Calibri is a parameter-efficient calibration method for Diffusion Transformers (DiTs) that enhances image generation quality by optimizing approximately 100 scaling parameters. Using the CMA-ES evolutionary strategy, it re-weights the outputs of DiT blocks to maximize human preference rewards, achieving SOTA performance on models like FLUX.1 and SD-3.5M.
TL;DR
Generative models are shifting from U-Nets to Diffusion Transformers (DiTs), but they treat every layer as equally important—which is a mistake. Calibri proves that by simply scaling the output of DiT blocks with roughly 100 learned parameters, we can significantly boost image quality and cut inference time in half. It uses a gradient-free evolutionary strategy to "calibrate" the model, outperforming heavy RLHF-style methods with a fraction of the cost.
Problem & Motivation: Not All Layers Are Created Equal
Modern DiTs like FLUX and Stable Diffusion 3.5 consist of many identical blocks. However, the authors discovered two startling facts through ablation studies:
- Redundancy: Selectively disabling certain blocks via residual bypass can actually improve generation quality.
- Sub-optimal Weighting: Multiplying a block's output by a single scalar (e.g., 0.75 or 1.25) consistently yields better results than the default model.
This suggests that the "Standard DiT" architecture is sub-optimally weighted. Existing alignment methods (like DPO or GRPO) try to fix this by updating millions of parameters via expensive gradient descent. Calibri asks: Can we achieve the same alignment by just tuning the "volume knobs" of each layer?
Methodology: Black-Box Calibration
The core idea of Calibri is to insert a scaling coefficient $s$ into the DiT output formula: $$x_{l+1} = x_l + s \cdot ( ext{Block Output})$$
The authors explore three levels of granularity for these coefficients:
- Block Scaling: One $s$ per whole transformer block.
- Layer Scaling: Distinct $s$ for Attention and MLP layers.
- Gate Scaling: Specific $s$ for visual vs. textual gates (crucial for MM-DiT).
The Calibration Loop
Since reward models (HPSv3, PickScore) are often non-differentiable or "noisy" for standard optimizers, Calibri uses CMA-ES (Covariance Matrix Adaptation Evolution Strategy). It samples different sets of scaling parameters, generates images, evaluates them using a reward model, and evolves the parameters toward the highest scores.
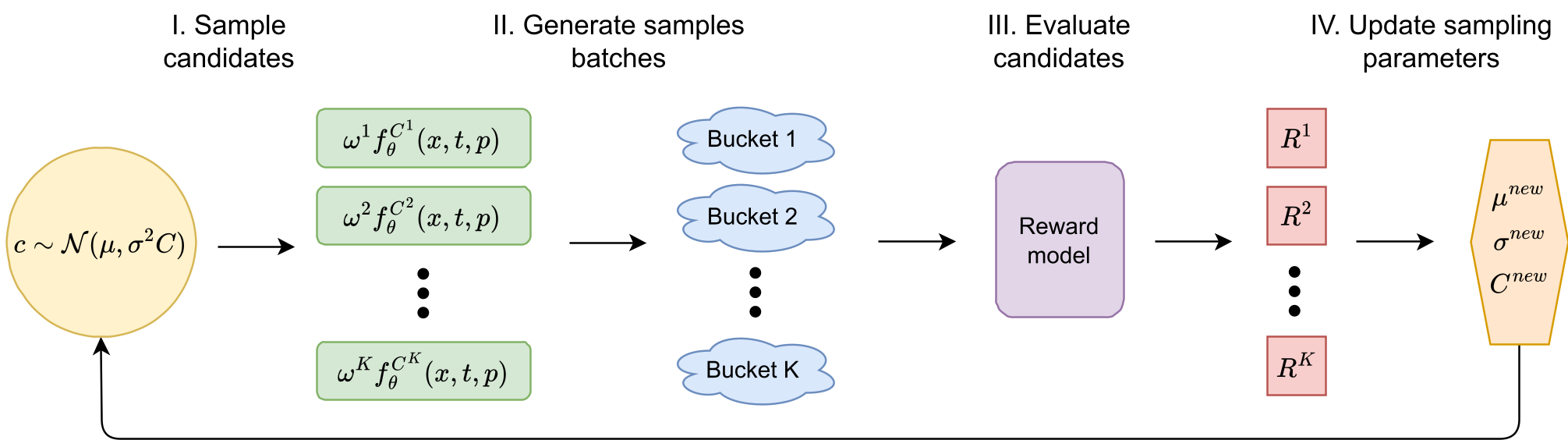 Figure 1: The Calibri calibration loop using CMA-ES to optimize scaling coefficients.
Figure 1: The Calibri calibration loop using CMA-ES to optimize scaling coefficients.
Experiments: Higher Quality, Faster Speed
Calibri was tested on FLUX.1-dev, SD-3.5M, and Qwen-Image. The results show a "double win":
- Metric Boost: Significant jumps in HPSv3 (Human Preference Score) and Q-Align.
- Efficiency: Calibri naturally shifts the model's peak performance to earlier sampling steps. For instance, FLUX reaches better quality at 15 steps than the baseline does at 30.
 Table 1: Quantitative gains across different backbones showing improved metrics at lower NFE (Number of Function Evaluations).
Table 1: Quantitative gains across different backbones showing improved metrics at lower NFE (Number of Function Evaluations).
Calibri vs. Flow-GRPO (RL)
In a head-to-head against Flow-GRPO (a state-of-the-art RL alignment method), Calibri updated only 216 parameters compared to GRPO's 18.78 million. Despite this 87,000x difference in parameter count, Calibri achieved comparable or superior PickScore alignment.
Deep Insight: The Power of Ensembling
Calibri also introduces Calibri Ensemble, which combines multiple calibrated versions of the same model. This generalizes techniques like "Skip Layer Guidance," allowing for custom "guidance" logic that boosts performance across all inference steps, as shown in the authors' analysis of sampling step curves.
Critical Analysis & Conclusion
Takeaway: Calibri proves that the architectural "balance" of DiT models is just as important as the weights themselves. By focusing on parameter-efficient calibration, we can align models to human preferences with minimal GPU hours (~32 hours for FLUX) and gain a permanent inference speed-up.
Limitations: The method is heavily dependent on the quality of the Reward Model used. If the reward model is blind to anatomical artifacts (like "six-fingered hands"), Calibri might "reward hack" and stabilize those artifacts.
Future Work: This technique could likely be extended beyond image generation to Video DiTs, where the computational cost of full fine-tuning is even more prohibitive.
Senior Editor's Note: Calibri represents a pragmatic shift in AI research—moving away from "brute-force fine-tuning" toward "intelligent architectural refinement."