The paper introduces a novel framework for precise camera control in text-to-image (T2I) generation by learning parametric "viewpoint tokens." By integrating a lightweight MLP encoder with backbones like Harmon and Stable Diffusion, the method achieves state-of-the-art accuracy in 5-DOF camera manipulation (azimuth, elevation, radius, pitch, yaw) without requiring auxiliary geometric inputs like depth maps.
TL;DR
While AI can generate a "cat in a hat" with ease, telling it to "render a cat from a 45-degree top-down perspective" often results in geometric hallucinations. This paper introduces parametric Viewpoint Tokens, a method that embeds explicit 3D camera coordinates directly into the text prompt space. By training on a clever mix of "perfect" 3D renders and "realistic" AI-edited scenes, the authors achieve SOTA camera precision across 5 degrees of freedom while keeping the images looking photorealistic and semantically accurate.
The "Canonical" Struggle: Why "Left" Isn't Always Left
Current generative models suffer from a "canonical bias." If you ask for a car, you usually get a side or front view because that's what the training data favors. More importantly, large models lack a consistent coordinate system. They don't have a shared definition of "front" or "back" that applies across different objects like a "Santa Claus" and a "Fighter Jet."
Prior attempts to solve this, such as Compass Control, were often limited to simple horizontal rotation (azimuth) and suffered from a massive "overfitting" problem. For example, if Compass Control only saw lions from the back during training, asking it for a "Santa Claus from the back" might accidentally generate a shoe or a lion-shaped Santa.
The Architecture: Learning the Language of XYZ
The core of this method is the transformation of raw camera parameters—$ heta = ( heta_{az}, heta_{el}, r, heta_{pitch}, heta_{yaw})$—into a high-dimensional embedding that the model's transformer blocks can understand.
1. Factorized Parameterization
Instead of using complex 12D camera matrices which are hard for LLMs to digest, the authors use a factorized representation. They fix the object at the origin and move the camera around it. The azimuth is encoded using $sin$ and $cos$ to handle the periodic nature of rotation (0° is the same as 360°), preventing the model from getting confused at the "seam."
2. The Viewpoint MLP
A lightweight 3-layer MLP acts as a translator. It takes these geometric signals and produces a Viewpoint Token. This token is inserted right next to the object's description in the text prompt:
"A photo of a [Object] [Viewpoint Token] in a [Background]"
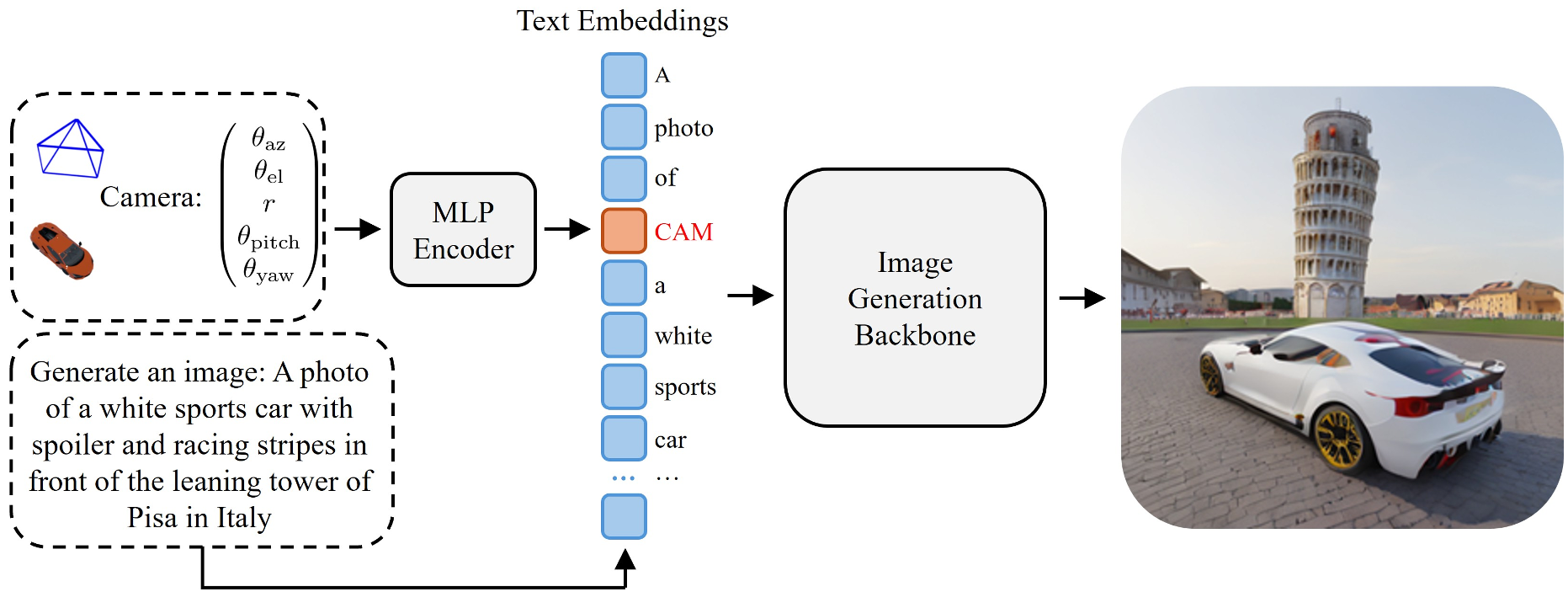 Figure 1: The model architecture showing how camera parameters are injected into the text pipeline.
Figure 1: The model architecture showing how camera parameters are injected into the text pipeline.
The Secret Sauce: Two-Part Data Strategy
You can't learn 3D geometry from 2D internet photos alone (they lack labels), but you also can't train only on 3D renders (they look like plastic). The authors solve this with a hybrid dataset:
- The Geometric Backbone: 373,000 images of 3D objects with perfect 5-DOF labels.
- The Realism Anchor: 6,600 "photorealistic augmented" images. They took 3D renders and used Gemini 2.5 Flash to "inpaint" real backgrounds and textures while keeping the object's pose identical to the 3D ground truth.
Experimental Showdown: Global Understanding
Unlike previous methods that "masked" the model's attention to look only at the object, this method allows the viewpoint token to interact with the entire scene. This results in Global Scene Understanding—the background and the object perspective actually match.
In quantitative tests, this model crushed the competition:
- Azimuth Accuracy: Improved by ~40% compared to Compass Control.
- Generalization: When asked to generate a "Gundam" (which wasn't in the training set), the model successfully applied the camera control, whereas older models reverted to "biased" front views or generated gibberish.
 Figure 2: Comparing ControlNet (requires depth maps) vs. the proposed method (just text + token).
Figure 2: Comparing ControlNet (requires depth maps) vs. the proposed method (just text + token).
Critical Insight: The "Eye-Level" Bias
Even with this sophisticated control, the paper identifies a fascinating limitation: Model Bias. If you try to generate a "Taj Mahal" from a high-angle view, the model's strong internal prior (from seeing millions of eye-level Taj Mahal photos) fights against the viewpoint token. The model wants to put the horizon in the center because that's "correct" in its world-view.
Conclusion
This work marks a shift from "guessing" geometry to "specifying" it. By treating the camera as a learnable part of the vocabulary, we close the gap between professional 3D rendering engines and intuitive text-to-image AI. It’s no longer just about what you want to see, but where you are standing when you see it.