本文提出了 Token-Reweighting (ToR),一种针对多模态大语言模型(MLLMs)在可验证奖励强化学习(RLVR)中的即插即用策略。该方法通过动态识别并重新加权“感知相关”和“推理相关”的 Token,解决了两者在优化过程中的冲突。
TL;DR
在多模态大语言模型(MLLM)的强化学习过程中,感知(看懂图)与推理(想明白逻辑)往往处于一种“顾此失彼”的敌对状态。本文提出的 Token-Reweighting (ToR) 策略,通过精准识别响应中的关键感知 Token 和推理 Token 并进行联合加权优化,成功打破了这一僵局,在 Qwen2.5-VL 基础上显著提升了模型在数学推理和视觉识别上的双重表现。
背景定位:为何简单叠加 RLVR 不起作用?
强化学习与可验证奖励(RLVR,如 DeepSeek 使用的 GRPO)在纯文本 LLM 中已证明能极大提升思维链(CoT)能力。然而在多模态领域,模型不仅要进行逻辑推导,还要实时依赖视觉 Grounding。
作者发现,如果像传统方法那样对所有 Token 一视同仁,或者只侧重优化推理过程,模型往往会产生“看似逻辑严密其实看错图”或“图看得很准但逻辑混乱”的问题。这种感知与推理的耦合性是当前 MLLM 进步的核心痛点。
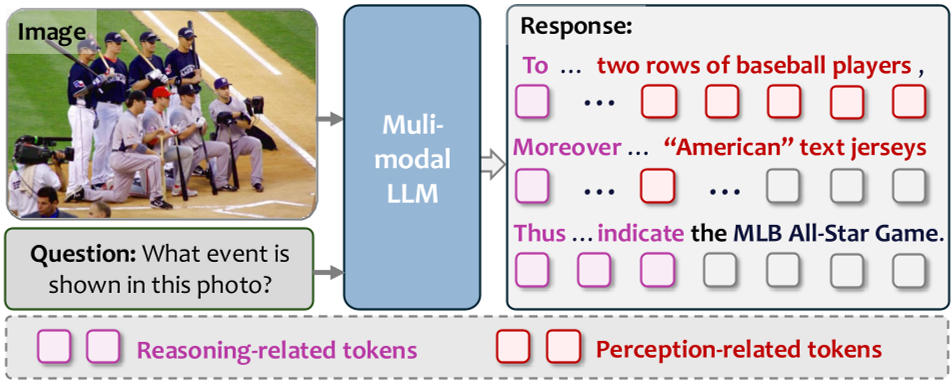 图 1:MLLM 的响应中,感知 Token(定位视觉内容)与推理 Token(构建逻辑链)是交织在一起的。
图 1:MLLM 的响应中,感知 Token(定位视觉内容)与推理 Token(构建逻辑链)是交织在一起的。
核心洞察:孤立优化的“失败实验”
作者进行了一项严谨的消融研究:
- Reasoning-only 优化:只针对高熵 Token(决策点)更新梯度。结果:模型逻辑变强,但视觉 Grounding 变弱,甚至无视图片内容。
- Perception-only 优化:只针对对视觉输入敏感的 Token 更新梯度。结果:模型能看清细节,但无法整合进连贯的推理中。
这证明了:感知是推理的基石,而推理是感知的导向,两者必须同时、有侧重地优化。
方法论:Token-Reweighting (ToR)
ToR 是一种即插即用的模块,其核心在于如何“挑出”那 30% 最重要的 Token。
1. 关键 Token 识别
- 推理相关 Token ():利用预测熵(Entropy)。高熵意味着模型在此处面临逻辑分支选择,属于推理的关键“分叉点”。
- 感知相关 Token ():计算图像输入前后的 Log-probability 差异。差异越大,说明该 Token 的生成越依赖于视觉特征。
2. 动态重权优化
在 GRPO 的目标函数中,ToR 为选定的关键 Token 分配不同的权重系数 和 ,对于非关键 Token 则减少或取消梯度贡献。
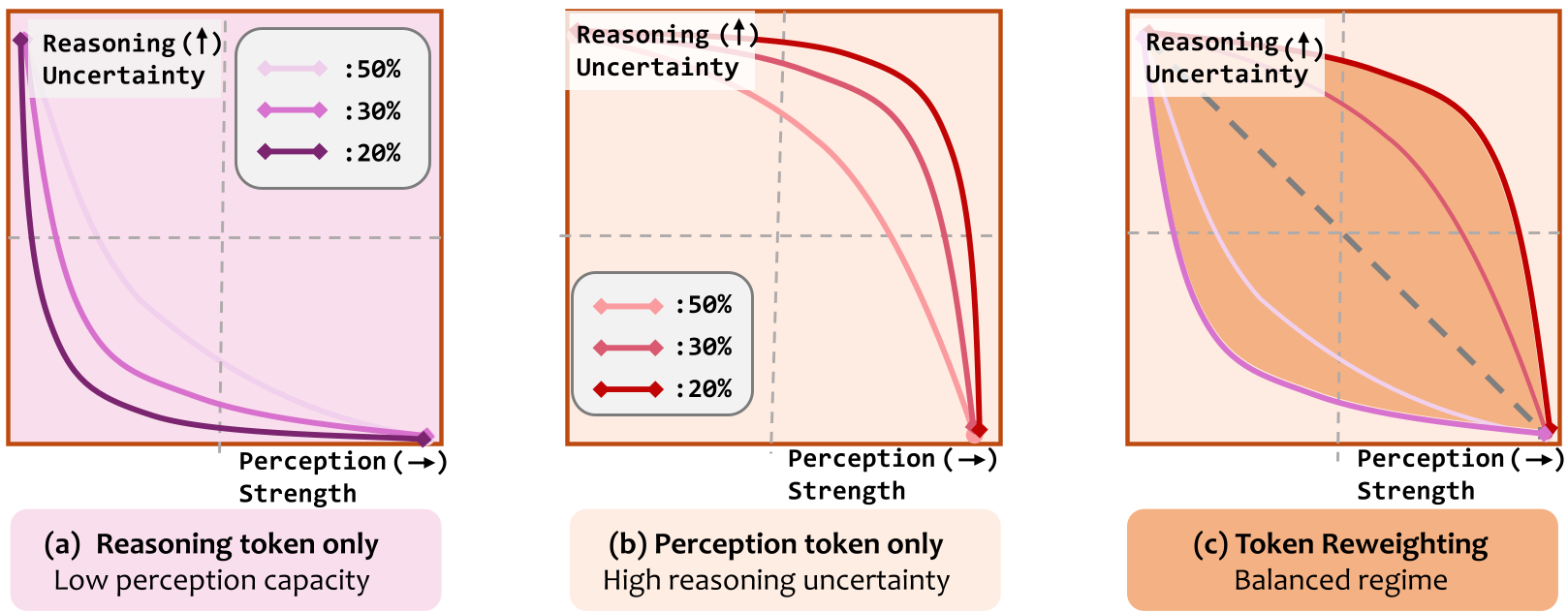 图 2:Vanilla GRPO(均匀分布) vs. 孤立优化 vs. ToR 联合优化(达到平衡点)。
图 2:Vanilla GRPO(均匀分布) vs. 孤立优化 vs. ToR 联合优化(达到平衡点)。
实验结果:全方位的 SOTA 提升
ToR 在多个基准测试中表现出色,尤其是在 Qwen2.5-VL-7B 背包上表现最佳:
- 理科能力跨越:在几何题目集 Geometry3K 上训练后,MathVerse 准确率从 50.8% 提升至 53.0%。
- 幻觉率降低:在 HalluBench 上,ToR 将感知准确度提升了 2.6 个百分点,有效缓解了看图说话中的“睁眼说瞎话”。
- 规模通用性:无论是 3B 还是 7B 模型,无论是小规模数据还是 39K 的 ViRL 数据集,ToR 带来的增益都非常稳健。
 表 1:ToR-DAPO 在各维度指标上全面超越基线及同类 RLVR 方法。
表 1:ToR-DAPO 在各维度指标上全面超越基线及同类 RLVR 方法。
深度洞察:为什么 Log-prob Difference 是最佳代理?
在附录中,作者比较了多种识别感知 Token 的指标(熵差、概率差等)。最终选定 Log-probability Difference,是因为它在“捕捉绝对视觉影响”与“信息论显著性”之间取得了最佳平衡。实验发现,感知稳定性与推理稳健性呈现出一种类似“物理推拉”的力学动态关系(见原文 Figure 9/10)。
总结与未来展望
ToR 的贡献在于,它证明了 MLLM 的优化不应只是简单的奖励工程(Reward Engineering),还需要对模型内部生成的“微观结构”(Token 分布)进行干预。
局限性:
- 目前识别 Token 仍基于代理指标,未来可结合 SAM 等视觉模型进行更细粒度的像素级关联。
- 尚未探索该策略在纯图像生成或多模态理解一体化任务中的潜力。
对于希望在多模态领域落地 RL 的开发者来说,ToR 提供了一个极低成本且收益显著的优化模板。
注:本文基于 arXiv 论文《Bridging Perception and Reasoning: Token Reweighting for RLVR in Multimodal LLMs》编写。