本文提出了 MoTok,一种基于 Diffusion 的离散动作分词器,并构建了“感知-规划-控制”三阶段运动生成框架。通过将细粒度重建任务从离散 Token 剥离并交给 Diffusion 解码器,该方法在保持高保真度的同时,实现了极高的动作压缩比,并在文本控制和轨迹控制任务上达到 SOTA。
TL;DR
南洋理工大学等机构的研究者提出了 MoTok,这是一个创新的“三阶段”动作生成框架(感知-规划-控制)。它通过将动作的“语义抽象”与“运动重建”解耦,允许模型用极少(仅为前人 1/6)的 Token 描述运动,同时借助 Diffusion 解码器实现了惊人的 0.08 cm 轨迹对齐精度。
背景:当“语义”遇上“运动学约束”
在人体动作生成(Motion Generation)领域,存在两座大山。一座是离散 Token 派,擅长像写文章一样生成动作,但在面对高频率的运动细节(如脚踝的微颤、精确的抓取路径)时,需要海量的 Token 才能还原,这给下游的 Transformer 带去了巨大的计算压力。另一座是连续 Diffusion 派,画质感人(动作自然),但难以直接插入复杂的逻辑约束。
更难的是,当你要求一个模型“一边跳舞一边手部经过这三个点”时,模型往往会为了凑这三个点,把舞跳得像断了线的木偶(自然度 FID 暴跌)。
核心直觉:上帝的归上帝,凯撒的归凯撒
MoTok 的作者提出了一项深刻的技术洞察:离散 Token 应该只负责“讲故事”(语义结构),而“怎么画得真实”(运动物理细节)应该交给 Diffusion。
1. MoTok 分词器:极简 Token,无限细节
与其让 VQ-VAE 去死磕每一个像素级别的位移,MoTok 训练了一个由单层 Codebook 组成的 Encoder。它产生的 Token 序列非常短,但这串 Token 并不直接变成动作,而是变成了 Diffusion 解码器的“向导信号”。
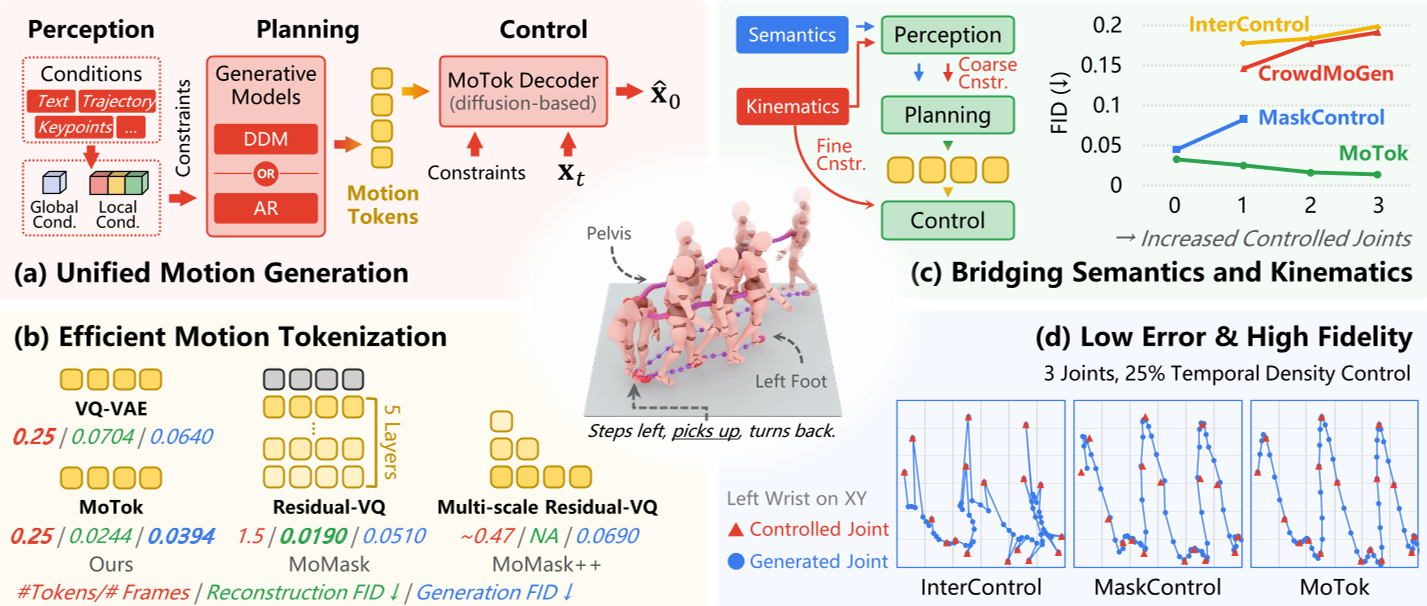 图 (a) 展示了从感知到控制的全流程;图 (b) 彰显了 MoTok 极具竞争力的压缩效率。
图 (a) 展示了从感知到控制的全流程;图 (b) 彰显了 MoTok 极具竞争力的压缩效率。
2. 三阶段生成的艺术
- Perception (感知):将文本(全局)和轨迹(局部运动学)分开编码。
- Planning (规划):在离散空间预测 Token。此时,轨迹只是一个“大概方向”的引导。
- Control (控制):这是 MoTok 的撒手锏。在 Diffusion 解码的去噪过程中,通过反向传播梯度引导(Guidance),强制让生成的关节坐标紧贴目标轨迹。
实验结果:越被约束,越发优美
这是一个非常反直觉的结果。在常规模型中,引入轨迹约束会破坏生成分布,导致 FID(衡量动作质量)变差;但在 MoTok 中,约束越多,FID 反而越好(从单点约束的 0.025 优化至三点约束的 0.014)。
 表 1 显示,MoTok 在轨迹误差(Avg. Err)和动作真实度(FID)上实现了对 MaskControl 等基线的全方位碾压。
表 1 显示,MoTok 在轨迹误差(Avg. Err)和动作真实度(FID)上实现了对 MaskControl 等基线的全方位碾压。
深度洞察:为什么这种解耦是未来的必然?
传统的 VQ-VAE Token 承载了太多负担:它既要代表“在跑步”,又要代表“脚抬高了 15.2 厘米”。这种信息纠缠让模型在推理时极易顾此失彼。
MoTok 的成功在于它建立了一个条件分层机制:
- 离散 Token 层:捕捉低频的、鲁棒的语义结构。
- Diffusion 细化层:捕捉高频的、易碎的运动细节。
通过消融实验可以发现,如果只在 Planning 阶段加约束,轨迹对不准;如果只在 Control 阶段加约束,动作会变得诡异。只有两手都要抓,才能实现“形神兼备”。
总结与局限
MoTok 为长上下文的动作建模开辟了道路——由于它极高的压缩率,未来的 Generator 可以处理更长时间跨度的动作序列。
局限性:尽管精度惊人,但 Diffusion 解码器的推理速度(2.63s/seq)相对于纯 AR 模型(毫秒级)仍显沉重。虽然作者使用了 Fast27 采样器进行加速,但在需要超低延迟的实时动作反馈(如 VR 交互)中,仍有优化空间。
关键词:Motion Tokenization, Diffusion Models, HumanML3D, 轨迹控制, 具身智能。