REA-Coder: Why Reasoning Isn't Enough for Code Generation
REA-Coder is a novel requirement alignment framework designed to enhance code generation by ensuring LLMs correctly understand user intent before and during the coding process. By implementing a dual-phase alignment strategy—upfront question-answering and post-generation masked-recovery verification—it achieves SOTA performance across benchmarks like APPS and CodeContests, outperforming existing reasoning-based and post-processing methods.
TL;DR
Even the most powerful LLMs like GPT-5-mini or DeepSeek-v3.2 often fail at coding not because they can't write code, but because they misunderstand what to write. REA-Coder bridges this gap by introducing a rigorous "Requirement Alignment" process that verifies model comprehension through question-checklists and masked-text recovery, boosting performance by up to 344% on challenging benchmarks.
The "Understanding" Fallacy in Code Generation
Most current research in AI-driven coding focuses on two things: Reasoning (Chain-of-Thought) and Post-Processing (Self-Repair via compiler feedback). However, these methods share a fatal blind spot: they assume the model's initial "mental model" of the requirements is correct.
If an LLM misinterprets a "centrally symmetric" constraint as a simple "mirror reflection," no amount of sub-task decomposition or error-log patching will fix the code. The foundation is cracked. REA-Coder argues that we must move the alignment of intent as early as possible in the pipeline.
Methodology: The REA-Coder Architecture
The core of REA-Coder is a feedback loop that treats requirement understanding as a testable hypothesis.
Phase 1: Pre-Generation Alignment (QA-Checklist)
Before a single line of code is written, REA-Coder forces the LLM to generate a question-answer checklist based on 13 specific "Requirement Dimensions" (e.g., Global Constraints, Edge Cases, Invariants).
- If the LLM's answers to these questions deviate from the requirement's "ground truth," the model's prompt is updated to explicitly disambiguate these points.
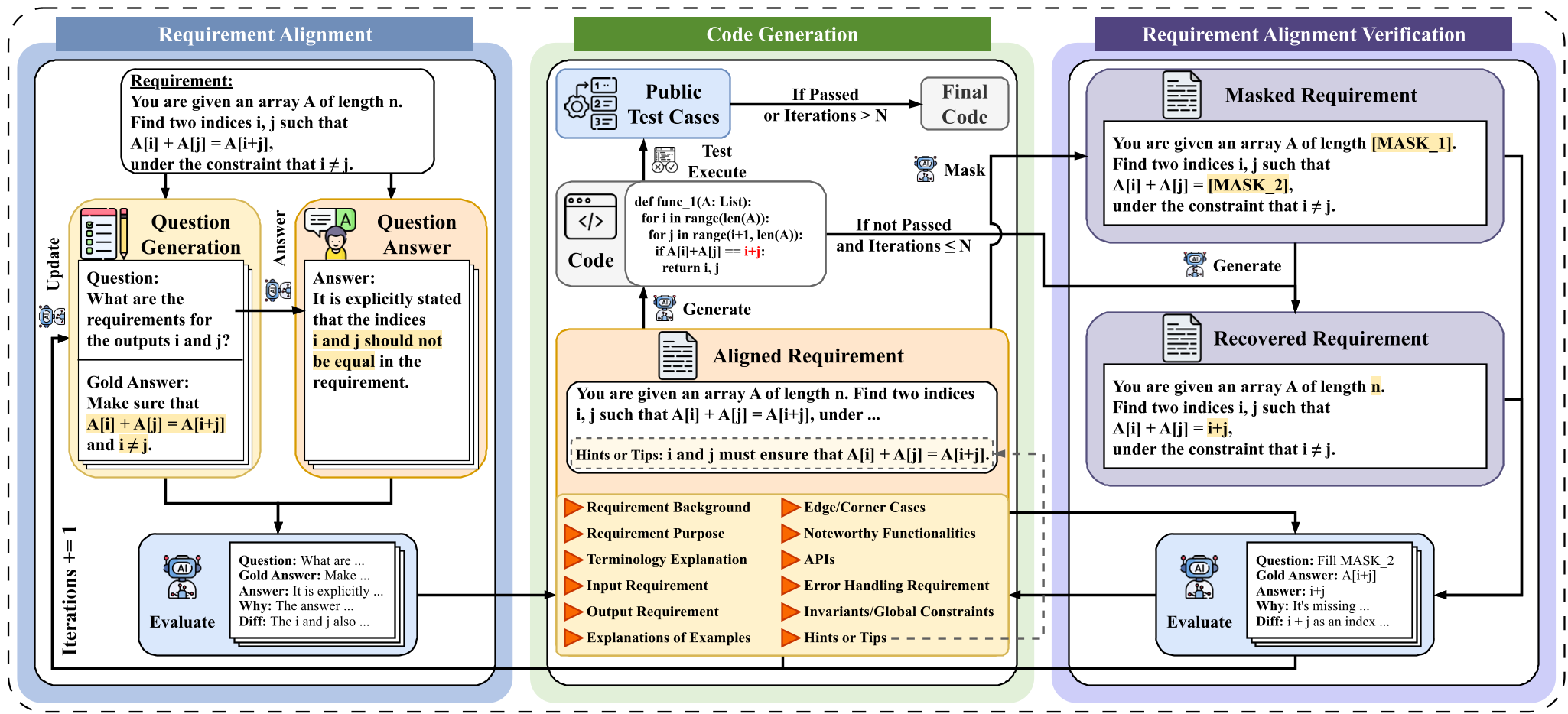
Phase 2: Post-Generation Verification (The Masking Trick)
To ensure the LLM didn't just "get lucky" or ignore constraints, REA-Coder uses a unique verification method:
- It masks key phrases in the original requirement.
- It asks the LLM to recover the missing text using only the code it just generated.
- If the model can't recover the requirement logic, it proves the code is not semantically aligned with the user's intent.
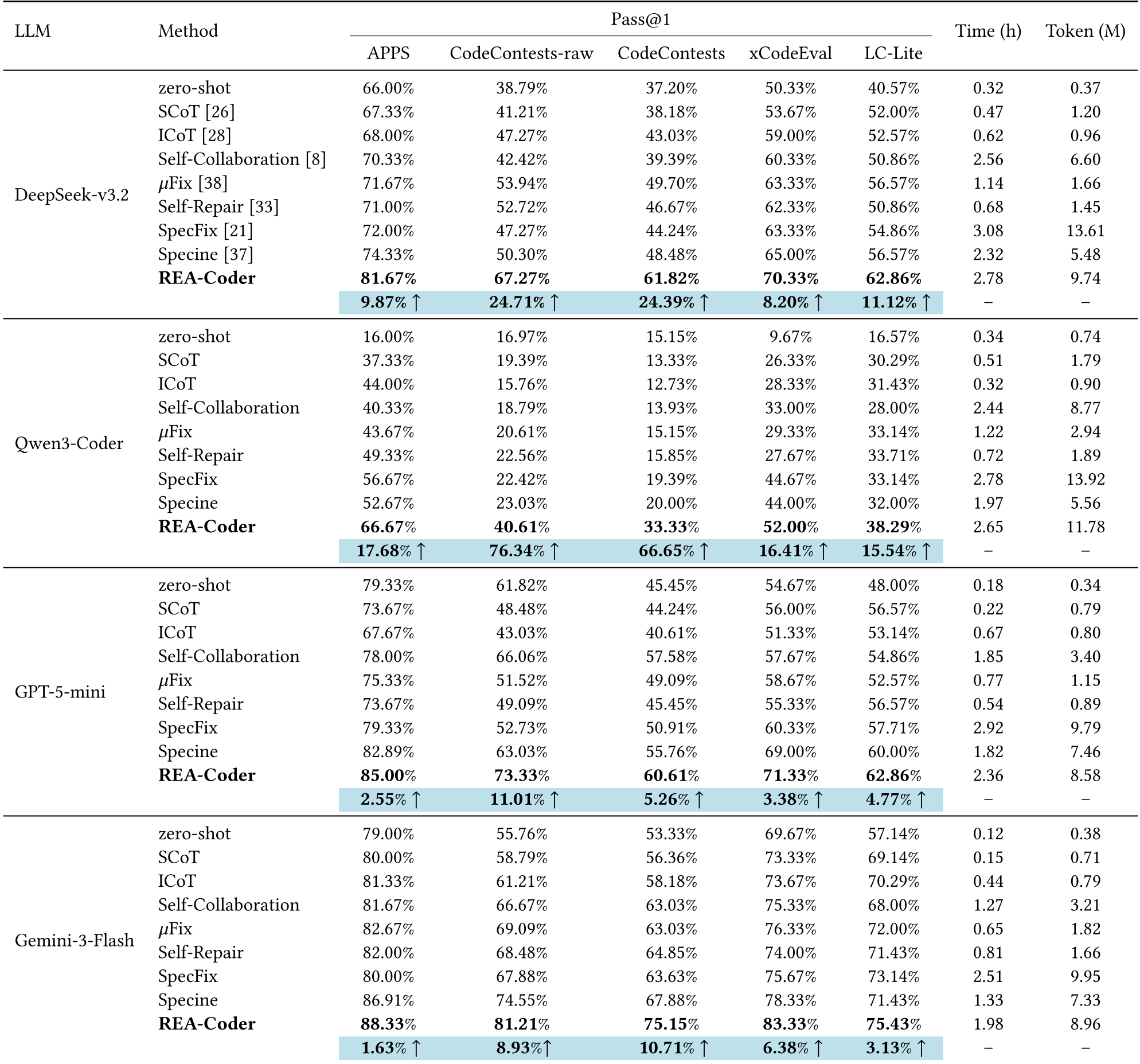
Experiments: Breaking the SOTA
The researchers tested REA-Coder against 8 baselines across five major benchmarks (APPS, CodeContests, xCodeEval, etc.).
Key Results:
- Massive Gains on Weaker Models: On Qwen3-Coder, the Pass@1 score jumped from 9.67% (zero-shot) to over 52% on xCodeEval.
- Competitive SOTA: On CodeContests—a benchmark designed for competition-level programming—REA-Coder improved SOTA results by an average of 26-30%.
- Efficiency: While it uses more tokens than a simple zero-shot prompt, its cost is comparable to other iterative methods while delivering significantly higher accuracy.
Deep Insight: Which Dimensions Matter?
The study included an ablation on 13 requirement dimensions. The findings were revealing:
- Requirement Purpose and Explanations of Examples are the two most critical factors. Removing the "Purpose" dimension dropped performance by over 12%.
- This suggests that LLMs rely heavily on the "Why" and the concrete "Input-Output transformation logic" more than on isolated API definitions or technical constraints.
Conclusion & Future Outlook
REA-Coder proves that Requirement Engineering is just as important for AI as it is for human developers. By shifting the focus from "how to code" to "what to code," we can unlock the potential of smaller or mid-sized models to solve competitive programming tasks that were previously the domain of top-tier models.
Takeaway: In the future of LLM-based development, the prompt isn't just a instruction; it's a dynamic contract that must be negotiated and verified.
Limitations
- Iteration Cost: The 10-iteration budget provides great performance but increases latency and API costs.
- Dependency on Prompt Quality: The system relies on the LLM's ability to generate its own question checklists, which could potentially be a bottleneck for very low-end models.