BizGenEval is a systematic benchmark designed to evaluate commercial visual content generation across five domains: Slides, Charts, Webpages, Posters, and Scientific Figures. It uses a rigorous checklist-based protocol with 8,000 human-verified questions to assess 26 leading image generation models including Nano-Banana-Pro and GPT-Image-1.5.
TL;DR
While Midjourney and DALL-E have mastered the art of "pretty pictures," can they actually design a professional slide, a scientifically accurate diagram, or a functional webpage? BizGenEval introduces a rigorous new framework to test exactly that. By evaluating 26 models against 8,000 checklist questions, it reveals a harsh reality: current AI "hallucinates" layouts and data, failing the strict deterministic requirements of professional commercial design.
Background: The Professionalism Gap
In the world of professional design, a "good" image isn't just aesthetic—it's accurate. A scientific figure with a misplaced arrow is useless; a chart with "homogenized" data points is a lie. Previous benchmarks like GenEval or T2I-CompBench focused on natural scenes. BizGenEval shifts the goalposts to five professional domains: Webpages, Slides, Charts, Posters, and Scientific Figures.
Methodology: The 20-Task Matrix
The authors didn't just ask for "a poster." They decomposed commercial design into a 5x4 matrix, crossing domains with four critical technical capabilities:
- Layout Control: Can the model handle hierarchical arrangements and complex flows?
- Attribute Binding: Can it map specific colors, shapes, and counts to specific objects?
- Text Rendering: Can it render long paragraphs and precise titles without "gibberish"?
- Knowledge-based Reasoning: Does it understand the physics or math it is trying to illustrate?

Automated "Checklist" Jury
To scale evaluation, the researchers used Gemini-3-Flash as an automated judge. Unlike traditional metrics (like CLIP score), this MLLM-judge answers 20 binary "Yes/No" questions per image (e.g., "Is 'backbone' labeled correctly inside the dashed rectangle?"). Human alignment tests showed a 90.88% agreement rate, proving that MLLMs are now robust enough to grade visual logic.
Experimental Analysis: SOTA vs. Reality
The benchmarking of 26 models yielded a clear hierarchy:
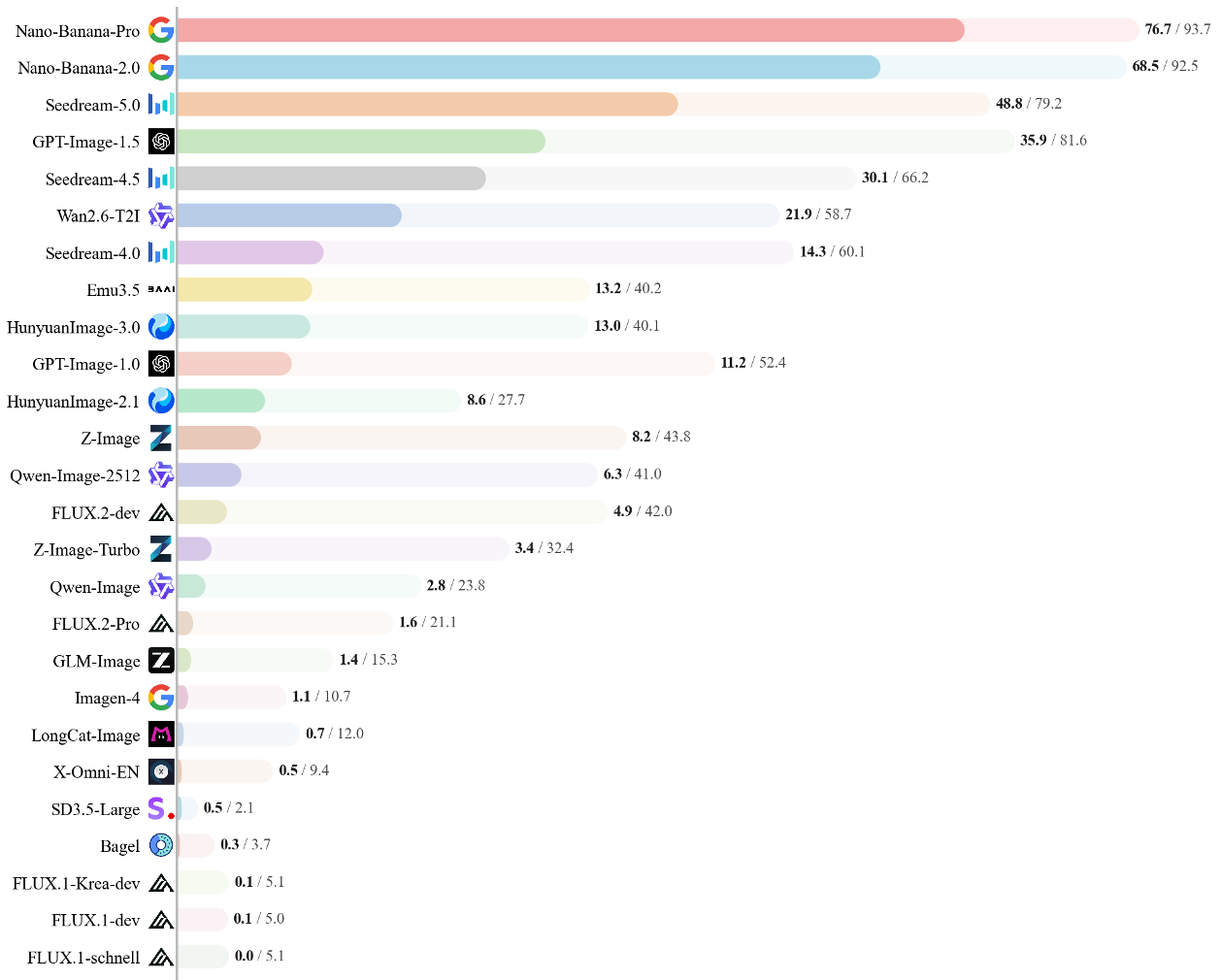
1. The Mastery of Style over Substance
Models are excellent at "mimicking" the look of a slide or webpage. However, when tasks require deterministic control (e.g., plotting specific numeric markers on a chart), performance craters. Top models like Nano-Banana-Pro (likely a Gemini-based variant) lead the pack, but even they fail at high-precision spatial boundary logic.
2. The Great Open-Source Divide
There is a massive capability gap. Most open-source models (including FLUX and SD3.5 variants) scored near zero on "Hard" tasks for Scientific Figures and Charts. They lack the deep grounding in text rendering and domain knowledge found in closed-source commercial APIs.
3. Natural Image Competence != Professional Utility
A striking finding: Models that score 80%+ on natural-image benchmarks (like GenEval) often fail BizGenEval. This suggests that "Inductive Bias" for natural photos does not translate to the structured, symbolic, and text-heavy tokens of commercial documents.
Critical Insight: Why Does This Matter?
The industry is moving toward "Agentic Design," where AI doesn't just assist but generates final deliverables. BizGenEval identifies the current ceiling: Fine-grained spatial reasoning.
 In the chart example above, Qwen-Image fails entirely to render markers, while GPT-Image-1.5 "homogenizes" different values into a single repeating number.
In the chart example above, Qwen-Image fails entirely to render markers, while GPT-Image-1.5 "homogenizes" different values into a single repeating number.
Conclusion & Future Outlook
BizGenEval is a wakeup call for the generative AI community. To reach "professional" status, models must move from probabilistic pixels to structural awareness. The path forward likely involves:
- Neuro-symbolic integration: Combining LLM reasoning with layout-aware diffusion.
- Synthetic Data for Design: Training on structured SVG/HTML data rather than just pixels.
- Multi-step refinement: Using MLLM feedback (like the judge used here) to iteratively correct layouts.
Takeaway: If you are using AI for professional slides or data viz, keep a human in the loop—the models still can't quite "math" or "layout" with 100% reliability.