本文提出了一个将动态重定向(Dynamic Retargeting)与控制指导强化学习(CLF-RL)相结合的框架,旨在实现人形机器人高性能且可控的奔跑。通过在 Unitree G1 机器人上部署,成功实现了高达 3.3 m/s 的奔跑速度,并集成了感知规划栈以完成室外自主避障。
TL;DR
加州理工学院 Ames 实验室的研究团队推出了一套全新的管线,让 Unitree G1 人形机器人在室外跑出了 3.3 m/s 的 SOTA 速度。其核心在于:不再盲目模仿人类动作,而是通过动力学优化修正人类数据,并利用控制 Lyapunov 函数 (CLF) 引导强化学习,解决了高动态运动中“跑得快”与“控得住”之间的长期矛盾。
背景:为什么人形机器人跑不好?
在人形机器人领域,实现动态奔跑通常面临两个极端:
- 模型驱动方法:虽然理论严谨,但在处理复杂的全身动力学和接触力时计算极其沉重,鲁棒性难以保证。
- 模仿学习 (Mimic RL):通过模仿人类动作剪辑(如 DeepMimic),机器人可以做出酷炫的动作,但往往只是“录像带回放”。一旦给它一个特定的速度指令,它往往因为参考轨迹不符合物理规律或奖励函数设计不当而导致跟踪失败,无法胜任实际的自主导航任务。
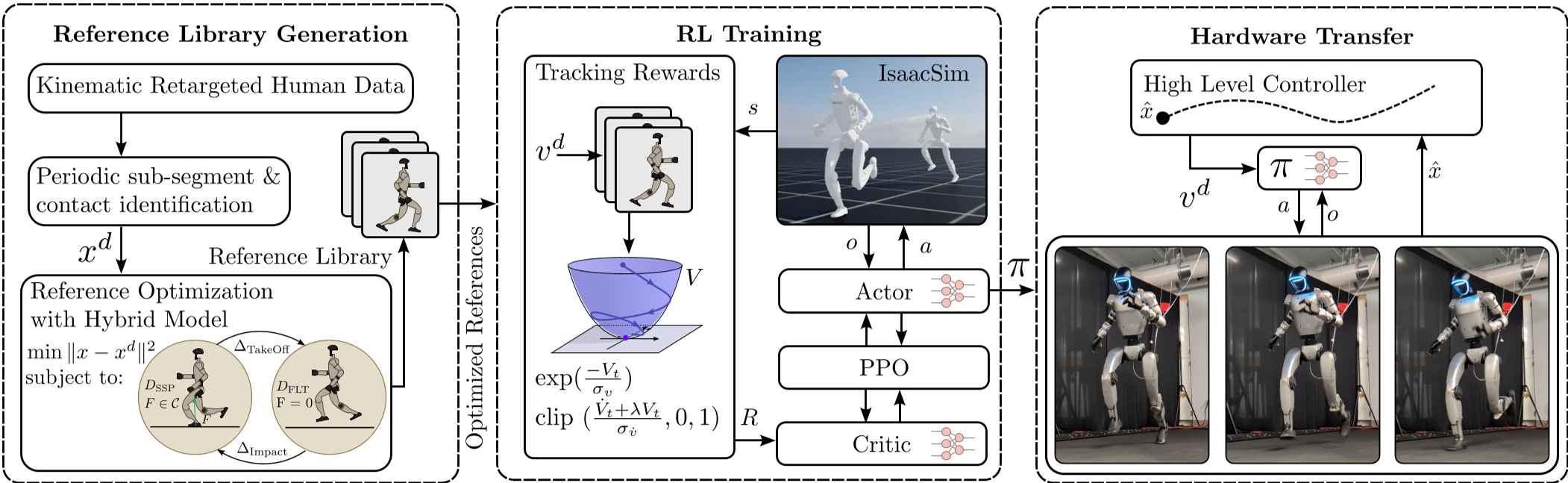
核心创新点详解
1. 动态重定向:给人类动作打个“物理补丁”
人类和机器人的质量分布、关节限位截然不同。作者没有直接将人类数据塞给 RL,而是构建了一个多段打靶动态优化 (Multiple Shooting Optimization) 方案:
- 硬约束引入:强制要求步态具有周期性(Periodicity),并符合混合动力学系统(Hybrid Systems)模型。
- 库生成:从一段单一的人类跑步素材出发,通过改变步长约束,自动“衍生”出一系列从 1.2 m/s 到 3.6 m/s 的运动轨迹库。 这确保了交给 RL 学习的“教材”本身就是物理可行的。
2. CLF-RL:用控制理论规范强化学习
传统的模仿奖励(Mimic Reward)通常只是简单的欧氏距离惩罚。本文引入了 CLF-RL,将控制理论中的衰减条件写入奖励函数:
- Lyapunov 奖励:定义 ,引导误差指数级收敛。
- 稳定性导向:相比于盲目的距离惩罚,CLF 奖励能更好地权衡不同状态维度(如位置 vs 速度)的耦合关系,使收敛过程更符合控制直觉。
3. 分层自治架构
为了证明该控制器的实用性,作者将其嵌入了一个三层架构:
- 感知层:FastLio 提供里程计,Lidar 生成占据栅格地图。
- 规划层:MPC + CBF(控制屏障函数)在 10Hz 指令频率下生成安全的避障速度。
- 控制层:本文的 RL 策略在 50Hz 下将速度指令转化为关节动作。
实验战绩与消融分析
模拟器表现
在上百个随机环境的测试中,作者发现:
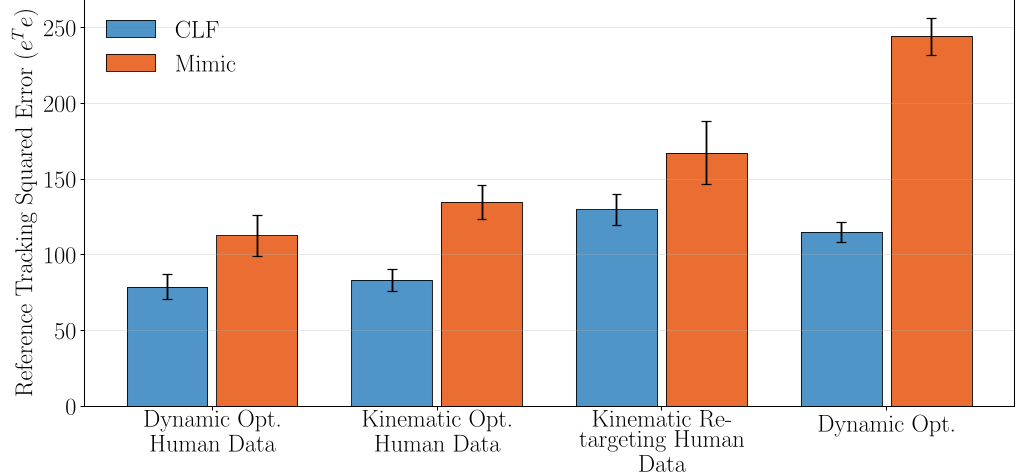
- Trajectory Quality Matters: 经过动态优化的轨迹比仅经过运动学重定向的轨迹,跟踪误差降低了约 30%-50%。
- CLF vs Mimic: CLF 奖励在所有参考轨迹类型下均优于传统的 Mimic 奖励,证明了控制直觉的有效性。
硬件部署
在 Unitree G1 上,该控制器展现了极强的通用性:
- 极速跑步:在跑步机上达到 3.3 m/s,肉眼可见明显的双脚腾空阶段。
- 长途奔袭:在室外人行道无修正运行超过 250 米。
- 动态避障:在 2 m/s 的高速移动中,机器人能丝滑地绕过突然出现的障碍物,展现了极高的可控性。
总结与洞察
这篇论文标志着人形机器人运动控制从“动作展示”向“实用工具”的跨越。其核心启示是:强化学习并不排斥经典控制理论,反而需要控制理论来划定边界。
缺陷与改进方向: 目前该方法主要针对平坦路面,虽然具有一定的域随机化抗扰能力,但在面对极度崎岖的地形或需要大幅度重心调整的工况下,可能仍需进一步结合全身控制(WBC)的实时反馈。此外,目前从步行到跑步的切换主要依靠不同策略的硬切换,未来的研究方向可以集中在通过单一统一策略实现全速域的平滑过渡。