本文提出了 Complementary RL,一种受神经科学启发、让 Actor(策略模型)与 Experience Extractor(经验提取器)在强化学习循环中“协同演化”的新范式。通过异步训练框架,该方法在 MiniHack、WebShop 等多任务场景中显著提升了样本效率和最终成功率。
核心速览
TL;DR:阿里巴巴与香港科技大学的研究团队提出了一种名为 Complementary RL 的新框架。它解决了 Agent 在强化学习中“记不住”或“记错”经验的问题。通过让一个专门的“经验提取器”和“执行策略”同时进行强化学习,该系统实现了经验与能力的同步升级。
背景定位:这是 Agent 领域中首个将经验提取(Experience Distillation)完整融入 RL 闭环、并解决经验分布偏移(Distributional Misalignment)问题的 SOTA级 工作,处于“经验驱动型 Agent”研究的前沿。
痛点深挖:为什么你的 Agent 总是“死记硬背”?
在现有的 LLM-based Agent 训练中,我们通常面临两个极端:
- 纯 RL 训练:只看最终结果(Sparse Reward),不记录过程。Agent 就像一个不记笔记的学生,虽然在改错,但效率极低。
- 静态经验库:虽然记录了“失败/成功经验”,但这些经验是死板的。当 Agent 变强后,以前觉得有用的“新手指南”反而成了干扰(Stale Experience),甚至诱发幻觉。
作者发现,如果经验提取器不跟着 Actor 一起变聪明,代理的性能提升很快就会遇到瓶颈。
方法论详解:协同演化的“双螺旋”
1. 神经科学的直觉:CLS 系统
受人类大脑 互补学习系统 (Complementary Learning Systems, CLS) 的启发,本文构建了两个模型:
- Actor ():模拟新皮层,形成结构化的长期策略(干活的)。
- Extractor ():模拟海马体,管理快速的、特定回合的记忆(复盘的)。
2. 核心机制:为“经验”发奖励
这是本文最精妙的地方。Extractor 产生的“经验条目 ”好不好,不是看它写得顺不顺,而是看它是否帮助 Actor 赢得了比赛:
- Actor 的奖励:环境给的二进制成功/失败信号。
- Extractor 的奖励:如果 Actor 靠你的建议赢了,给你 ;输了给你 。
3. 异步训练架构
为了不让“写笔记”耽误“干活”,团队设计了一个全异步的分布式架构。
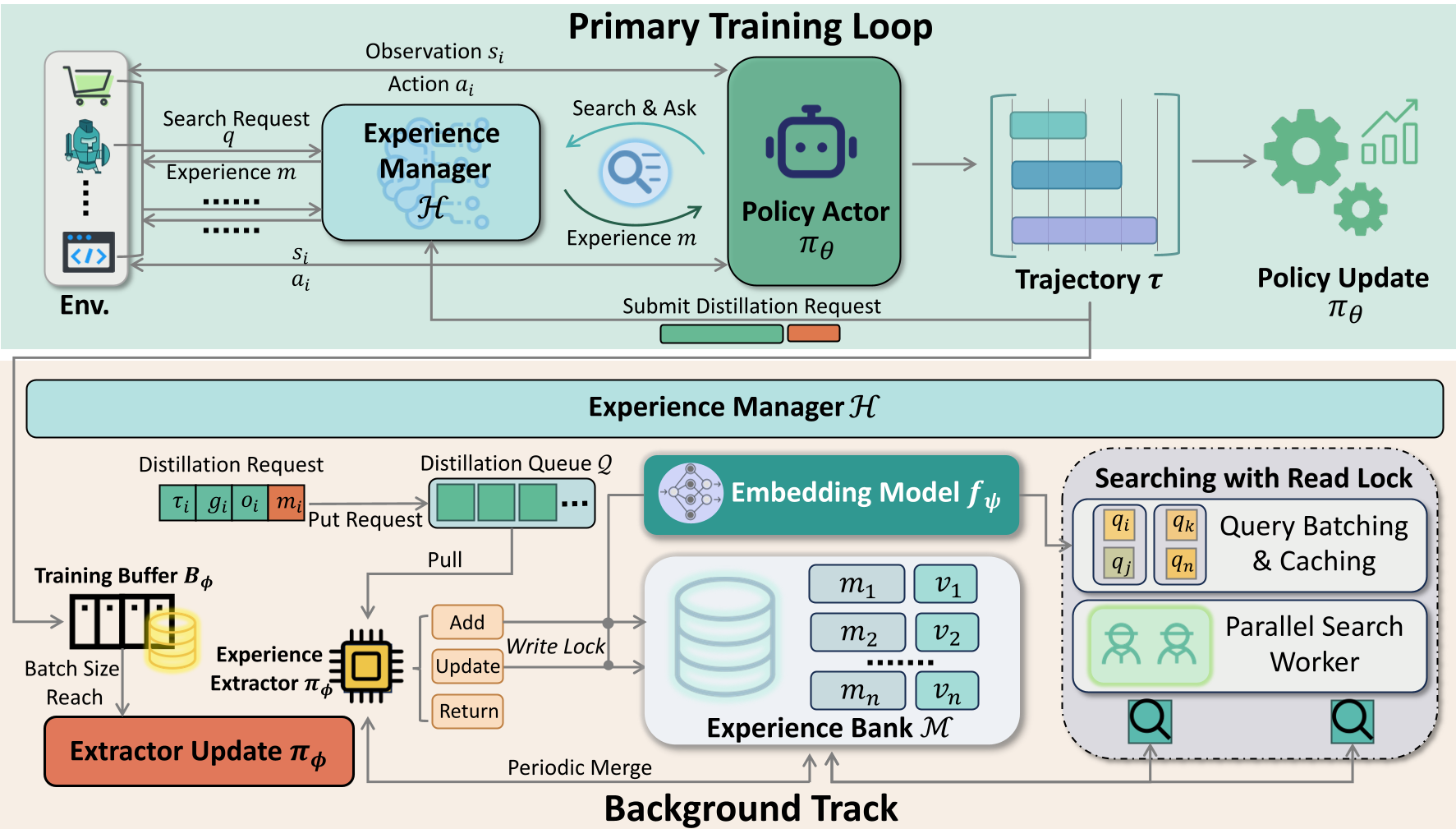
- ExperienceManager:充当中央调度员,负责经验的语义检索(Search)、冲突合并(Merge)和定期清理,确保经验库的精简与高效。
实验与结果:不仅变强了,还得变快了
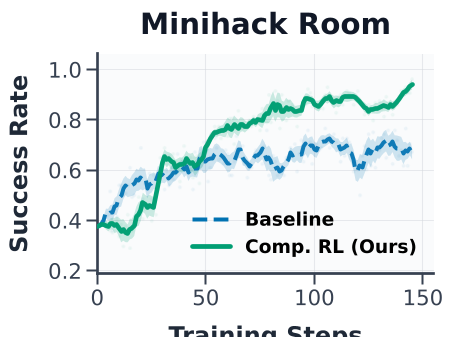
研究人员在 MiniHack (迷宫导航)、WebShop (购物) 和 SWE-Bench (工程修 Bug) 等多个极具挑战性的环境上进行了测试。
1. 性能全线突破
在单任务场景下,Complementary RL 比传统的、不带经验的 RL 强出了一大截。
2. 交互效率翻倍
最令人惊喜的是,有了高质量经验引导后,Agent 的废话和废动作明显减少。在 MiniHack 中,Agent 达到目标所需的动作减少了 1.5 倍,而在 ALFWorld 中更是减少了 2 倍。
深度洞察:为什么这种“内卷”有效?
通过消融实验,作者揭示了一个真相:如果你只给 Agent 喂静态经验,它会产生过度依赖(Over-reliance)。
本文通过 Split-subgroup 优势估计 解决了这个问题。他们将 Rollout 分成“有经验引导”和“无经验引导”两组并行训练,并强制要求两组各自计算优势函数(Advantage)。这就像让学生在“开卷考试”和“闭卷考试”中平衡,最终迫使 Actor 将外部经验转化为内在的推理能力。
总结与展望
Takeaway:Complementary RL 证明了——最好的老师(Extractor)是由学生(Actor)的反馈教出来的。
局限性:尽管框架很强,但在集成“自我蒸馏(Self-Distillation)”时会出现训练后期的崩塌,这提示我们在极长周期的自我进化中,正则化与超参控制仍是巨大的挑战。
未来展望:这种“模型教模型、同步进化”的模式,未来很可能被应用到多模态具身智能(如机器人控制)中,让机器人能动态地从过去的失误中提炼出通用的操作物理法则。