本文提出了 Code-A1,一个专为代码大模型设计的对抗性强化学习协同进化框架。该方法通过将 Code LLM 和 Test LLM 解耦并设置对立目标,在没有人工标注测试集的情况下,实现了代码生成能力与单元测试生成能力的同步提升,在 Qwen2.5-Coder 基座上达到了 SOTA 水平。
TL;DR
浙江大学 REAL 团队提出的 Code-A1 框架,通过让“写代码的模型”和“写测试的模型”进行对抗:Code LLM 负责写出更强壮的代码,Test LLM 负责找茬并生成能让代码报错的边缘用例。这种“左右互搏”的进化方式,不仅摆脱了对人工昂贵标注的依赖,还让 3B 的模型在找 Bug 能力上干翻了 7B 模型。
背景定位:从“自我博弈”到“对抗共生”
在 RL 训练代码模型时,核心难题是“奖励信号(Reward)从哪来”。靠固定的人工测试集?数据太少,容易过拟合。靠模型自己写测试(Self-play)?模型很快就会学聪明——写个 assert True == True 的弱智测试,由于测试和代码是同一个模型出的,它们会通过“合谋”来骗取奖励。
Code-A1 的本质提升在于架构解耦。它明确了两个特种兵角色:
- Coder:防御者,目标是写出无可指摘的代码。
- Tester:攻击者,它可以直接“看” Coder 的代码(白盒),精准打击代码里的边界、逻辑漏洞。
痛点深挖:为什么之前的 Self-play 走不远?
传统的自我博弈面临一个悖论:
- 黑盒模式:Tester 不能看代码,只能看题目猜 Bug。结果生成的测试太宽泛,抓不住特定实现的逻辑错误。
- 白盒模式:Tester 能看代码,但因为它和 Coder 是一家人,它会故意放水,生成能轻松通过的测试。
Code-A1 通过物理隔绝两个模型,把白盒访问从“合谋工具”变成了“显微镜”,让 Tester 能够针对特定实现定制对抗样本。
核心机制:Mistake Book 与 GRPO 优化
1. 架构总览
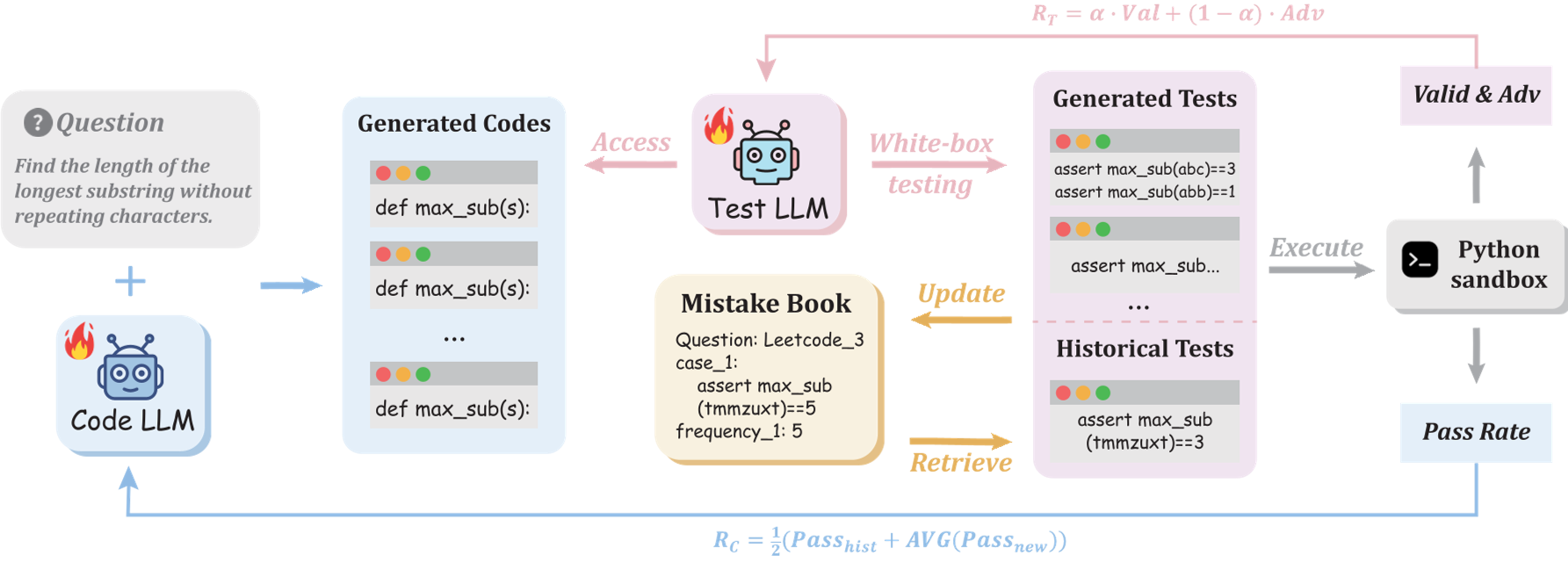 图 1:Code-A1 训练全流程,展示了白盒测试生成与错误本的动态交互过程。
图 1:Code-A1 训练全流程,展示了白盒测试生成与错误本的动态交互过程。
2. 错误本 (Mistake Book)
这不仅是一个缓存,它是模型的“记忆之光”。它记录了每个问题历史上让 Coder 翻车的所有测试用例。
- 防止退化:Coder 如果为了过新测试而把以前能跑通的代码改坏了,错误本会立刻跳出来扣分。
- 动态闭环:当 Coder 彻底掌握了某个用例,该用例会从本子里移除。
3. 奖励公式的物理直觉
- Code LLM Reward:由(历史测试通过率 + 新测试通过率)组成。
- Test LLM Reward:采用了平衡策略:。其中“对抗难度”通过计算(历史测试通过率 - 当前代码在新测试下的通过率)来得出。只要它能考倒 Coder,奖励就越高。
实验战绩:以小博大的胜利
Code-A1 在多个尺度上碾压了传统的静态测试强化学习。
 图 2:测试生成能力的对比。注意 Code-A1-3B 在 Mul 指标上达到了 15.29,显著超过了 Qwen2.5-Coder-7B 原版模型的 14.72。
图 2:测试生成能力的对比。注意 Code-A1-3B 在 Mul 指标上达到了 15.29,显著超过了 Qwen2.5-Coder-7B 原版模型的 14.72。
关键发现:
- 参数效率惊人:通过对抗训练,小参数模型可以习得比大模型更敏锐的“代码审计”直觉。
- 告别标注:使用 Code-A1 自动生成的测试去带其他的模型做 RL,效果竟然比用人工标注的测试集还要好(Avg Score 56.75 vs 56.23)。
深度洞察
Code-A1 的成功证明了:在代码这种高度结构化、有编译器作为客观真理(Oracle)的领域,对抗(Competition)比简单的模仿(SFT)更有助于触碰性能天花板。同时也揭示了一个深刻的道理:一个强大的攻击者(Tester)是培养一个伟大防御者(Coder)的先决条件。
局限与未来
虽然目前 Code-A1 在 Python 函数级生成上表现完美,但对于跨文件、有状态的极其复杂的工程代码,如何定义对抗奖励仍是个挑战。此外,该框架目前仍依赖一个 Ground Truth 代码作为最终裁判(验证有效性),未来能否通过多个弱模型的共识(Consensus)彻底摆脱对 GT 代码的依赖,是值得关注的方向。
总结 (Takeaway):Code-A1 为 LLM 的自我迭代提供了一个可落地的模板:任务解耦 + 针对性对抗 + 历史经验持久化。在合成数据质量决定模型上限的当下,这种能不断自主产生“高质量错题”的系统极具商业价值。