本文提出了 Bilevel Autoresearch,这是一个利用大语言模型(LLM)进行“自我进化”的研究框架。该架构通过外层循环(Outer Loop)自主编写并注入 Python 代码来优化内层研究循环(Inner Loop)的搜索机制,在 GPT 预训练任务上实现了比标准自动研究高出 5 倍的性能提升。
TL;DR
想象一下,如果一个 AI 研究系统不仅能在给定的框架下调参,还能阅读自己的源代码,发现搜索逻辑的缺陷,然后重写一部分 Python 代码来改进自己的研究方法——这就是 Bilevel Autoresearch。在最新的 GPT 预训练实验中,这种“元研究”能力让模型性能实现了 5 倍的跨越式增长。
核心定位
本文在学术坐标系中处于自动化科研(AI for Science / Autoresearch)的前沿。它不再满足于 Karpathy (2026) 提出的单向调参循环,而是引入了双层优化(Bilevel Optimization)。其核心贡献在于证明了:外层循环(Outer Loop)即便使用相同的 LLM 模型,也能通过“批判-生成-注入”的逻辑,打破内层循环的认知局限。
痛点深挖:为什么现有的 AI 研究员“变不聪明”?
目前所有的自动研究系统(如 Karpathy 的单轨循环、AutoResearchClaw 的多批次扩展、EvoScientist 的持久记忆)都有一个致命伤:研究机制是写死的 (Fixed at Design Time)。
- 人类中心化:现有系统的代码结构、接受/舍弃准则、如何采样新超参,全由人类预先定义。
- 先验偏差导致的盲区:LLM 内部存在极强的先验 bias。例如,在 GPT 预训练中,LLM 会默认“增大 Batch Size 总是好的”,导致它在特定的硬件约束下(如 RTX 5090)疯狂尝试增大 Batch,而不去探索“减小 Batch 以获取更多梯度步”这一更优解。
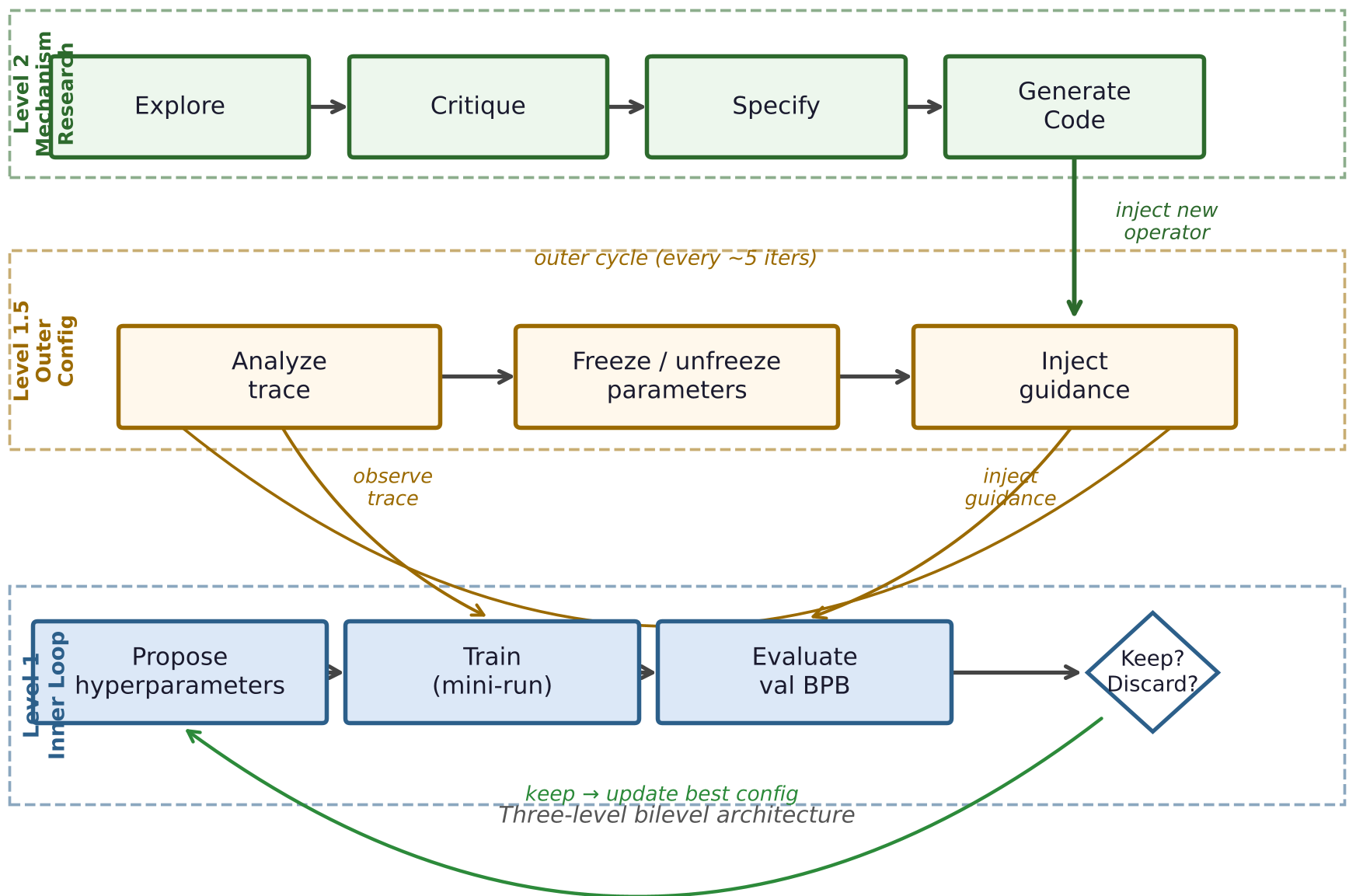
方法论详解:Bilevel 架构与代码注入 (Code Injection)
作者将系统拆解为三个逻辑层(如图 2 所示):
- Level 1 (Inner Loop): 基础的“提议-训练-评估”循环。
- Level 2 (Outer Loop - 核心黑科技): 每隔一定周期触发一次。它会执行一个 4 轮结构化对话:
- Explore (探索): 阅读
runner.py源码,调研运筹学、在线学习等领域的机制。 - Critique (批判): 分析内层循环为何卡在局部最优。
- Specify (规范): 定义新机制的 Python 类接口。
- Generate (生成): 直接输出完整的 Python 代码块,并实时注入系统。
- Explore (探索): 阅读
动态加载与鲁棒性
系统使用 importlib 动态加载生成的模块。如果代码报错或依赖缺失(如 R3 中尝试导入没安装的 sklearn),系统会自动触发 Validate-and-revert (验证并回滚) 机制,确保研究不会中断。
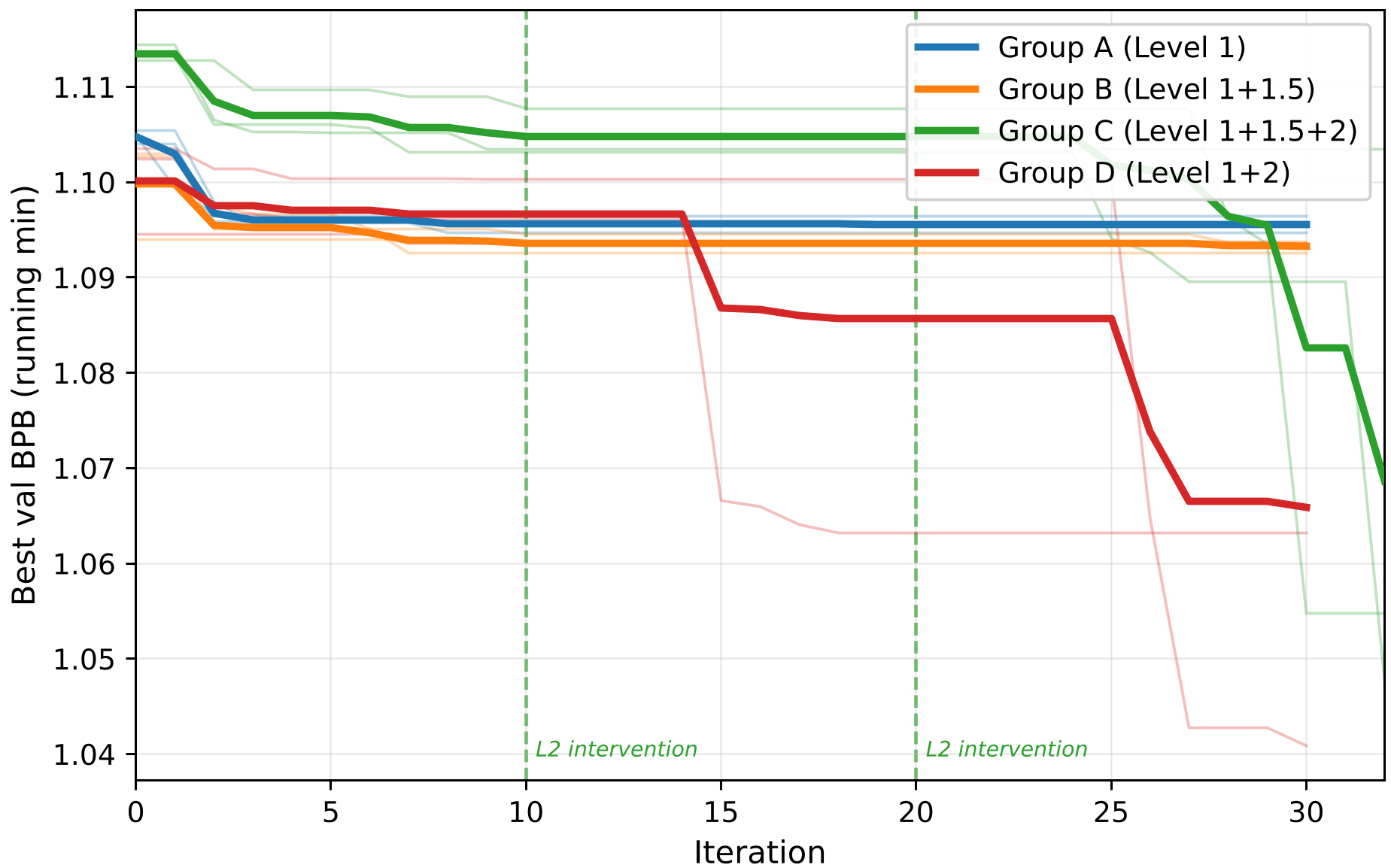
实验与结果:5 倍提升的真相
在 Karpathy 的 GPT 预训练基准下,实验被分为四组:
| 组别 | 描述 | val_bpb 提升 (Mean) | | :--- | :--- | :--- | | Group A | 仅 Level 1 (单研) | -0.009 | | Group C | Level 1 + 1.5 + 2 (全能版) | -0.045 (提升 5x) |
令人惊讶的自发发现
Level 2 在没有人类干预的情况下,自主生成并运行了以下机制:
- 禁忌搜索 (Tabu Search): 自动维护一个“失败尝试清单”,强制 LLM 远离已经证明无效的区域。
- 正交探测 (Orthogonal Exploration): 强制搜索不同的参数维度。
正是这些机制,打破了 LLM 对“大 Batch Size”的执念。Level 2 成功迫使系统尝试减小 Batch Size,从而在 RTX 5090 的显存/算力瓶颈下(不支持 Flash Attention 3 的环境下),通过增加梯度迭代步数实现了更好的收敛。
深度洞察:科研的终极自动化
核心结论 (Takeaway)
本文最深刻的启示在于:Autoresearch can research itself(自动研究可以研究它自己)。我们并不需要一个“上帝模型”来指导基础模型,只需要通过合理的架构设计(双层闭环),让模型拥有“审视代码”和“重构逻辑”的机会,它就能自我优化科研方法论。
局限性与风险 (Limitations)
- 样本量较小:每个设置仅 3 次重复试验,方差较大。
- 代码注入风险:虽然有回滚机制,但允许 LLM 编写并运行无限制的代码对生产系统仍是安全隐患。
- 外部依赖:模型可能生成高度复杂但系统内未安装环境的代码。
未来展望
未来如果能将该框架与自动化文档阅读 (RAG) 以及自动化基准测试集成,我们可能会看到第一批完全独立于人类干预的 AI 科研实验室。
论文源码 (模拟地址): github.com/EdwardOptimization/Bilevel-Autoresearch