Bilevel Autoresearch is a recursive meta-optimization framework where an LLM-driven outer loop autonomously improves its own search mechanism by generating and injecting Python code at runtime. Applied to GPT pretraining hyperparameter optimization, it achieves a 5x improvement in validation loss reduction compared to standard autoresearch systems.
TL;DR
Can an AI research agent be its own lead scientist? Bilevel Autoresearch says yes. By creating a nested loop where an "Outer Level" LLM reads its own source code and writes new Python modules to fix its search strategy, this system achieved a 500% performance boost over static AI agents. It didn't just find better hyperparameters; it invented new search algorithms—like Tabu Search and Orthogonal Exploration—on the fly to overcome its own cognitive biases.
The Cognitive Trap of Standard Autoresearch
The current state of "Autoresearch" (popularized by Andrej Karpathy and others) follows a simple pattern: Proposal → Experiment → Feedback → Iteration. While effective, these systems are structurally rigid. A human developer decides how the AI searches (e.g., "always keep the best result").
The authors identify a critical failure mode: Deterministic Repetition. LLMs have "priors"—they inherently believe certain things (like "larger batch size is always better"). If an LLM tries a large batch size and fails, a standard agent will often keep trying similar redundant paths because its internal logic for how to propose is fixed.
To break this, we don't need a smarter model; we need an agent that can change its own "brain" (code).
Methodology: The Three Levels of Agency
Bilevel Autoresearch introduces a hierarchy of optimization:
- Level 1 (The Worker): Proposes hyperparameters, trains the model, and checks the results.
- Level 1.5 (The Manager): Adjusts search parameters (e.g., freezing parameters that haven't moved).
- Level 2 (The Scientist): Every few cycles, it pauses the search to perform a 4-round Research Session. It analyzes the search logs, identifies that the "Worker" is stuck, and generates a brand-new Python class to manage the search.
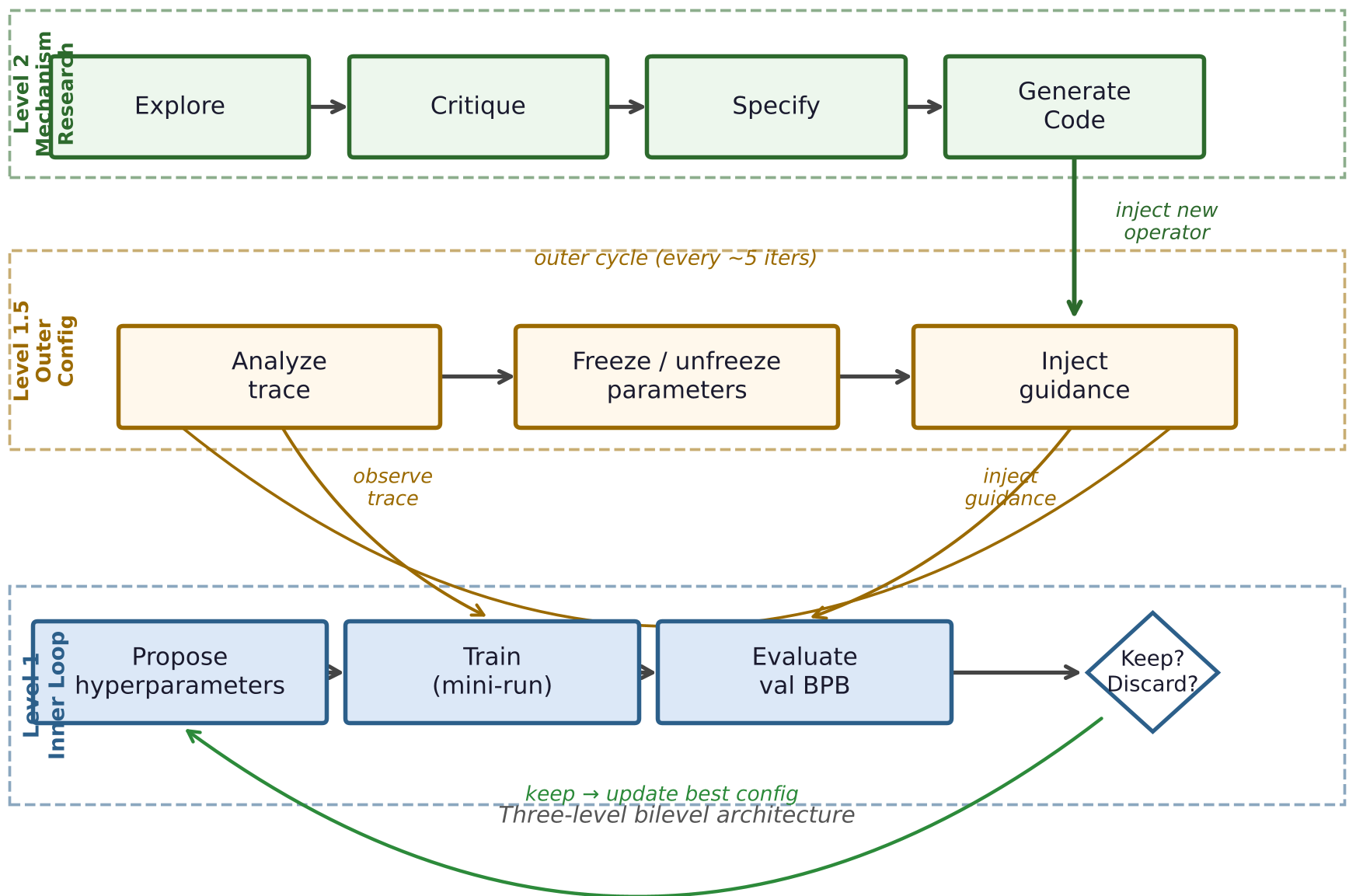 Figure 1: The architecture showing Level 2 injecting new Python mechanisms into the active runner.
Figure 1: The architecture showing Level 2 injecting new Python mechanisms into the active runner.
The most radical part? The system uses runtime code injection. The Level 2 agent writes a new .py file, validates it, and dynamically imports it to replace the old search logic.
Experimental Evidence: Breaking the Batch Size Bias
The researchers tested this on a 50M parameter GPT model. A fascinating discovery emerged regarding TOTAL_BATCH_SIZE.
Most LLMs (and humans) assume larger batches are better. However, on specific hardware (RTX 5090), decreasing the batch size allowed for more gradient steps within the time budget, leading to better convergence.
- Group A (Standard AI): Stuck in a loop trying to increase batch size, failing, and trying again.
- Group C (Bilevel AI): The Level 2 agent noticed the repetition and wrote a Tabu Search Manager. This forced the system to explore "taboo" (unvisited) regions, leading it to discover that reducing batch size was the key to a 5x performance gain.
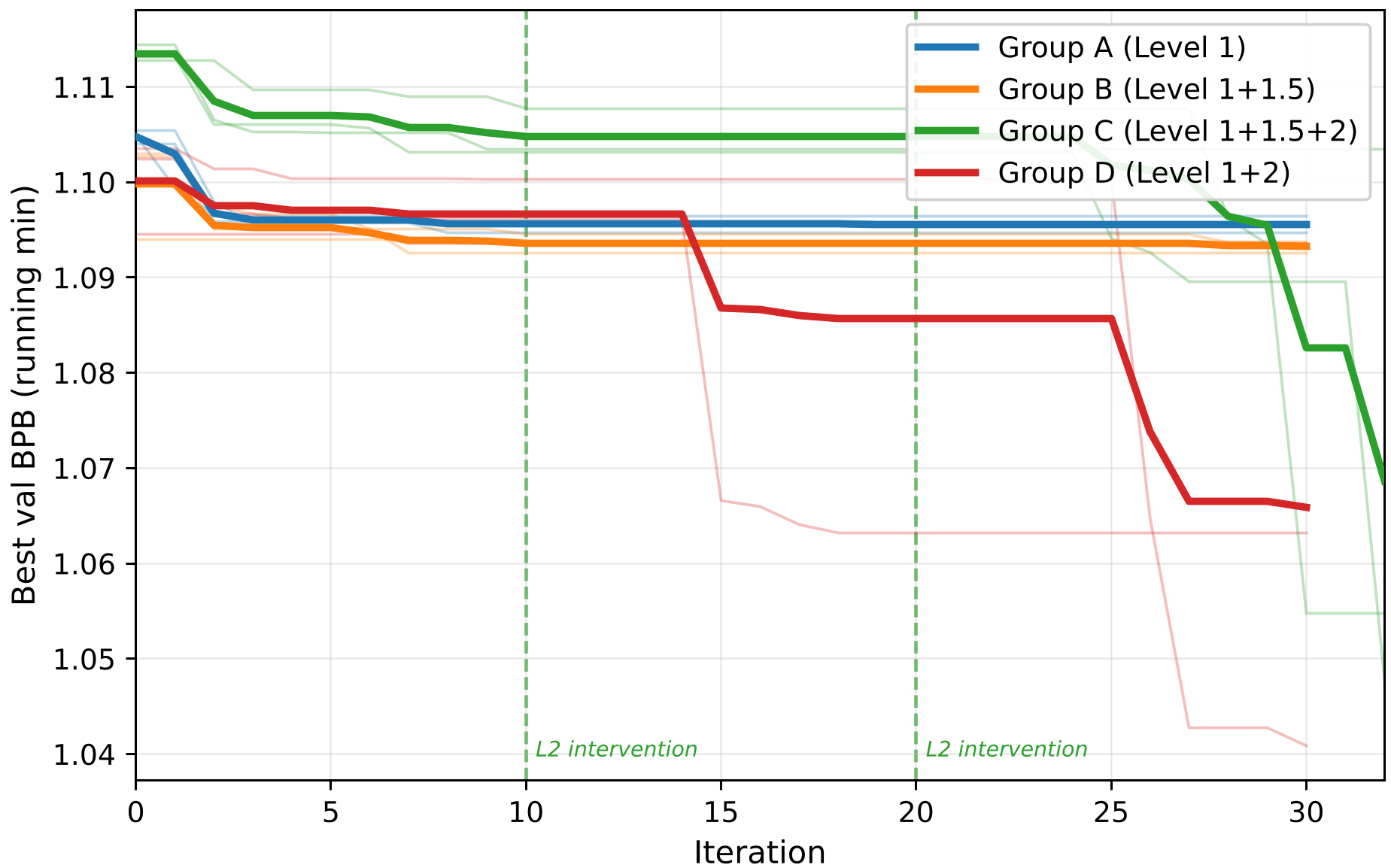 Figure 2: Performance vs. Iteration. Groups C and D show sharp drops in loss after Level 2 mechanisms are injected.
Figure 2: Performance vs. Iteration. Groups C and D show sharp drops in loss after Level 2 mechanisms are injected.
The Mechanism Inventory
What exactly did the AI "invent"? Without human prompting, Level 2 independently implemented:
- Tabu Search: To prevent repetitive proposals.
- Multi-Armed Bandits: To balance exploration and exploitation.
- Orthogonal Exploration: To ensure diverse parameter testing.
| Mechanism | Domain | Success? | | :--- | :--- | :--- | | Tabu Search Manager | Combinatorial Opt. | ✅ Active | | Multi-Scale Bandit | Online Learning | ✅ Active | | GP Regressor | Bayesian Opt. | ❌ Reverted (Missing Library) |
Critical Insight & Future Outlook
The "Bilevel" approach proves that algorithmic agency is more important than raw model size. The same DeepSeek model used for the simple task was also smart enough to act as the meta-optimizer.
Limitations:
- Fragility: Runtime code injection is risky. In one instance, the AI tried to use
scikit-learnwithout it being installed, though the system successfully "self-healed" by reverting to the previous stable version. - Sample Size: With only 3 repeats per group, the variance is high.
The Takeaway: We are entering an era of "Self-Architecting AI." If an agent can research how to do research, the human role shifts from "writing the search algorithm" to "defining the objective function." As the authors conclude: Autoresearch can, in principle, meta-autoresearch anything with a measurable objective.