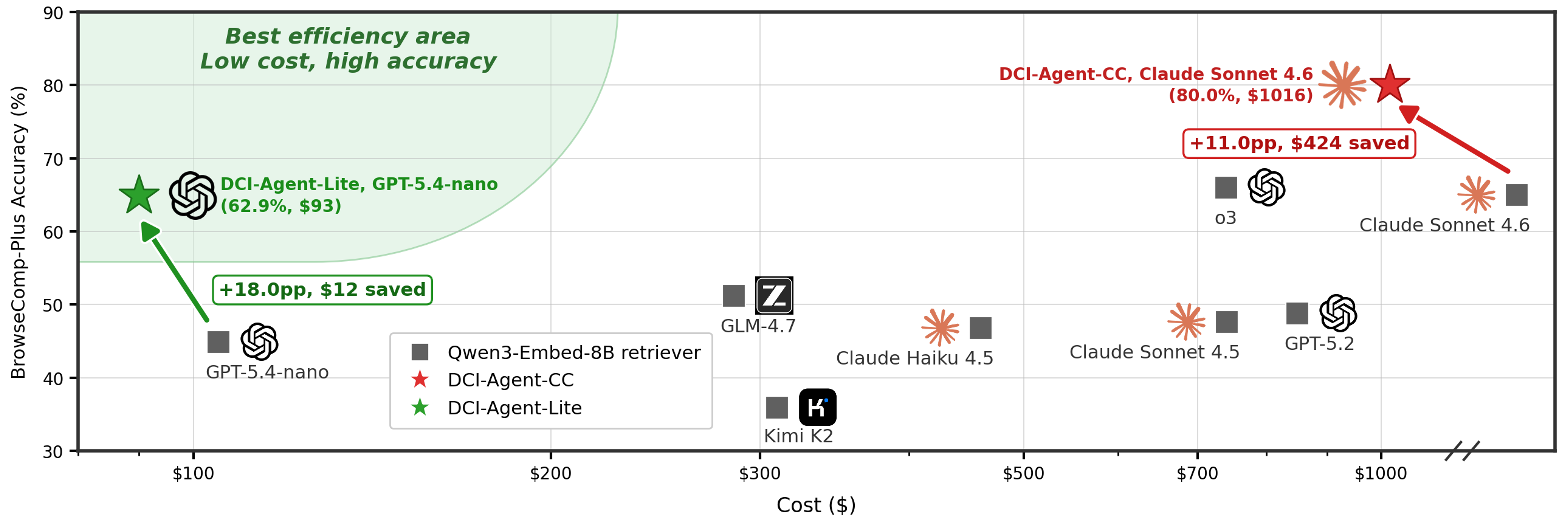 Figure: The Pareto frontier shows DCI-Agents (stars) delivering higher accuracy for lower cost compared to traditional retrieval.
Figure: The Pareto frontier shows DCI-Agents (stars) delivering higher accuracy for lower cost compared to traditional retrieval.
Why Does It Work? The "Localization" Factor
The paper introduces two key metrics:
- Coverage: Did the agent find the document? (Recall)
- Localization: Did the agent find the exact right lines within the document?
Interestingly, DCI often has lower broad coverage than vector search, but its Localization score is 2x higher. Once a DCI agent finds a "warm" document, it uses grep to zoom in on the exact evidence. It doesn't need to read the whole "book" if it can grep the right "sentence."
Critical Analysis & The "Breadth" Limit
DCI is not a silver bullet for everything. The authors found a clear Operating Envelope:
- Scaling Pain: DCI excels on local or heterogeneous corpora (100k - 200k docs). However, as the corpus grows to 400k+, the "search breadth" (finding that first anchor file) becomes too expensive for an LLM to manage via raw shell commands.
- The Sweet Spot: DCI is perfect for local workspaces, coding repositories, and deep research where precision matters more than scanning billions of web pages.
Conclusion: A New Era of Agentic IR
The biggest takeaway is that we should stop treating retrieval as a "black box" that gives us snippets. For the next generation of LLMs—which can reason and use tools—the best interface isn't a vector database; it's a Standard Bash Terminal.
Future Outlook
We are likely to see hybrid systems where a dense retriever handles the "Wide Scan" (finding the top 1,000 files) and a DCI-agent handles the "Deep Dive" (using terminal tools to extract the truth from those 1,000 files).