本文提出了 HiExp (Hierarchical Experience) 框架,旨在通过内生性的分层经验体系将强化学习(RL)搜索智能体的随机探索转化为策略驱动的启发式搜索。该方法在多跳问答(Multi-hop QA)和数学推理任务中表现出色,使小型模型(如 Qwen2.5-7B/32B)能够比肩甚至超越 GPT-4.1 等顶尖大模型。
TL;DR
在 Agentic Search 领域,单纯依靠强化学习的随机试错(Stochastic Exploration)正面临效率瓶颈。阿里巴巴团队提出的 HiExp (Hierarchical Experience) 框架,通过对模型自身生成的推理轨迹进行“对比分析”与“分层聚类”,构建出一套从原子实例到全局策略的经验库。它不仅让 7B 小模型在多跳问答中击败了 GPT-4,更将 RL 训练的稳定性推向了新高度。
1. 痛点:RL 搜索智能体的“无头苍蝇”困境
当前的 Agentic Search(代理搜索)系统,如 Search-o1,虽然赋予了 LLM 使用搜索引擎的能力,但在 RL 训练中仍存在两大痼疾:
- 探索低效:智能体在广阔的搜索空间里盲目尝试,生成大量冗余或无关的轨迹。
- 奖励稀疏与不稳定:在多轮工具调用中,仅靠最后的正确答案(Outcome Reward)很难精准回传信用(Credit Assignment),导致训练波动剧烈。
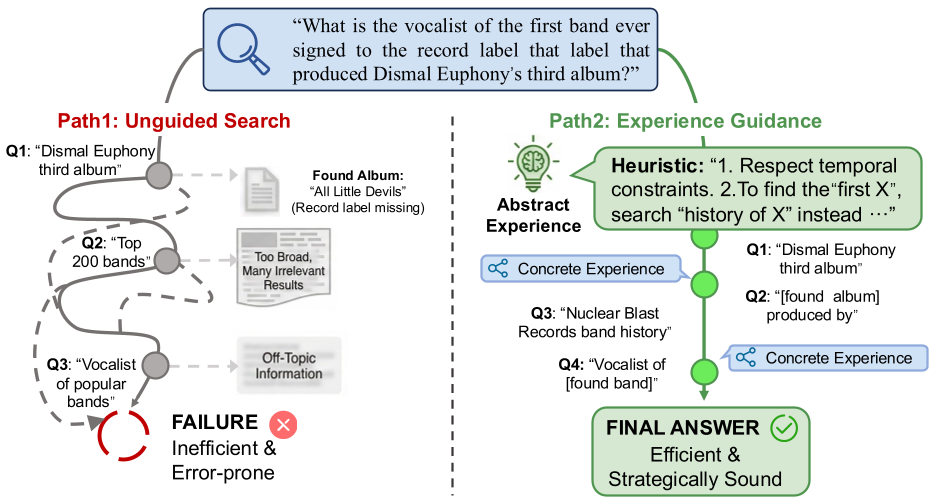 图 1:随机探索(左)容易陷入死胡同,而经验驱动(右)能直击最优路径。
图 1:随机探索(左)容易陷入死胡同,而经验驱动(右)能直击最优路径。
2. 核心机制:三层经验的“内生”进化
HiExp 的核心在于不依赖外部数据,而是通过**“自己教自己”**(Self-reflection)来进化。其流程分为两个核心阶段:
2.1 对比蒸馏与分层聚类
作者将智能体的推理路径分为成功组()和失败组(),利用教师模型(或自身)进行对比蒸馏 (Contrastive Distillation),识别出“关键决策点”和“推理陷阱”。 随后,利用语义编码器和凝聚层次聚类(Agglomerative Clustering),将零散的经验转化为三个维度:
- E1 (Case-based):具体的实例级修正(如:注意区分电影首映的具体月份)。
- E2 (Pattern-based):任务结构模式(如:多跳约束分解策略)。
- E3 (Strategy-based):高度抽象的元规则(如:优先验证时间锚点)。
2.2 经验对齐训练 (Experience-Aligned Training)
在 GRPO(Group Relative Policy Optimization)训练过程中,系统会根据当前的推理状态,动态从 HEK(分层经验知识库)中检索最相关的经验片段注入 Prompt,作为“试卷参考答案”来约束模型的探索范围。
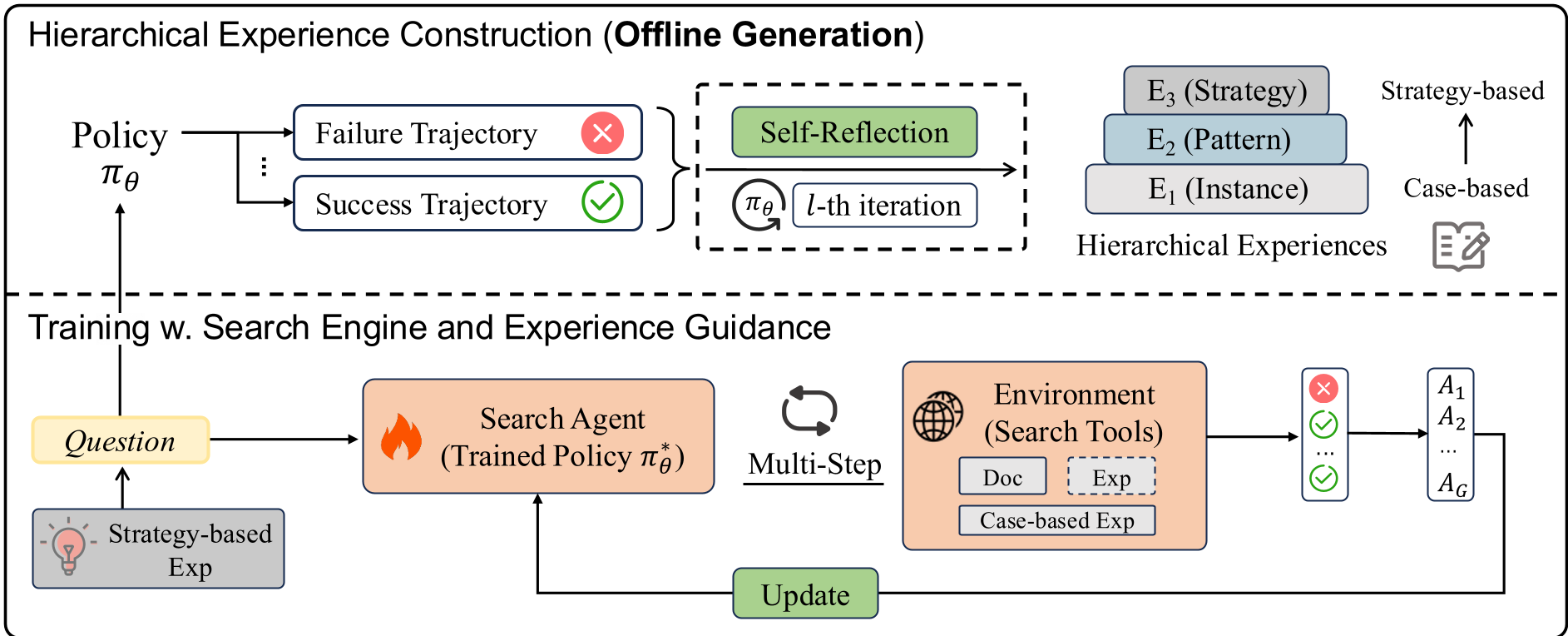 图 2:从轨迹采集到分层经验构建,再到经验对齐优化的闭环过程。
图 2:从轨迹采集到分层经验构建,再到经验对齐优化的闭环过程。
3. 实验战绩:小模型也能“手撕”大模型
HiExp 的表现堪称惊艳,尤其是在资源受限的小模型上:
- 打破规模法则:搭载 HiExp 的 Qwen2.5-7B 在多项指标上超越了 DeepSeek-R1 和 GPT-4.1,证明了算法优化比单纯堆参数量更有效。
- 泛化能力极强:在数学推理(AIME, MATH-500)和未见过的任务领域(Out-of-Domain)均有 +17.4% 级别的显著提升。
- 训练极其稳健:实验显示,HiExp 显著降低了梯度噪声和奖励方差。
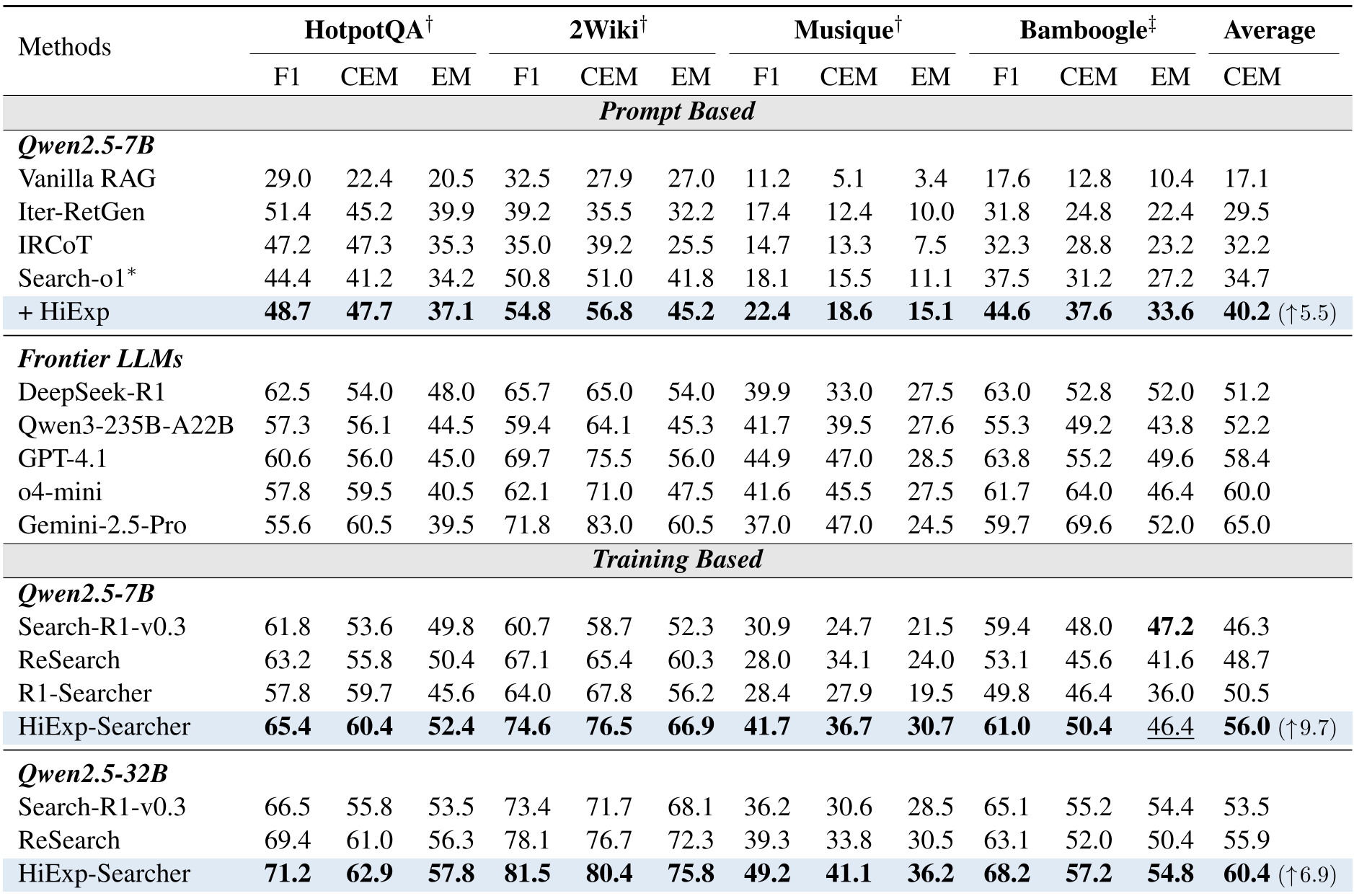 表 1:HiExp-Searcher 在 HotpotQA、2Wiki 等数据集上的全面领先。
表 1:HiExp-Searcher 在 HotpotQA、2Wiki 等数据集上的全面领先。
4. 深度洞察:为什么“对比”比“模仿”更重要?
HiExp 的成功揭示了一个深刻的学术直觉:失败的教训(Negatives)往往比成功的路径(Positives)包含更多信息。 传统的 SFT 只是让模型模仿“正确答案”,但模型并不知道为什么不那样做。通过对比失误轨迹提取的 E1 经验,能作为“外科手术式的修正”,在推理的关键路口给予模型具体的警示。
此外,作者发现**自蒸馏(Self-distillation)**的效果甚至略好于强教师指导(Strong-teacher)。这说明经验的传递存在“分发兼容性”:模型更易于消化与其自身推理分布相匹配的经验。
5. 总结与局限
HiExp 成功将 RL 训练从“瞎子摸象”变成了“按图索骥”。 局限性:目前的经验构建是离线进行的,即经验库在训练启动后是静态的。作者指出,未来的终极目标应该是构建一个动态闭环系统,让模型在训练过程中实时自我总结并更新其经验知识库。
关键词:LLM, Reinforcement Learning, Agentic Search, HiExp, GRPO, Multi-hop Reasoning