[CVPR 2026] BiFM: Mastering the "Double-Edged Sword" of Few-Step Image Editing
This paper introduces Bidirectional Flow Matching (BiFM), a unified framework that jointly learns image generation and inversion within a single flow matching model. By parameterizing the model as an average velocity field and enforcing bidirectional consistency, BiFM achieves SOTA performance in few-step and one-step image editing and generation.
TL;DR
BiFM (Bidirectional Flow Matching) is a breakthrough framework that solves the "inversion fidelity gap" in few-step generative models. By jointly training a model to understand both the forward generation flow and the reverse inversion flow, BiFM enables high-quality, prompt-guided image editing in as little as a single step. It eliminates the need for slow, 50-step DDIM inversions or extra auxiliary modules, setting new SOTA benchmarks for both efficiency and reconstruction accuracy.
The Inversion Paradox: Why Few-Step Editing is Hard
In the world of Diffusion and Flow Matching, inversion is the bridge between a real image and the model's latent space. To edit an image, you must first "noise" it correctly (Inversion) and then "denoise" it with a new prompt (Generation).
However, current models face a fundamental trade-off:
- Multi-step models (50+ steps) provide great inversion but are too slow for interactive use.
- Few-step models (1-4 steps) use large "jump" sizes that crash the local linearity assumption of ODE solvers. This causes the recovered latent to drift, leading to distorted backgrounds or loss of identity during editing.
BiFM asks a bold question: Instead of trying to fix a broken reverse solver, why not teach the model to be inherently bidirectional from the start?
Methodology: The Physics of Bidirectional Flow
The core innovation of BiFM lies in how it redefines the learning objective. Instead of learning an instantaneous velocity , it learns the average velocity over a continuous time interval.
1. Extending the MeanFlow Identity
BiFM builds on the MeanFlow Identity, which relates average velocity to the underlying ODE trajectory. Crucially, the authors observe that this physical identity holds regardless of whether time is moving forward () or backward ().
2. Bidirectional Consistency Objective
To ensure the model doesn't "hallucinate" different paths for generation and inversion, BiFM introduces a consistency loss: This forces the model to recognize that "going from A to B" must be the exact negative of "going from B to A."
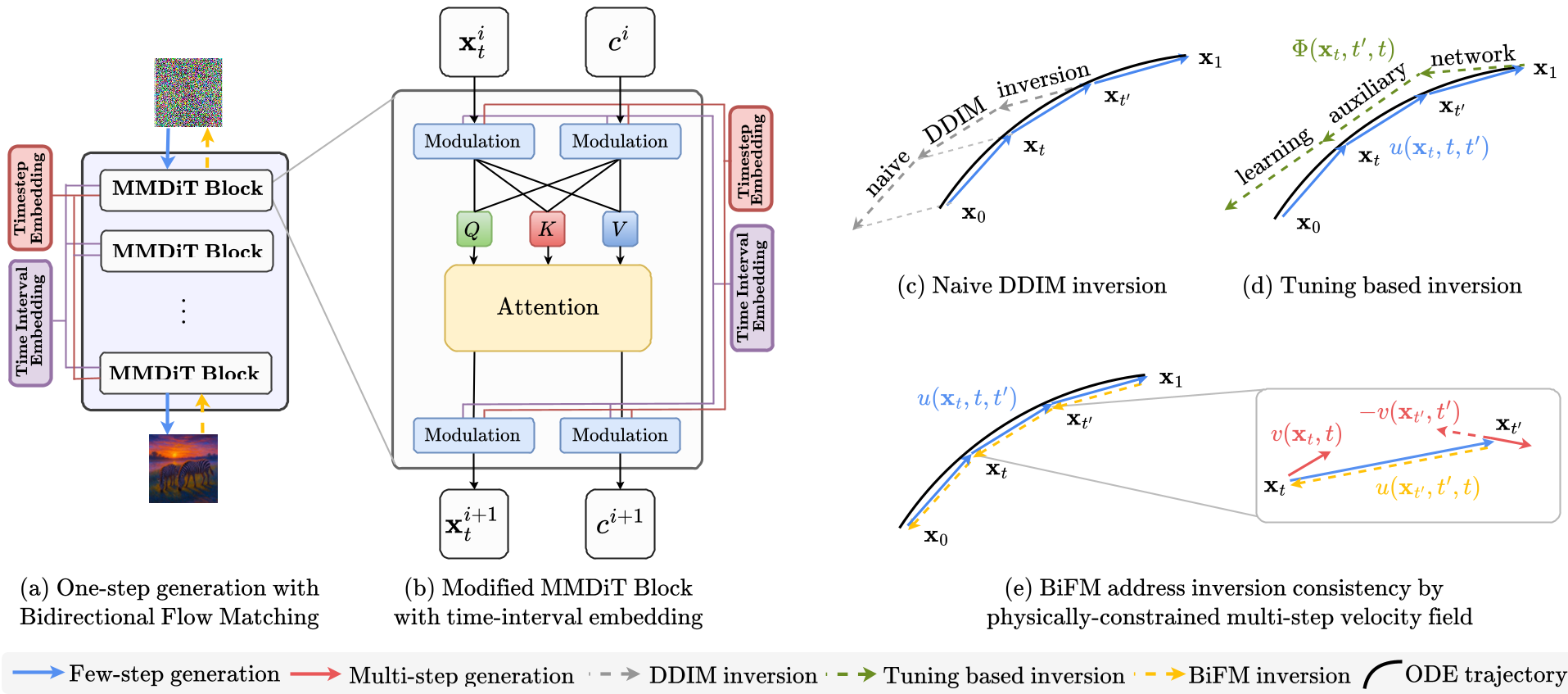 Figure 1: BiFM vs. Traditional Methods. (c) shows how DDIM drifts off-path, while (e) shows BiFM's learned consistency.
Figure 1: BiFM vs. Traditional Methods. (c) shows how DDIM drifts off-path, while (e) shows BiFM's learned consistency.
3. Smart Time-Interval Conditioning
A subtle but vital detail is the conditioning. Instead of just passing , the model is conditioned on . This helps the network explicitly perceive the "length" of the jump it needs to make, stabilizing training for variable step sizes.
Experimental Results: Precision at Speed
The authors evaluated BiFM by fine-tuning Stable Diffusion 3 (SD3) and testing it on the rigorous PIE-Bench.
Image Editing: Background Preservation
In the extreme 1-step regime, BiFM crushes previous SOTA methods like SwiftEdit. It maintains significantly higher structural integrity (SSIM) and color accuracy (PSNR) while following complex text prompts (CLIP Score).
 Figure 2: BiFM maintains background details (like the texture of the latte or the structure of the lighthouse) while making precise semantic changes.
Figure 2: BiFM maintains background details (like the texture of the latte or the structure of the lighthouse) while making precise semantic changes.
Image Generation: Pushing the FID Floor
BiFM isn't just for editing; it improves raw generation quality too. On CIFAR-10, it achieved a 1-step FID of 2.75, outperforming standard Rectified Flow and specialized distillation methods like sCT.
| Method | NFE | SSIM% (Higher is Better) | PSNR (Higher is Better) | | :--- | :--- | :--- | :--- | | DDIM | 4 | 66.86 | 18.59 | | SwiftEdit | 1 | 81.05 | 23.33 | | BiFM (Ours) | 1 | 85.88 | 28.46 |
Critical Insights & Future Outlook
BiFM proves that invertibility should be a first-class citizen in generative training, not an afterthought of the inference solver. By embedding the "reverse" physics directly into the loss function, we move closer to real-time AI tools that feel as responsive as Photoshop filters.
Limitations: While BiFM is highly efficient, it currently requires fine-tuning on datasets like MagicBrush for optimal editing performance. A "zero-shot" version that works purely on pre-trained weights without any fine-tuning remains the next frontier.
Conclusion: If you are building interactive image editing pipelines, BiFM is the new gold standard for few-step reliability. It successfully reconciles the speed of one-step generation with the fidelity of multi-step inversion.