本文提出当前智能体记忆系统(RAG, MemGPT 等)本质上仅是“查表(Lookup)”而非真正的“记忆”。作者通过证明“泛化间隙定理”指出,依赖检索的方法在处理组合创新任务时存在物理上限,并倡导建立从外部存储向模型权重转化的“巩固通道(Consolidation Channel)”。
TL;DR
目前的 AI 智能体(Agent)其实都患有“书呆子症”:它们拥有完美的 RAG(检索增强生成)笔记系统,却完全没有“内化”知识的能力。本文指出,检索(Retrieval)不等于记忆(Memory)。如果一个智能体只靠查找外部数据库来工作,它永远无法在未见过的复杂任务上产生真正的专业直觉。作者呼吁:智能体需要“睡眠”来将外部笔记转化为内部权重。
背景定位
在 Agent 领域,无论是 MemGPT、Voyager 还是 Reflexion,大家都默认了一个假设:外部存储越丰富,智能体就越聪明。本文一针见血地指出:这在数学上是错误的。这不仅是一篇技术论文,更是对当前 Agent 架构范式的挑战书。
1. 痛点:为什么 RAG 无法产生“专家”?
作者提出了一个深刻的类比:“新手看表面,专家看本质”。
- 新手(检索驱动):遇到物理题,在笔记本里搜“斜面问题”,然后模仿之前的步骤。
- 专家(权重驱动):遇到问题,直接提取内在的“能量守恒定律”,无论题目描述多花哨,其推理逻辑是内化的。
目前的智能体即使积累了上万条自我反思(Reflexion),其底层模型权重(θ)依然是冻结的。这种“冻结的新手”面临三个致命问题:
- 组合泛化天花板:无法处理从未见过的概念组合。
- 能力停滞:笔记再多,推理能力也受限于基座模型。
- 安全漏洞:一旦外部存储被注入恶意指令,这些指令会像毒素一样在未来的所有会话中持续生效。
2. 核心贡献:泛化间隙定理(Generalization Gap)
这是本文最具冲击力的数学证明。作者对比了改变上下文(Change C)和改变权重(Change θ)的样本复杂度:

- 定理结论:对于一个包含 个概念的领域,检索系统要覆盖所有可能的组合,需要的存储量是 ;而参数化学习通过提取抽象规则,只需要 的样本( 为维数,远小于 )。
- 物理直觉:检索是在“填空”,只有存过的点才能答对;而改变权重是在“学函数”,即便没见过的输入也能算出正确的输出。
3. 架构方案:建立巩固通道 (Consolidation Channel)
受生物学中“海马体(短期存储)→ 新皮质(长期稳固)”的启发,作者提出了一种“协同架构”:
(注:建议参考论文中提到的离线细调流程)
设计原则:
- Agentic Memory 仅作为临时缓存:用于存储最近的工具输出和对话细节。
- 异步巩固:智能体在“睡眠”期间,将高价值的经验通过 LoRA、知识编辑(MEMIT)或自蒸馏的方式更新到 θ 中。
- 版本化审计:权重更新是可回滚的,这比清理无穷无尽的外部向量库更安全。
4. 实验与证据
论文引用了多项研究来支持这一论点:
- SOTA 对比:在多跳查询任务中,Fine-tuning 提升的效果系统性地优于 RAG。
- 消融视角:单纯增加上下文长度(Context Window)并不能解决组合逻辑预测失败的问题,这证明了“大口袋不等于好脑子”。
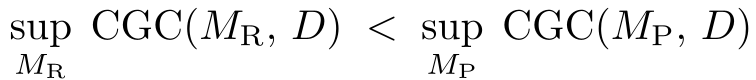
5. 深度洞察:对未来的启示
这篇文章标志着 Agent 研究从“工程补丁时代”向“认知科学融合时代”的转型。
- 对开发者:别再执着于更高效的向量检索了,去研究如何稳定地进行“持续学习(Continual Learning)”吧。
- 对评测者:现有的榜单(如 LongBench)只考查找回能力,未来的榜单应该考查 CGT(随时间推移的组合泛化)——即 Agent 是否在运行 100 轮后比第 1 轮更聪明?
总结: 智能体需要的是真正的“内化”,而不仅仅是随身带一支笔。如果θ不动,智能体终究只是一个拿着厚厚笔记的手写版模型。