Chronos is a temporal-aware conversational memory framework specifically designed for long-term LLM interactions. It introduces a dual-indexing strategy—an Event Calendar (structured subject-verb-object tuples with ISO 8601 datetime ranges) and a Turn Calendar (raw dialogue)—achieving a new SOTA accuracy of 95.60% on the LongMemEvalS benchmark.
TL;DR
As LLMs engage in months-long interactions, remembering what happened is easy, but remembering when it happened relative to other events is notoriously difficult. Chronos is a novel memory framework that treats time as a first-class citizen. By indexing conversations into a structured Event Calendar with resolved datetime ranges alongside raw turns, it achieves a record-breaking 95.60% accuracy on the LongMemEvalS benchmark, outperforming existing systems by over 7.6%.
The "Context Entropy" Trap: Why Current Memory Fails
Most conversational agents today follow one of two flawed paths for long-term memory:
- Pure Vector Search (Turn-level): They store dialogue chunks. When you ask, "How many times did I exercise last March?", the retriever finds turns about "exercise" but struggles to filter them by a strict calendar range, often returning irrelevant sessions from June or July.
- Over-Structured Knowledge Graphs: They extract every possible fact into a complex graph. This leads to Context Entropy—the agent gets overwhelmed by thousands of irrelevant facts (e.g., "The user likes blue") when it only needs to know about a specific medical prescription change.
Chronos finds the "Minimum Sufficient Abstraction" by only structuring temporally-grounded events while keeping the rest as natural dialogue.
Methodology: The Chronos Architecture
Chronos operates on a dual-track system, visualized in the architecture below:
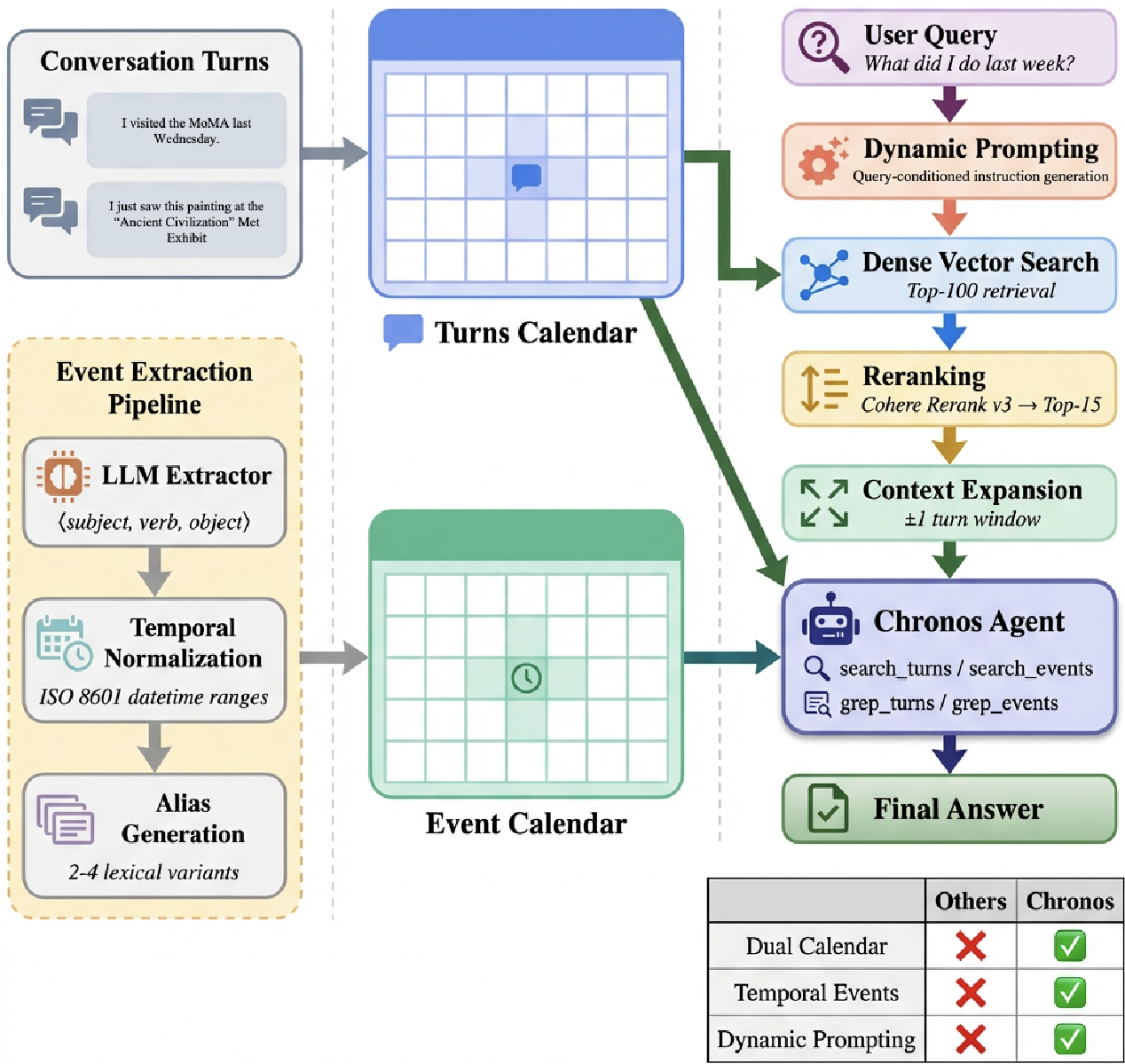
1. Event Extraction & Multi-Resolution Normalization
Instead of just saving text, Chronos extracts ⟨subject, verb, object⟩ tuples. Crucially, it resolves fuzzy terms like "recently" or "last week" into precise ISO 8601 datetime ranges. If a user says "I started my diet two days ago" on March 22nd, Chronos stores the start date as March 20th.
2. Dynamic Prompting (Retrieval Guidance)
Unlike standard RAG that just rewrites the query, Chronos uses a "Meta-Prompt" to generate a strategy preamble. It tells the agent: "Focus on finding exercise events between March 1st and March 31st; use the Event Calendar for counts and the Turn Calendar for specific details."
3. The Iterative ReAct Loop
The Chronos Agent doesn't just search once. It uses a Tool-Calling loop (Vector search + Grep) to cross-reference the two calendars. If vector search is too "fuzzy," the agent can use grep to find exact keyword matches (like specific medication names or model numbers).
Experimental Results: Setting a New SOTA
The researchers evaluated Chronos against industry leaders like Zep and Honcho.
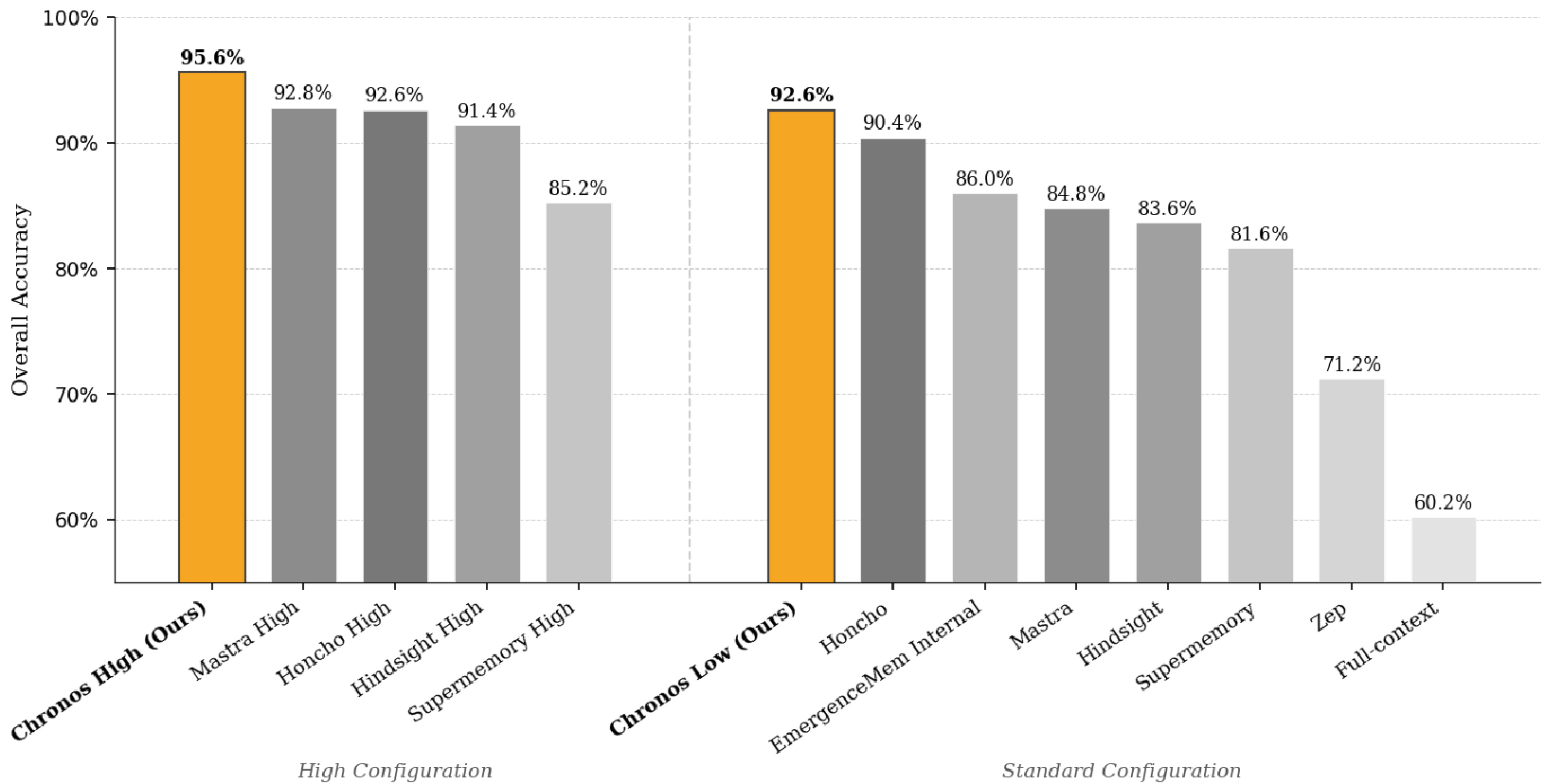
- Performance Jump: Chronos Low (using GPT-4o) achieved 92.6%, already surpassing the best prior systems.
- Scaling with Capability: Chronos High (using Claude Opus 4.6) pushed the ceiling to 95.6%.
- Category Dominance: The system showed massive gains in Knowledge-Update Tracking (KU) and Multi-Session Aggregation (MS)—the two areas where previous models typically fail because they can't distinguish between "Current Work" and "Past Work."
What is the most important part? (Ablation Study)
The researchers found that for smaller models (Chronos Low), removing the Events Index caused accuracy to plummet from 93.1% to 58.6%. This proves that structured temporal metadata is a massive "force multiplier" for LLM reasoning.
Critical Analysis: Limitations & Future
While Chronos is powerful, it faces typical "Agentic" hurdles:
- Inference Latency: The iterative ReAct loop and dual-index lookups mean it is slower and more expensive than "single-shot" RAG.
- Storage Overhead: Maintaining two separate indexes (Events and Turns) increases the database footprint.
The Takeaway for Developers: If you are building an AI companion or a professional agent (Legal, Medical) that needs to track habits or changes over time, stop relying on semantic similarity alone. You need a "Structured Event Calendar" that converts conversational time into executable datetime filters.
Conclusion
Chronos demonstrates that we don't need a "perfect" human-like memory graph to achieve intelligence. By simply organizing "What happened" onto a "When it happened" timeline, we can build agents that truly understand the flow of human life across months of interaction.