The paper introduces a theoretical framework modeling Human Mathematics (HM) as a highly compressible subset of Formal Mathematics (FM). Using monoid theory and empirical analysis of the Lean 4 MathLib library, the authors demonstrate that HM is distinguished by a hierarchical "macro" structure that enables exponential expansion of expressivity.
TL;DR
Why do we care about some theorems while others—equally "true"—feel like useless logical noise? This paper argues that Human Mathematics (HM) is defined by its compressibility. By modeling math using monoids and analyzing the Lean 4 MathLib, the authors prove that our math lives in a rare, "soft" region where hierarchical definitions allow us to represent $10^{104}$ primitive operations with just a few hundred tokens.
The Problem: The Infinite Haystack of Truth
Formal Mathematics (FM) is the set of every possible valid deduction. It is an exponentially growing, entropic wilderness. Most of it is "incompressible"—random-looking strings of logic that lead nowhere of value. The authors argue that humans have a "laziness" bias: we look for landmarks. We invent definitions (macros) to skip over the boring parts.
The central mystery is: What is the mathematical structure of these landmarks?
Methodology: Math as a Monoid
The authors simplify mathematics into "words" in a monoid.
- Generators ($G$): Primitive axioms or core logic.
- Macros ($M$): Definitions, lemmas, and theorems that stand in for longer strings of $G$.
- Unwrapped Length ($|w|_G$): The total number of primitive symbols once all definitions are expanded.
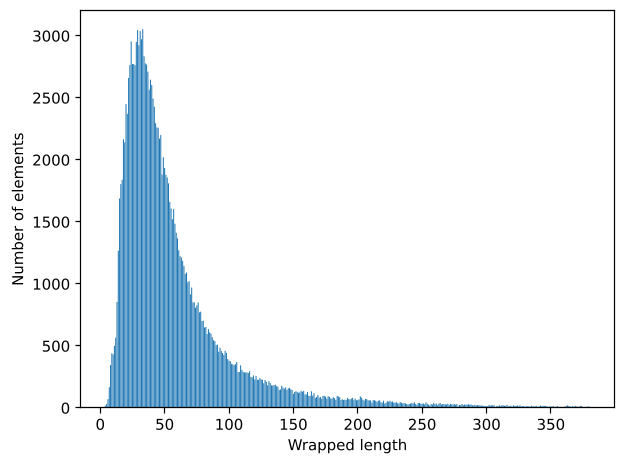
- Wrapped Length ($|w|_{G'}$): The "token count" or human-readable length of a definition.
They contrast two worlds:
- Abelian Monoids ($A_n$): Where logic "commutes." Here, a tiny number of macros leads to exponential expansion (like place notation in decimal systems).
- Non-Abelian Monoids ($F_n$): Where order is rigid. Here, compression is much harder; you need an exponential number of macros just to get linear expansion.

Empirical Evidence from MathLib
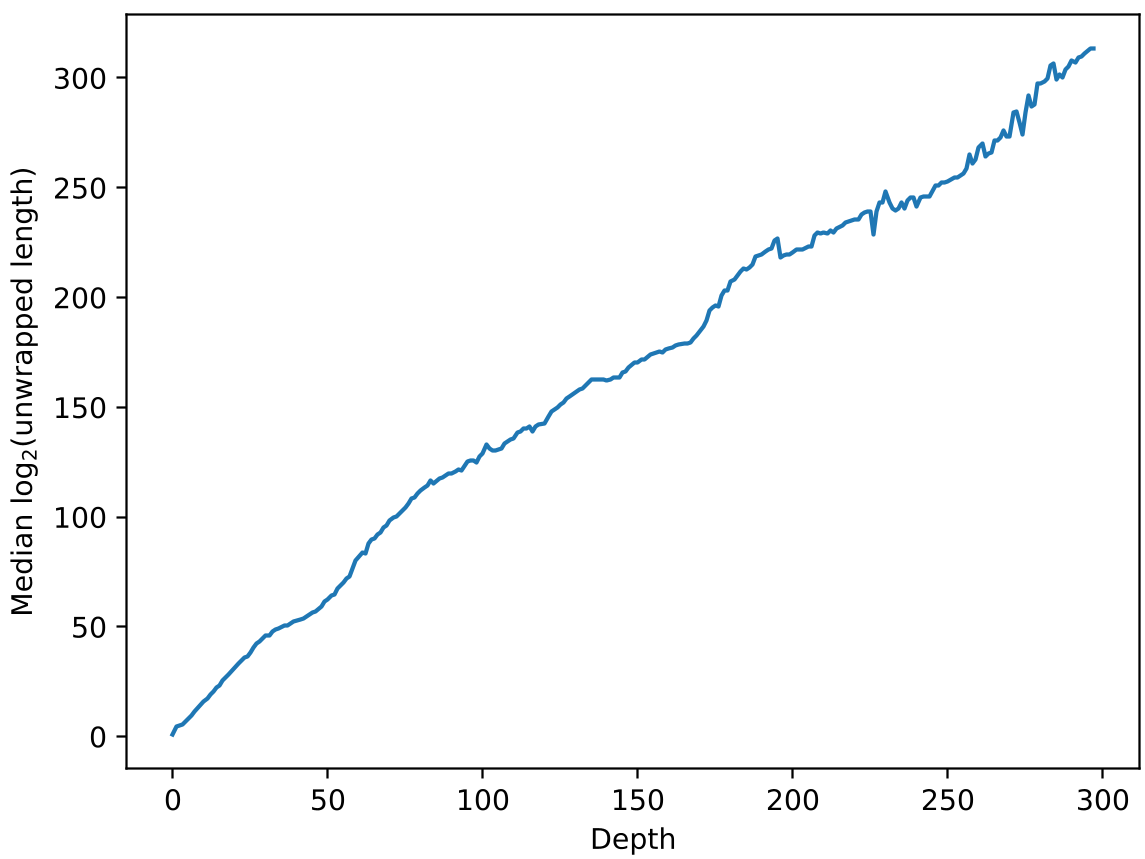
Testing this against the Lean 4 library, the authors found a staggering reality. Human math behaves exactly like the "Log-density $A_n$" model.
Key Metrics:
- Exponential Growth with Depth: As theorems build on deeper lemmas, their "true" size (unwrapped length) explodes.
- The constant "Human Scale": Regardless of how deep a theorem is, the length of its code (wrapped length) stays roughly the same. This suggests humans modularize concepts specifically to keep them within cognitive limits (50–120 tokens).
The result is a "Google-sized" expansion: The most complex entries in MathLib expand to a Googol ($10^{100}$) of primitive logic steps.
Critical Insight: Defining "Mathematical Interest"
The paper doesn't just theorize; it offers a way to program mathematical taste into AI.
- Reductive Compression ($T_0$): High "Taste." The ratio of how much a theorem hides its complexity.
- Deductive Compression ($I_0$): High "Interest." How short a statement is compared to how long its proof is.
By combining these with a biased PageRank algorithm, the authors suggest we can rank theorems not just by how many things cite them, but by how much "load" they bear in the hierarchy of complexity.
Future Outlook: The AI Mathematician
Current LLMs struggle with math because they don't know where to look. If we bias AI agents to prefer compressible regions, we might finally move past "stochastic parrots" and toward agents that discover "beautiful" and "human" mathematics.
However, the paper admits a massive hurdle: How do we find the "optimal" definitions? Building the macro set is as hard as doing the math itself. But now, at least, we have a metric to know when we are getting closer to the "Soft and Squishy" heart of human logic.