本文推出了 ClawBench,一个包含 153 个真实世界日常在线任务的基准测试框架,覆盖 144 个活跃平台和 15 个生活类别。该框架通过轻量级拦截机制实现在生产环境中的安全评估,填补了现有基准在“重写入、具有真实后果”任务上的评估空白。
TL;DR
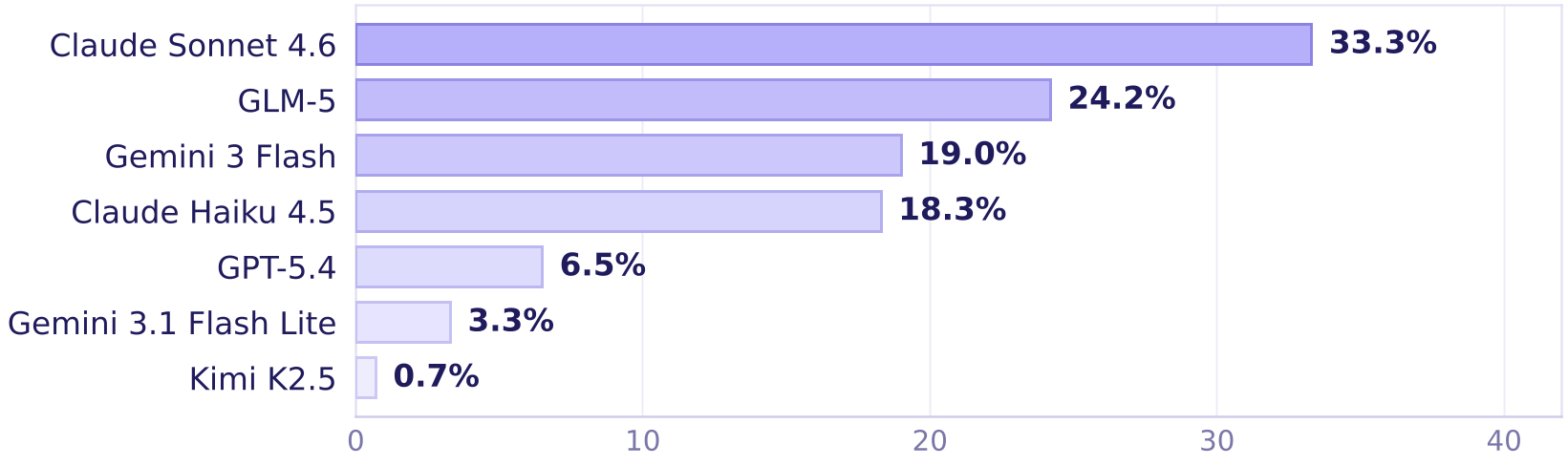
如果你认为 AI Agent 已经能够完美接管你的浏览器,那可能是因为它们还在“温室”里刷榜。本文介绍的 ClawBench 抛弃了传统的离线沙盒,直接在 144 个真实的线上平台(包括购物、求职、金融等)挑战 AI Agent。结果令人震惊:即使是最强的 Claude Sonnet 4.6,在真实世界的任务成功率也仅为 33.3%,而 GPT-5.4 更是跌破了 10%。
背景定位:从“看网页”到“办实事”
目前的 Web Agent 研究正处于一个尴尬的阶段。在 WebArena 等传统榜单上,模型似乎已经无所不能。但这些榜单实际上是“静态的标本”,缺乏真实网页的生命力。
ClawBench 的核心贡献在于它定义了 Write-heavy(重写入) 任务的重要性。AI 替你总结网页(Read-only)只是第一步,替你填好 50 个表单字段并精准点击“提交”(Write-heavy)才是通往通用助手的必经之路。
痛点深挖:为什么实验室的高分在现实中失灵?
作者指出,现有 Benchmark 存在三大缺陷:
- 环境真空化:沙盒环境没有验证码、没有动态渲染的弹窗、没有不断更新的 DOM 结构。
- 任务轻量化:大多侧重信息检索,而非改变服务器状态(State-changing)的操作。
- 评估模糊化:简单的 URL 匹配无法捕捉 Agent 在复杂表单填充中的细微错误。
核心机制:如何在不刷爆信用卡的情况下评估?
ClawBench 解决“安全”与“真实”矛盾的手段非常精巧:精准外科手术式拦截。
1. 拦截机制 (Interception Mechanism)
与其构建整个网站的副本,不如在数据发往服务器的最后一刻将其截获。系统通过人手标注每个任务的“终极 HTTP 请求”特征(URL 匹配、Payload 模式),利用 Chrome 扩展在浏览器底座直接阻断。这意味着 Agent 可以自由点击、浏览、填表,但最后的“支付”或“提交”动作被拦截并记录在案,用于评分。
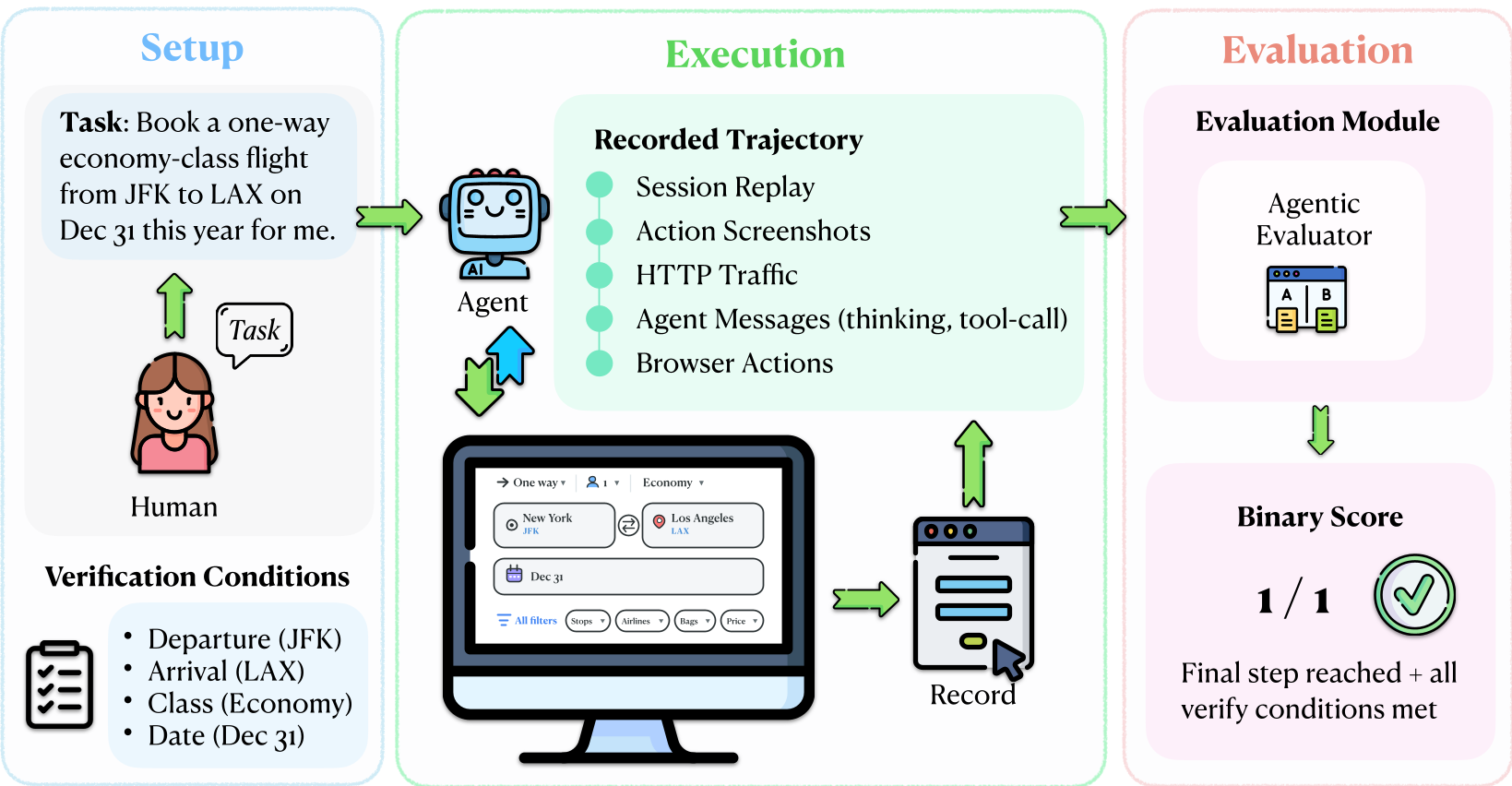
2. 五层日志与 Agentic Evaluator
为了让失败“可溯源”,ClawBench 记录了海量数据:
- Session Replay: 录屏,看 Agent 到底看到了什么。
- Action Screenshots: 每一步的快照。
- HTTP Traffic: 捕获所有网络交互。
- Agent Messages: 记录思维链(CoT)。
- Browser Actions: 底层点击和滚屏坐标。
评估时,引入一个 Agentic Evaluator (基于 Claude Code)。它不是简单看结果,而是将 Agent 的五层轨迹与人类专家的参考轨迹进行“对齐式对比”。这种 Comparative Signal(比较信号) 能精准指出:哪一个必填字段填错了?哪一步逻辑发生了偏离?
实验与结果:现实给模型的一记重锤
研究团队对 7 个前沿模型进行了大考。
| 模型 | 综合成功率 (SR) | 日常生活 | 金融 | 办公 | 开发 | | :--- | :--- | :--- | :--- | :--- | :--- | | Claude Sonnet 4.6 | 33.3 | 44.2 | 50.0 | 19.0 | 11.1 | | GLM-5 | 24.2 | 30.8 | 16.7 | 38.1 | 16.7 | | GPT-5.4 | 6.5 | 9.6 | 0.0 | 0.0 | 11.1 |
深度洞察:
- 强者恒强,但上限极低:Claude Sonnet 4.6 确实是目前最好的 Web Agent,但也只能完成三分之一的任务。
- 领域的“偏科”:有趣的是,GLM-5 在工作(Work)类别表现最好,而 Gemini 3 则在旅游(Travel)类领先。这说明目前的训练数据在不同垂直领域的分布存在失衡。
- 现实的毒打:GPT-5.4 在传统榜单与 ClawBench 之间的巨大分差(~70% vs 6.5%)再次证明,现有的实验室基准可能存在严重的过拟合。
深度探讨与总结 (Takeaway)
ClawBench 的出现宣告了 Web Agent 评估“拟真时代”的终结。它迫使开发者面对:
- Inductive Bias (归纳偏置):模型需要更强的处理复杂 DOM 和长链路表单的能力。
- Traceability (溯源性):单纯的 Pass/Fail 已经不够,我们需要更细颗粒度的错误分析。
局限性:虽然拦截机制解决了大部分安全问题,但某些网站的防御机制可能会因为检测到频繁的异常请求(即使被拦截)而封禁测试账号。此外,真实网页的快速迭代意味着 Benchmarking 维护是一个长期的人力工程。
一句话总结:AI Agent 离成为真正的“数字管家”还有很长的路要走,而 ClawBench 为这段路立下了一座极其冷峻且真实的里程碑。