本文提出了 Chronos,这是一个具备时间感知能力的对话记忆框架。它通过将对话原始文本分解为带有时戳范围的 SVO 事件元组并构建“事件日历”,结合“轮次日历”实现双重索引。在 LongMemEvalS 基准测试中,Chronos High 达到了 95.60% 的准确率,刷新了长对话记忆任务的 SOTA 纪录。
TL;DR
传统的 AI 对话助手往往面临“健忘”或“时间错乱”的问题。Chronos 框架通过引入双日历架构(事件日历 + 轮次日历),将非结构化的对话重构为带有精确 ISO 8601 时间范围的 SVO 事件流。该方法在 LongMemEvalS 基准上以 95.60% 的准确率夺冠,将多会话逻辑推理与知识更新追踪的性能推向了新高度。
1. 痛点:为什么 AI 记不住“上周五”发生的事?
在长达数月的对话交互中,现有的 Memory 方案存在严重的“二元对立”:
- 全量知识图谱(KG-based):试图提取所有事实,但这会导致数据库极度臃肿,且检索时引入大量无关的噪声(Context Entropy)。
- 纯文本检索(Turn-level Retrieval):虽然保留了语义细节,但对“计算我五月份锻炼了多少次”这种涉及时间聚合(Aggregation)的问题表现乏力,因为向量模型无法理解“上个月”与“2024-05”的物理对等关系。
Chronos 的作者认为,**时间感知(Temporal Awareness)**不应该只是一个元数据标签,而应该成为检索的一等公民。
2. 核心架构:双日历协同(Dual Calendars)
Chronos 的核心设计思想是选择性结构化(Selective Structuring)。它不追求解析所有的语义,只针对“时间”这一维度进行硬核加固。
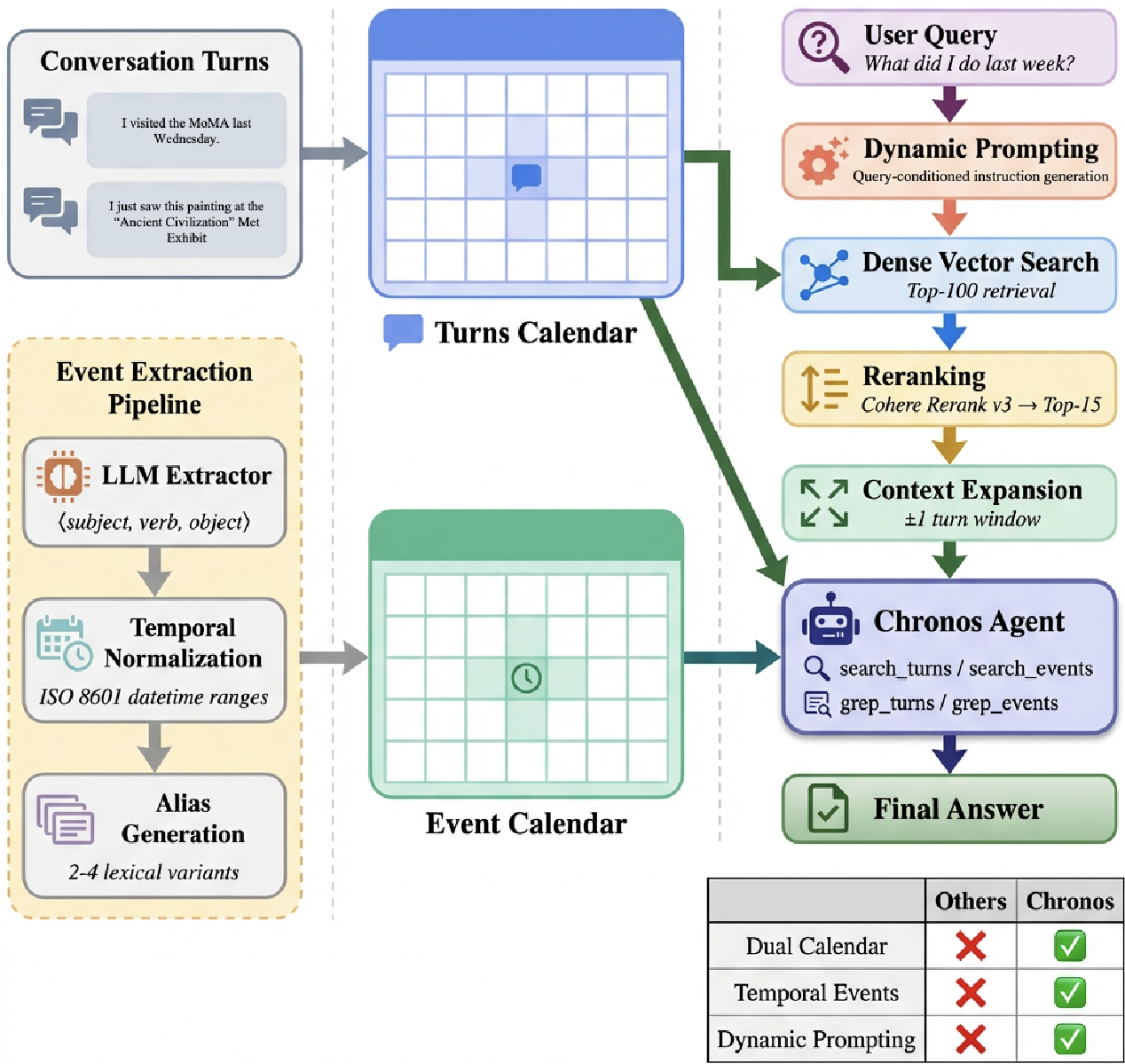 图 1:Chronos 架构总览,包括事件提取、双索引构建及动态查询处理流程。
图 1:Chronos 架构总览,包括事件提取、双索引构建及动态查询处理流程。
2.1 事件提取管道 (Event Extraction)
系统将对话切片,利用 LLM 提取出 ⟨Subject, Verb, Object⟩ 三元组。最关键的一步是多分辨率时间归一化。例如,如果用户在 3 月 22 日说“我上周买了这台相机”,系统不仅记录文本,还会计算出具体的日期区间 [2026-03-15, 2026-03-21]。
2.2 动态提问 (Dynamic Prompting)
不同于普通的查询重写,Chronos 为每一条提问生成一份“检索行动指南”。
- Query: “我最近买了什么镜头?”
- Guidance: “重点关注相机镜头购买事件,按时间倒序排列,识别最新的型号。” 这种元指令引导 Agent 在后续的 Tool-calling 阶段展现出极强的针对性。
3. 实验结果:统治级的长程记忆表现
Chronos 在涵盖 500 个复杂问题的 LongMemEvalS 上进行了全方位的 Benchmarking。
3.1 性能对比
Chronos 展示了卓越的跨模型兼容性。即使是基于 GPT-4o 的 Chronos Low 版本,其准确率(92.60%)也轻松击败了利用更高级模型构建的其他系统。
 表 1:Chronos Low 与主流系统(Honcho, Zep, Mastra)的准确率对比。
表 1:Chronos Low 与主流系统(Honcho, Zep, Mastra)的准确率对比。
3.2 深度消融分析
哪个组件最关键?实验给出了惊人的结论:
- 去失事件日历:准确率骤降近一半(-34.5%)。这证明了结构化事件对长程记忆的决定性作用。
- 去重排序(Rerank)与动态提示:分别带来了 15%-20% 的稳健增长。
4. 技术洞察:从“召回”转向“推理”
Chronos 成功的本质在于它将记忆检索从一个简单的“相似度匹配问题”转变为一个**“基于工具的闭环推理过程”**。
- ReAct 循环:Agent 利用
search_events(向量)和grep_turns(关键词)反复横跳,直到找到交叉验证的事实。 - 抗干扰能力:通过“事件别名(Lexical Aliases)”生成(例如将“Fitbit”关联到“运动追踪器”),极大地增强了语义搜索的鲁棒性。
局限性
尽管性能强悍,Chronos 增加了 indexing 阶段的计算成本(需要批处理提取事件),且双索引设计对存储空间有更高的要求。
5. 总结与展望
Chronos 的出现标志着智能体记忆从“线性堆叠”向“时空结构化”的跃迁。这篇论文向我们展示了:高效的 AI 记忆不需要记住每句话,但必须精准地定位每个时间点。 对于开发者而言,在 RAG 系统中引入结构化的“事件日历”可能是提升垂直领域对话助手专业度的捷径。
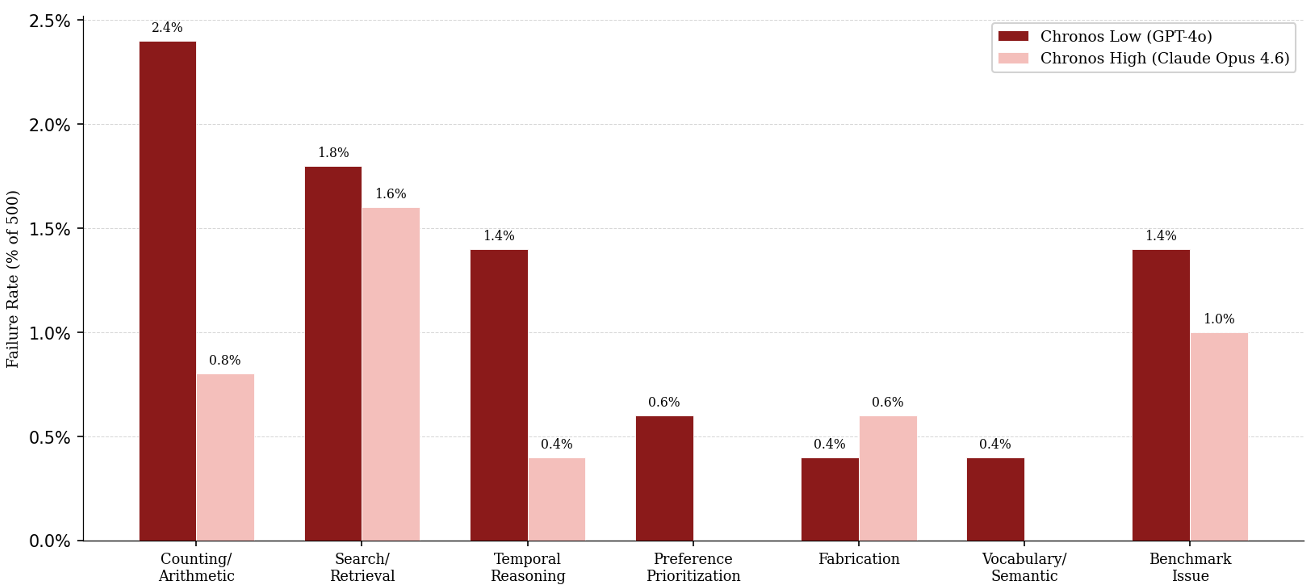 图 2:Chronos High 与 Low 的错误分类分析,显示更强的模型能显著减少计算与计数类错误。
图 2:Chronos High 与 Low 的错误分类分析,显示更强的模型能显著减少计算与计数类错误。